Am fost întrebat recent de un coleg de-al meu cum să extrag varianța dintr-un model estimat folosind adam() funcția de la smooth pachet în R. Problema a fost că acea persoană a început să citească codul sursă al forecast.adam() și m-am pierdut printre rânduri (așa mi se întâmplă și mie uneori). Ei bine, există o soluție mai ușoară, iar în acest post vreau să rezumam câteva metode pe care le-am implementat în smooth pachet pentru funcții de prognoză. În această postare mă voi concentra pe adam() funcţionează, deşi toate lucrează pentru es() şi msarima() de asemenea, iar unele dintre ele funcționează pentru alte funcții (cel puțin ca acum, pentru v4.1.0 fluid). De asemenea, unele dintre ele sunt menționate în fișa Cheat sheet pentru funcția adam() a monografiei mele (disponibilă online).
Înainte de a începe, am un scurt anunț. Eu și Kandrika Pritularga plănuim să găzduim primul curs online despre „Prognoza cererii cu R” în noiembrie 2025. Mai sunt câteva locuri, așa că vă puteți înscrie prin magazinul Universității Lancaster. Despre curs puteți citi aici.
Principalele metode
The adam clasa acceptă mai multe metode care sunt utilizate în alte pachete din R (de exemplu, pentru lm clasă). Iată-le:
forecast()şipredict()– produce previziuni din model. Primul este de preferat, cel din urmă are o funcționalitate puțin limitată. Consultați documentația pentru a vedea ce prognoze pot fi generate. Acest lucru a fost discutat și în capitolul 18 al monografiei mele.fitted()– extrage valorile ajustate din obiectul estimat;residuals()– extrage reziduurile modelului. Acestea sunt valori ale lui (e_t), care diferă în funcție de tipul de eroare al modelului (vezi discuția aici);rstandard()– returnează reziduurile standardizate, adică reziduurile împărțite la abaterea lor standard;rstudent()– reziduuri studentizate, adică reziduuri care sunt împărțite la abaterea lor standard, scăzând impactul fiecărei observații specifice asupra acesteia. Acest lucru ajută în cazul valorilor aberante influente.
O metodă suplimentară a fost introdusă în greybox pachet, numit actuals()care permite extragerea valorilor reale ale variabilei răspuns. O altă metodă utilă este accuracy()care returnează un set de măsuri de eroare folosind measures() funcția de greybox pachet pentru modelul furnizat și valorile holdout.
Toate metodele de mai sus pot fi utilizate pentru diagnosticarea modelului și pentru prognoză (scopul principal al pachetului). Mai mult, cel adam clasa suportă mai multe funcții pentru lucrul cu coeficienții modelelor, similar cu modul în care se face în cazul lm:
coef()saucoefficient()– extrage toți coeficienții estimați în model;vcov()– extrage matricea de covarianță a parametrilor. Acest lucru se poate face fie folosind informațiile Fisher, fie printr-un bootstrap (bootstrap=TRUE). În acest din urmă caz,coefbootstrap()metoda este utilizată pentru a crea serii de timp bootstrapped, reaplica modelul și extrage estimări ale parametrilor;confint()– returnează intervalele de încredere pentru parametrul estimat. Se bazează pevcov()și asumarea normalității (CLT);summary()– returnează rezultatul modelului, care conține tabelul cu parametrii estimați, erorile standard ale acestora și intervalele de încredere.
Iată un exemplu de ieșire dintr-un ADAM ETS estimat folosind adam():
adamETSBJ <- adam(BJsales, h=10, holdout=TRUE) summary(adamETSBJ, level=0.99)
Prima linie de mai sus estimează și selectează cel mai potrivit ETS pentru date, în timp ce al doilea va crea un rezumat cu intervale de încredere de 99%, care ar trebui să arate astfel:
Model estimated using adam() function: ETS(AAdN)
Response variable: BJsales
Distribution used in the estimation: Normal
Loss function type: likelihood; Loss function value: 241.1634
Coefficients:
Estimate Std. Error Lower 0.5% Upper 99.5%
alpha 0.8251 0.1975 0.3089 1.0000 *
beta 0.4780 0.3979 0.0000 0.8251
phi 0.7823 0.2388 0.1584 1.0000 *
level 199.9314 3.6753 190.3279 209.5236 *
trend 0.2178 2.8416 -7.2073 7.6340
Error standard deviation: 1.3848
Sample size: 140
Number of estimated parameters: 6
Number of degrees of freedom: 134
Information criteria:
AIC AICc BIC BICc
494.3268 494.9584 511.9767 513.5372
Cum să citiți această ieșire este discutat în Secțiunea 16.3.
