(Acest articol a fost publicat pentru prima dată pe Rstats – cuantificatși cu amabilitate a contribuit la R-bloggeri). (Puteți raporta problema legată de conținutul acestei pagini aici)
Doriți să vă distribuiți conținutul pe R-bloggeri? dați clic aici dacă aveți un blog, sau aici dacă nu aveți.
Cum putem preda „R pentru biologi celulari” mai degrabă decât să predăm R la biologi celulari?
Am observat că multe cursuri de pregătire R vor preda R – indiferent de cine urmează cursul – și lasă participanților să-și dea seama cum pot folosi R în propria disciplină. Adesea, oamenii din laboratorul meu vor urma un curs R și vor petrece o jumătate de zi făcând niște parcele ale iris set de date sau calcularea milelor pe galon folosind mtcars. Odată ce părăsesc camera, le este greu să conecteze ceea ce au învățat la un caz de utilizare real în laborator. Aceasta nu este o critică la adresa acelor cursuri, am desfășurat un astfel de atelier, dar întrebarea este cum îi putem împuternici biologilor celulari (sau altor oameni de știință din laboratorul umed) să folosească R pentru munca lor?
Introducere
Trebuie introduse trei concepte:
1. de ce folosim R mai degrabă decât Microsoft Excel
Accentuați reproductibilitatea, automatizarea și grafica de calitate publicării.
2. calea de la experiment la figură
Un experiment tipic implică configurarea celulelor, imaginea lor la microscop, analiza imaginilor din Fiji, iar rezultatul analizei este fișiere text simplu, câte unul pentru fiecare imagine.
Pentru a realiza o figură, trebuie să procesăm toate aceste fișiere text și să le transformăm în figuri de calitate publică, folosind R.
3. pașii din R sunt întotdeauna aceiași
Avem nevoie să:
- Citiți în date
- Faceți niște calcule sau procesări (opțional)
- Faceți niște comploturi
În plus…
În funcție de experiența grupului, pot fi necesare introducerea altor concepte:
- RStudio ca IDE (la ce sunt diferitele panouri)
- R ca limbă
- elementele de bază ale scripturilor
- Limbi bazate pe 1 vs. limbi bazate pe 0
- baza R, tidyverse, pachete
Partea practică
Înainte de a aborda pașii 1-3 ai unei analize R, avem un pas 0 care este să configurați un proiect R să funcționeze reproductibil.
0. R Configurarea proiectului
- Porniți un nou proiect în RStudio: Fișier > Proiect nou… apoi Director nou, denumiți proiectul (sugestie: training_aammzz) și salvați undeva pe computer.
- Rulați scriptul
00_r_project_setup.Rsau lipiți această idee în consolă și apăsați Enter. - Folosind materialele cursului, mutați sau copiați scripturile în
Script/iar fișierele de date înData/
Concept cheie: o structură de directoare standardizată în folderul R Project ne ajută să procesăm cu ușurință datele și să salvăm rezultatele într-un loc standardizat.
Concept cheie: Folosim întotdeauna folderul R Project ca director de lucru.
Face proiectul portabil și nu se bazează pe căile către folderele de pe un anumit computer.
Provocări către succes: scopul este de a determina participanții să realizeze rapid un grafic al datelor. Dacă pașii de configurare și importul de date durează prea mult, participanții se pot pierde, așa că ceasul bate…
Pașii 1-3 executa scriptul 02_training.R linie cu linie (cmd + Enter pe Mac; ctrl + Enter pe Windows/Linux), explicând ce face fiecare linie pe parcurs.
Verificați înțelegerea pe tot parcursul.
1. Citiți datele
Scop: creați un cadru de date care să conțină toate datele
- Începeți prin a citi un fișier într-un cadru de date, explicați că avem 80 de fișiere de citit.
- Arată cum le putem citi pe toate într-un singur cadru de date uriaș folosind o comandă simplă
- Dar de unde știm care rânduri aparțin cărei condiții și/sau care se repetă experimental?
- Utilizați numele fișierului pentru a adăuga informații pe măsură ce acestea sunt citite.
