(Acest articol a fost publicat pentru prima dată pe Om de știință nebun (de date).și cu amabilitate a contribuit la R-bloggeri). (Puteți raporta problema legată de conținutul acestei pagini aici)
Doriți să vă distribuiți conținutul pe R-bloggeri? dați clic aici dacă aveți un blog, sau aici dacă nu aveți.
Am adăugat o nouă funcție la qeML 1.2, qeMittalGraphbazat pe o idee a elevei mele Aditya Mittal. Mai jos este un exemplu care cred că este destul de convingător.
Ideea de bază este destul de simplă (și nu neapărat nouă, doar ceva ce nu văzusem mai jos): în loc să comparați mai multe curbe direct, graficați creșterea lor din valoarea lor de bază inițială. Deci, dacă, de exemplu, X este timpul, atunci toate curbele încep de la punctul comun X = 0, Y = 1. Vizualizarea curbelor în acest mod poate face comparația mai perspicace.
Ca exemplu, vom folosi valută set de date inclus în qeML, constând din date privind cinci monede europene pre-UE.
> data(currency) > head(currency) Can..dollar Ger..mark Fr..franc UK.pound J..yen 1 19 580 4.763 29 602 2 18 609 4.818 44 609 3 20 618 4.806 66 613 4 46 635 4.825 79 607 5 42 631 4.796 77 611 6 45 635 4.818 74 610 curr <- cbind(1:nrow(currency),currency) names(curr)(1) <- 'weeknum'
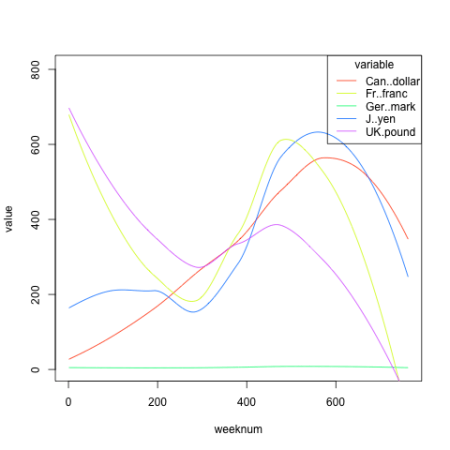
OK, haideți să graficăm valorile brute:
z <- reshape2::melt(curr,id.vars="weeknum") qePlotCurves(z,1,3,2)
Acum cu qeMittalGraph:
qeMittalGraph(curr,'weeknum','rate','country')
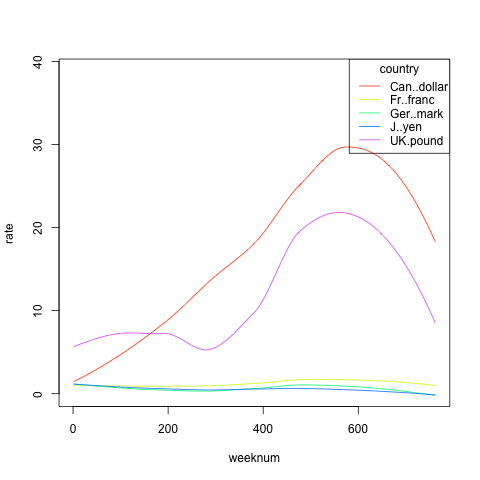
Vedem imediat două grupuri, franc/mark/yen și Cdolar/liră, potențial o perspectivă semnificativă. S-ar putea să fie nevoie de un anumit context economic, dar în mod clar acest punct de vedere ar putea fi de mare interes.
Rețineți că opțiunea de netezire „loess” este implicită, ceea ce a dus la ca una dintre curbe să nu treacă prin (0,1). Setarea acestei opțiuni la FALSE ar rezolva acest lucru, dar cu costul de a avea curbe zimțate.
O altă clasă de cazuri de utilizare este reprezentarea grafică a efectului unui hiperparametru, să zicem reprezentarea grafică a efectului dimensiunii minime a frunzei X în pădurile aleatorii, pe mai multe seturi de date diferite, cu Y = Eroare medie absolută de predicție.