Erori de prognoză în mai mulți pași
Există două metode care pot fi utilizate ca instrumente analitice suplimentare pentru modelul estimat. Genericele lor sunt implementate în smooth pachetul în sine:
rmultistep()– extrage mai mulți pași înainte erorile de prognoză din eșantion pentru orizontul specificat. Aceasta înseamnă că modelul produce prognoza lungimiihpentru fiecare observație începând de la prima, până la ultima și apoi calculează erorile de prognoză pe baza acesteia. Acesta este utilizat în cazul intervalelor de predicție semiparametrice și neparametrice, dar poate fi folosit și pentru diagnosticare (vezi, de exemplu, Subsecțiunea 14.7.3);multicov()– returnează matricea de covarianță a erorii de prognoză h pași înainte. Diagonala acestei matrice corespunde varianței h pași înainte condiționate de informațiile din eșantion.
Pentru același model pe care l-am folosit în secțiunea anterioară, putem extrage și reprezenta grafic erorile în mai mulți pași:
rmultistep(adamETSBJ, h=10) |> boxplot() abline(h=0, col="red2", lwd=2)
care va avea ca rezultat:
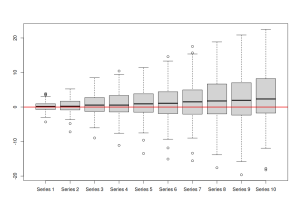
Distribuția erorilor de prognoză în mai mulți pași
Imaginea de mai sus arată că modelul tinde să depășească valorile reale din eșantion (deoarece boxploturile tind să se afle puțin deasupra liniei zero). Acest lucru ar putea cauza o părtinire în prognozele finale.
Matricea de covarianță a erorii de prognoză în mai mulți pași arată astfel în cazul nostru:
multicov(adamETSBJ, h=10) |> round(3)
h1 h2 h3 h4 h5 h6 h7 h8 h9 h10
h1 1.918 2.299 2.860 3.299 3.643 3.911 4.121 4.286 4.414 4.515
h2 2.299 4.675 5.729 6.817 7.667 8.333 8.853 9.260 9.579 9.828
h3 2.860 5.729 8.942 10.651 12.250 13.501 14.480 15.246 15.845 16.314
h4 3.299 6.817 10.651 14.618 16.918 18.979 20.592 21.854 22.841 23.613
h5 3.643 7.667 12.250 16.918 21.538 24.348 26.808 28.733 30.239 31.417
h6 3.911 8.333 13.501 18.979 24.348 29.515 32.753 35.549 37.737 39.448
h7 4.121 8.853 14.480 20.592 26.808 32.753 38.372 41.964 45.036 47.440
h8 4.286 9.260 15.246 21.854 28.733 35.549 41.964 47.950 51.830 55.127
h9 4.414 9.579 15.845 22.841 30.239 37.737 45.036 51.830 58.112 62.223
h10 4.515 9.828 16.314 23.613 31.417 39.448 47.440 55.127 62.223 68.742
Acest lucru nu este util în sine, dar poate fi folosit pentru unele derivații ulterioare.
Rețineți că valorile returnate de ambele rmultistep() şi multicov() depinde de tipul de eroare al modelului (a se vedea secțiunea 11.2 pentru clarificări).
Diagnosticarea modelului
Cea convențională plot() metoda aplicata unui model estimat folosind adam() poate produce o varietate de imagini pentru diagnosticarea modelului vizual. Aceasta este controlată de which parametru (în total, 16 opțiuni). Documentația de plot.smooth() conține lista exhaustivă de opțiuni, iar Capitolul 14 al monografiei arată cum acestea pot fi utilizate pentru diagnosticarea modelului. Aici am enumerat doar câteva dintre cele principale:
plot(ourModel, which=1)– valori reale vs valori ajustate. Poate fi folosit pentru diagnosticarea generală a modelului. În mod ideal, toate punctele ar trebui să se afle în jurul liniei diagonale;plot(ourModel, which=2)– reziduuri standardizate vs valori ajustate. Util pentru detectarea potențialelor valori aberante. De asemenea, acceptălevelparametru, care reglează lățimea limitelor de încredere.plot(ourModel, which=4)– reziduuri absolute vs ajustate, care pot fi utilizate pentru detectarea heteroscedasticității reziduurilor;plot(ourModel, which=6)– Diagrama QQ pentru analiza distribuției reziduurilor. Cifra specifică se modifică pentru distribuția diferită presupusă în model (a se vedea Secțiunea 11.1 pentru cele acceptate);plot(ourModel, which=7)– reale, valori ajustate și prognoze punctuale în timp. Util pentru înțelegerea modului în care modelul se potrivește cu datele și în ce punct de prognoză produce;plot(ourModel, which=c(10,11))– ACF și PACF ale reziduurilor modelului pentru a detecta eventualele elemente AR/MA lipsă;plot(ourModel, which=12)– graficul componentelor modelului. În cazul ETS, va afișa descompunerea seriei temporale pe baza acesteia.