## 1. Load data ----
# read one csv file into R as an object called temp
temp <- read.csv("Data/control_n1_1.csv")
# have a look at it
View(temp)
# remove the object
rm(temp)
# we want to load all files, so we need to get a list of all files
list.files("Data")
# assign this list as an object
filelist <- list.files("Data")
# use the path to the file
filelist <- list.files("Data", full.names = TRUE)
# load all files and rbind into big dataframe
df <- do.call(rbind, lapply(filelist, read.csv))
View(df)
# load all files and rbind into big dataframe, add a column to each file to identify each file
df <- do.call(rbind, lapply(filelist, function(x) {temp <- read.csv(x); temp$file <- x; temp}))
# this can be written on multiple lines
df <- do.call(rbind, lapply(filelist, function(x) {
temp <- read.csv(x)
temp$file <- x
temp
}))
# this is close to what we want but remember that we used full paths to load the files, we only want the file name
# we can use the basename function to extract the file name
df <- do.call(rbind, lapply(filelist, function(x) {
temp <- read.csv(x);
temp$file <- basename(x);
temp
}))
# file column has name of the file, name is of the form foo_bar_1.csv, extract foo and bar into two columns
df$cond <- sapply(strsplit(df$file, "_"), "(", 1)
df$expt <- sapply(strsplit(df$file, "_"), "(", 2)
# explain why the above works
# strsplit(df$file, "_") returns a list of vectors, each vector is the result of splitting the string by "_"
# we can extract the first element of each vector using "(", 1
# we can extract the second element of each vector using "(", 2
# sapply applies the function to each element of the list
# what does "(" do? it extracts elements from a vector
# what does "((" do? it extracts elements from a list
O ilustrație cu tablă albă poate fi folosită pentru a arăta participanților cum funcționează importul a 1 sau 80 de fișiere. Poate fi util să vizualizăm modul în care adăugăm coloane suplimentare în cadrul de date pentru a le identifica.
Concept cheie: gândiți-vă cum veți denumi rezultatele analizei dvs. în Fiji pentru a face citirea datelor în R cât mai ușoară posibil.
Un flux de lucru alternativ pe care îl folosim în laborator este să folosim foldere imbricate pentru condiții și repetări experimentale, mai degrabă decât o structură plată ca în acest exemplu.
În acest caz, numele folderelor sunt folosite pentru a adăuga informații la cadrul de date.
Provocări către succes: folosim un „one-liner” foarte simplu în baza R pentru a încărca datele. Din păcate, este complicat de explicat cum funcționează acest lucru. NU te lăsa prins în explicarea alternativelor. Desigur, există multe modalități de a realiza această parte. Atelierul nu folosește bucle pentru și participanții nu trebuie să le înțeleagă pentru a-și atinge scopul. Amintiți-vă, ei nu sunt aici pentru a învăța programarea R în sine.
2. Fă niște calcule
Acesta este un pas opțional.
Sunt prezentate câteva exemple, dar nu sunt necesare pentru acest exercițiu, deoarece vom reprezenta pur și simplu datele.
## 2. Calculations ----
# normalise the data in the Mean column - just as an example
df$MeanNorm <- df$Mean / max(df$Mean)
# standardise the data in the Mean column - just as an example
df$MeanStand <- (df$Mean - mean(df$Mean)) / sd(df$Mean)
# since we have messed things up a bit, we can remake the df easily
# run the top part again to remake the df and then save the output
filelist <- list.files("Data", full.names = TRUE)
df <- do.call(rbind, lapply(filelist, function(x) {
temp <- read.csv(x);
temp$file <- basename(x);
temp
}))
df$cond <- sapply(strsplit(df$file, "_"), "(", 1)
df$expt <- sapply(strsplit(df$file, "_"), "(", 2)
# write data to file
write.csv(df, "Output/Data/df.csv")
Concept cheie: utilizați această parte pentru a sublinia din nou puterea scripturilor, arătând cum putem recrea cu ușurință cadrul de date în doar câteva rânduri de cod.
3. Faceți niște comploturi
- Folosiți ggplot pentru a face unele parcele
- Explicați gramatica graficii și demonstrați puterea fațetării, a tematicii și așa mai departe
- Explorați datele, observați că un experiment este diferit de celelalte
- Faceți un SuperPlot
- Salvați SuperPlot
## 3. Visualisation ----
# we will use ggplot2 for visualisation
# note that library loading usually goes at the top of the script!
library(ggplot2)
# histogram to look at the data
ggplot(df, aes(x = Mean, fill = cond)) + geom_histogram()
# density plot to look at the data
ggplot(df, aes(x = Mean, fill = cond)) + geom_density(alpha = 0.5)
# facetting, make plots by expt
ggplot(df, aes(x = Mean, fill = cond)) + geom_density(alpha = 0.5) + facet_wrap(~expt)
# themes
ggplot(df, aes(x = Mean, fill = cond)) + geom_density(alpha = 0.5) + facet_wrap(~expt) + theme_minimal()
ggplot(df, aes(x = Mean, fill = cond)) + geom_density(alpha = 0.5) + facet_wrap(~expt) + theme_bw()
# superplot
ggplot(df, aes(x = cond, y = Mean, colour = expt)) + geom_jitter()
library(ggforce)
ggplot(df, aes(x = cond, y = Mean, colour = expt)) + geom_sina()
ggplot(df, aes(x = cond, y = Mean, colour = expt)) + geom_sina(position = "auto")
# calculate experiment means
summary_df <- aggregate(Mean ~ cond + expt, data = df, FUN = mean)
# add to plot
ggplot(df, aes(x = cond, y = Mean, colour = expt)) +
geom_sina(position = "auto", alpha = 0.5) +
geom_point(data = summary_df, aes(x = cond, y = Mean, colour = expt), shape = 15, size = 3)