Și iată patru diagrame implicite pentru modelul pe care l-am estimat mai devreme:
par(mfcol=c(2,2)) plot(adamETSBJ)

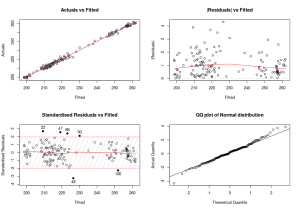
Diagrame de diagnostic pentru modelul estimat
Pe baza graficului de mai sus, putem concluziona că modelul se potrivește bine datelor, nu are heteroscedasticitate aparentă, dar are mai multe valori aberante potențiale, care pot fi explorate pentru a-l îmbunătăți. Detectarea valorii aberante se face prin intermediul outlierdummy() metoda, al cărei generic este implementat în greybox pachet.
Alte metode utile
Există multe metode care sunt folosite de funcții pentru a extrage unele informații despre model. Uneori le folosesc pentru a-mi simplifica rutina de codare. Iată-le:
lags()– returnează decalaje ale modelului. Mai ales util dacă vă potriviți un model de sezon multiplu;orders()– vectorul comenzilor modelului. Util în principal în cazul ARIMA, care poate avea mai multe sezonieri și comenzi p,d,q,P,D,Q;modelType()– tipul modelului. În cazul în care cea montată mai sus va returna „AAdN”. Poate fi util pentru a remonta cu ușurință modelul similar pe noile date;modelName()– denumirea modelului. În cazul celui pe care l-am montat mai sus va returna „ETS(AAdN)”;nobs(),nparam(),nvariate()– numărul de observații în eșantion, numărul tuturor parametrilor estimați și, respectiv, numărul de serii temporale utilizate în model. Acesta din urmă este dezvoltat în principal pentru modelele multivariate, cum ar fi VAR și VETS (de exlegionpachet în R);logLik()– extrage log-probabilitatea modelului;AIC(),AICc(),BIC(),BICc()– extrage criteriile de informare respective;sigma()– returnează eroarea standard a reziduurilor.
Metode mai specializate
Una dintre metodele care poate fi utilă pentru scenarii și generarea de date artificiale este simulate(). Acesta va lua structura și parametrii modelului estimat și îi va folosi pentru a genera serii de timp, similare cu cea inițială. Acest lucru este discutat în Secțiunea 16.1 a monografiei ADAM.
În plus, smooth implementează modelul la scară, discutat în Capitolul 17, care permite modelarea în timp variind la scară de distribuție. Acest lucru se face prin intermediul sm() metoda (generică introdusă în greybox pachet), a cărui ieșire poate fi apoi fuzionată cu modelul original prin intermediul implant() metodă.
Pentru același model pe care l-am folosit mai devreme, modelul la scară poate fi estimat astfel:
adamETSBJSM <- sm(adamETSBJ)
Așa arată:
plot(adamETSBJSM, 7)
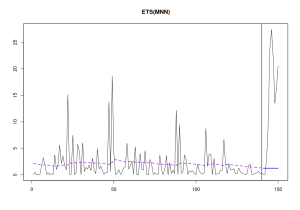
Model la scară pentru ADAM ETS
În graficul de mai sus, axa y conține reziduurile la pătrat. Faptul că eșantionul de reținere conține o creștere mare a erorii este de așteptat, deoarece acea parte corespunde mai degrabă erorilor de prognoză decât reziduurilor. Se adaugă la complot pentru completare.
Pentru a utiliza modelul la scară în prognoză, ar trebui să-l implantăm în locație, ceea ce se poate face folosind următoarea comandă:
adamETSBJFull <- implant(location=adamETSBJ, scale=adamETSBJSM)
Modelul rezultat va avea mai puține grade de libertate (deoarece modelul la scară a estimat doi parametri), dar intervalul său de predicție va lua acum în considerare modelul la scară și va diferi de cel original. Vom lua acum în considerare variația care variază în timp pe baza informațiilor mai recente în loc de cea medie pe întreaga serie de timp. În cazul nostru, varianța prognozată este mai mică decât cea pe care am obține-o în cazul modelului adamETSBJ. Acest lucru duce la un interval de predicție mai îngust (le puteți produce pentru ambele modele și puteți compara):
forecast(adamETSBJFull, h=10, interval="prediction") |> plot()
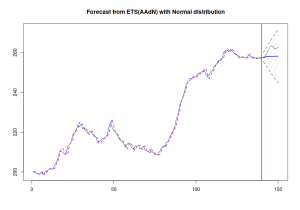
Prognoza din ADAM complet, care conține atât locație, cât și părți la scară
Concluzii
Metodele discutate mai sus oferă un pic de flexibilitate în ceea ce privește modul de modelare a lucrurilor și ce instrumente să folosească. Sper că acest lucru vă va face viața mai ușoară și că nu va trebui să petreceți timp citind codul sursă, ci să vă puteți concentra pe prognoză și analiză cu ADAM.
Metodele de mesaje pentru funcțiile fluide din R au apărut pentru prima dată pe Open Forecasting.