# keep adding to this or
p <- ggplot(df, aes(x = cond, y = Mean, colour = expt)) +
geom_sina(position = "auto", alpha = 0.5) +
geom_point(data = summary_df, aes(x = cond, y = Mean, colour = expt), shape = 15, size = 3)
p + theme_minimal()
p + theme_bw()
p + theme_bw() +
scale_color_manual(values = c("#4477aa", "#ccbb44", "#ee6677","#228833"))
# save plot
ggplot(df, aes(x = cond, y = Mean, colour = expt)) +
geom_sina(position = "auto", alpha = 0.5, maxwidth = 0.2) +
geom_point(data = summary_df, aes(x = cond, y = Mean, colour = expt), shape = 15, size = 3) +
scale_color_manual(values = c("#4477aa", "#ccbb44", "#ee6677","#228833")) +
labs(x = "", y = "Mitochondria Fluorescence (A.U.)") +
theme_bw(10) +
theme(legend.position = "none")
ggsave("Output/Plots/output.png", width = 6, height = 4, dpi = 300)
# this is an easy way
# stats
# t-test
t.test(summary_df$Mean ~ summary_df$cond)
În această parte veți folosi două biblioteci {ggplot2} şi {ggforce}. Participanții vor vedea unele parcele pentru prima dată și vor folosi acest lucru ca o șansă de a vorbi despre date în termeni biologici celulari. Setul de date este conceput pentru a avea o neregulă (a se vedea mai jos) și astfel încât să o puteți folosi ca o șansă de a-i determina pe participanți să-și dezvolte cunoștințele biologice celulare despre motivul pentru care poate fi asta!
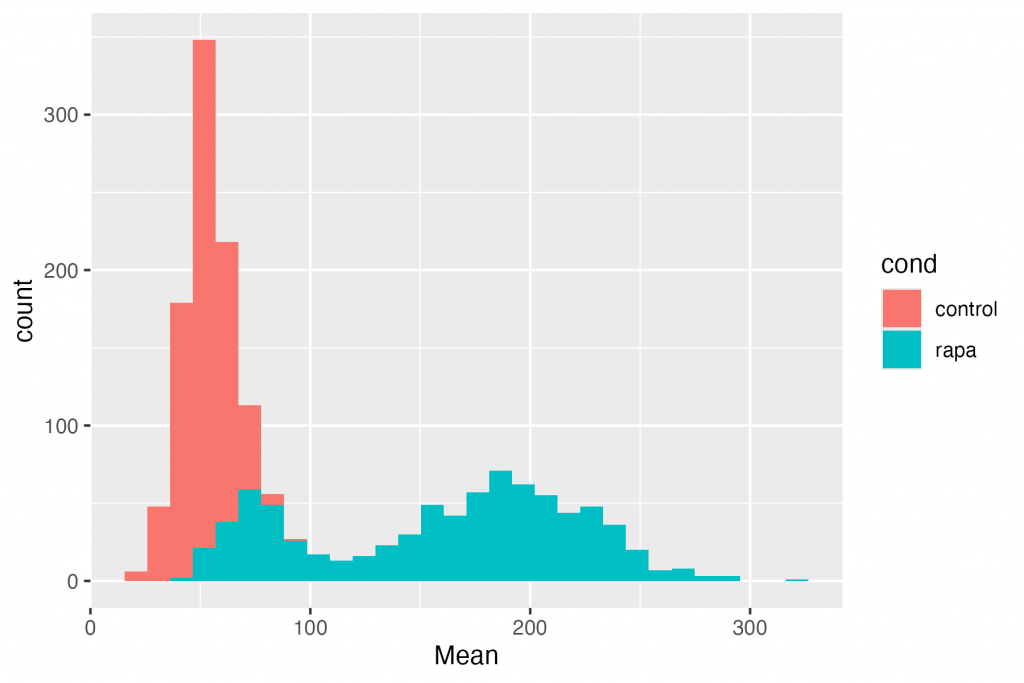
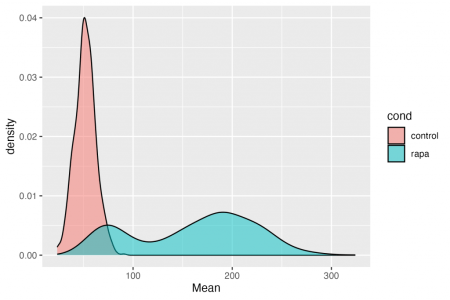
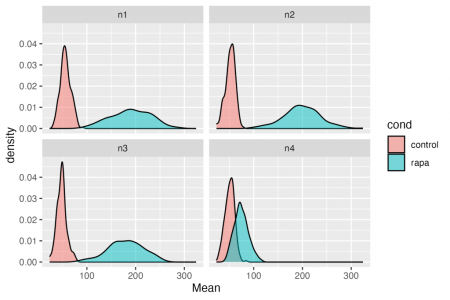
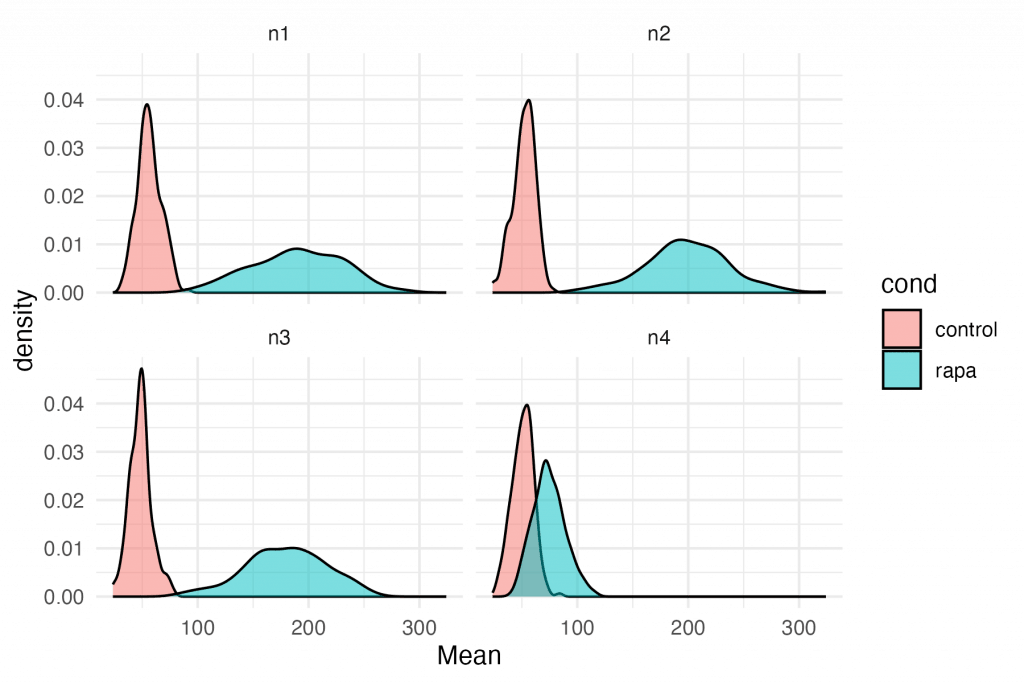
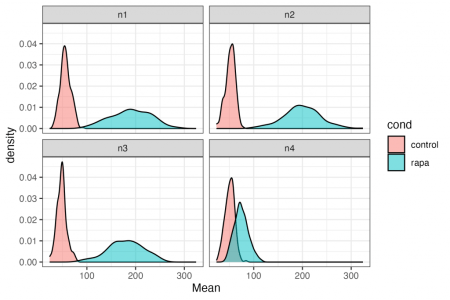
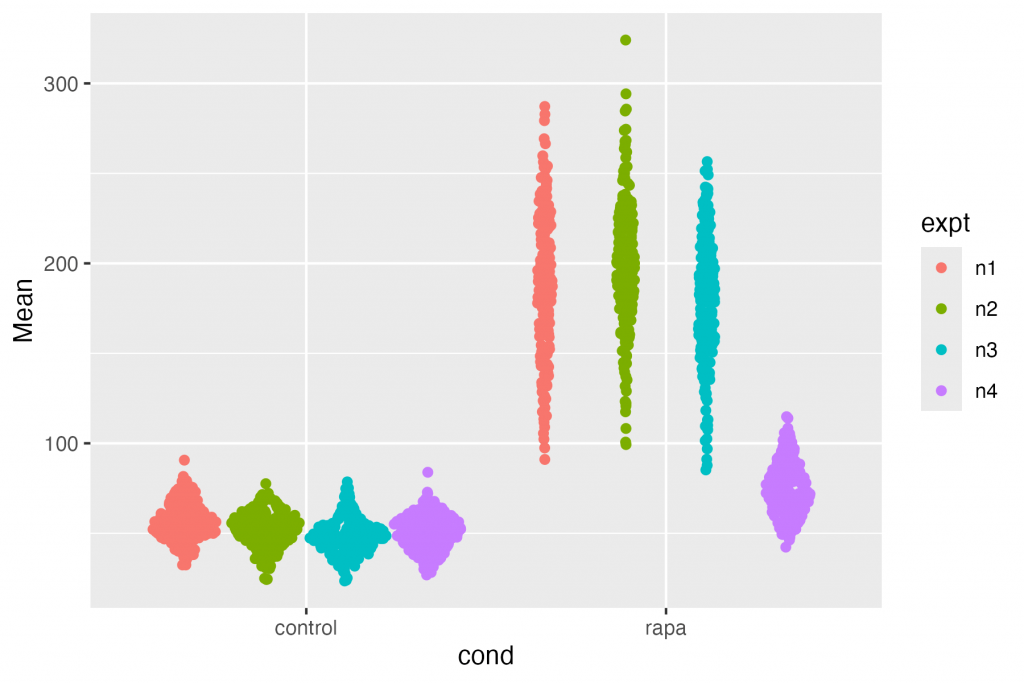
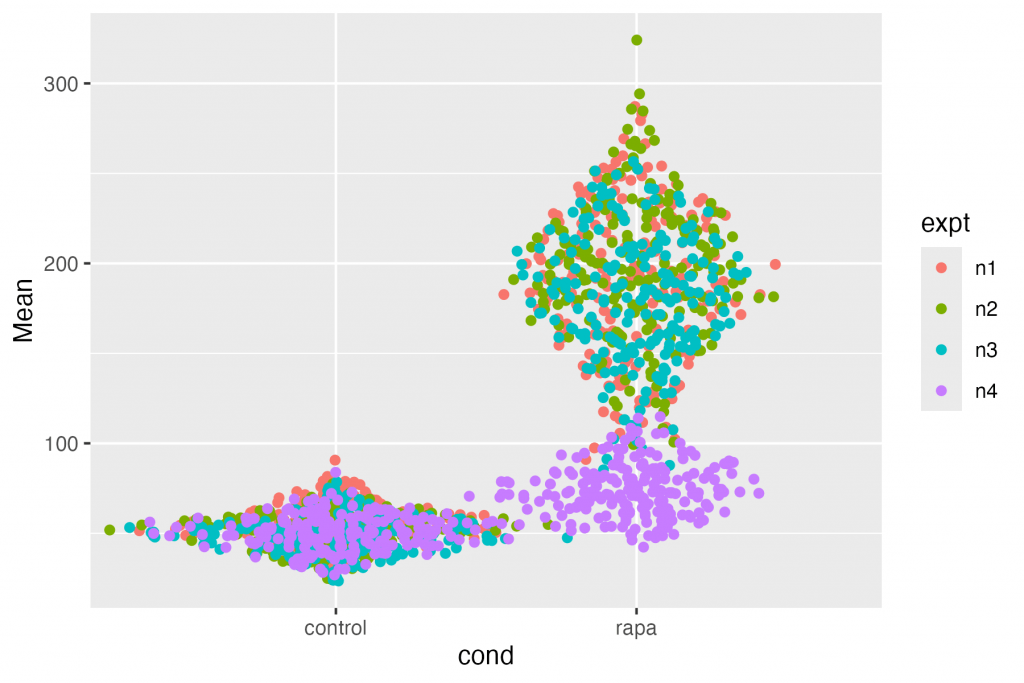
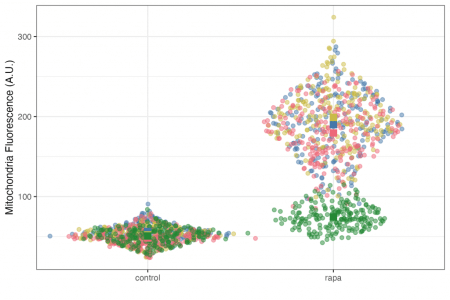
Concept cheie: cadrul de date pe care l-ați creat are toate informațiile pentru a face orice diagramă de care aveți nevoie.
Teme pentru acasă
Pentru a consolida procesul de învățare, cereți participanților să descopere cum să facă următoarele:
Care rând (din ce experiment/condiție/celulă) a avut cea mai mică valoare medie?
Apoi, explicați că persoana care a făcut experimentele a aflat că rapamicina utilizată în al 4-lea experiment a fost preparată dintr-o soluție stoc care a fost la o concentrație greșită.
Cum putem exclude datele n4 și refacem un nou SuperPlot, astfel încât toate experimentele să folosească concentrația corectă?
Explicați că obținerea asistenței de la un LLM este puțin probabil să-i ajute să învețe. Căutarea unei soluții este bine. Spuneți-le un cuvânt cheie de căutat: subset/subsetting.
Soluțiile pot fi discutate într-o sesiune de urmărire sau prin slack etc.
Cum a mers?
Am desfășurat acest atelier de formare de două ori și feedback-ul a fost bun de ambele ori. Cu siguranță, unii membri ai laboratorului, care anterior evitau R, au început să-l folosească pentru propria lor analiză a datelor. De fapt, ei folosesc scriptul pentru această sesiune ca bază pentru propria lor sesiune. Acest lucru a avut consecința neintenționată a standardizării scripturilor de laborator, ceea ce, la rândul său, le face mai ușor de depanat.
Prima dată când am organizat instruirea, l-am asociat și cu un atelier Fiji, astfel încât participanții să se poată gândi la întregul flux de lucru. Pentru aceasta am folosit o problemă de analiză a imaginii care trebuia rezolvată. Acest lucru a funcționat destul de bine, dar din moment ce soluția nu era cunoscută, a fost greu să o legați de atelierul R.
Subliniez că atunci când se gândesc la fluxul de lucru de la experiment la cifra, membrii laboratorului ar trebui să ia în considerare analiza lor și cum să le facă mai ușor pentru ei înșiși. De exemplu, atunci când se află la microscop, denumirea fișierelor este importantă, deoarece acestea trec prin: la pasul Fiji și apoi în R. Orice inconsecvență provoacă dureri de cap. Din nou, dacă acest lucru îmbunătățește obiceiurile de lucru ale membrilor laboratorului, acesta este doar un lucru bun.
Materialele pot fi probabil rafinate. Așa cum sunt, durează 90 de minute pentru a se acoperi și, dacă există întrebări, poate deveni destul de strâns. Extinderea secțiunii din mijloc folosind un exemplu care necesită mai multe calcule ar fi utilă pentru a arăta cu adevărat ce poate face R, dar acest lucru ar necesita, evident, mai mult timp.
—
Titlul postării vine de la Get Better by The New Fast Automatic Daffodils. Versiunea pe care o am este pe o compilație de piese produse de Martin Hannett, numită „And Here Is The Young Man”.
Parte dintr-o serie de dezvoltare a abilităților membrilor laboratorului.