(Acest articol a fost publicat pentru prima dată pe R | Ben Johnstonși cu amabilitate a contribuit la R-bloggeri). (Puteți raporta problema legată de conținutul acestei pagini aici)
Doriți să vă distribuiți conținutul pe R-bloggeri? dați clic aici dacă aveți un blog, sau aici dacă nu aveți.
R pentru SEO Partea 8: Aplicați metode în R
Bine ai revenit din nou. Acum suntem la partea a opta a seriei mele despre R pentru SEO și am fost într-o călătorie destul de mare până acum, nu-i așa? Ceea ce trebuia inițial să-mi ia opt săptămâni a durat câțiva ani! Între o pandemie, mai multe locuri de muncă, două mutări de casă, unele schimbări mari în viața mea personală și multe schimbări în ecosistemul de marketing, a fost un lot. Dar astăzi, suntem la început și vom vorbi despre utilizarea familiei de aplicații în R.
Aplicațiile sunt o modalitate mai „centrată pe R” de a rula funcții într-o serie de date. Nu sunt complet diferite de bucle, dar tind să fie o modalitate mai eficientă de a le scrie și vin cu funcționalități suplimentare care pot fi foarte utile într-o serie de situații.
Veți fi văzut că unele dintre ele sunt deja folosite în această serie, în special când am vorbit despre utilizarea API-urilor în R. Deci, să aruncăm o privire la componentele familiei de aplicații și la ce pot fi folosite.
Ca întotdeauna, aceasta este o bucată destul de lungă, așa că nu ezitați să săriți peste folosind cuprinsul de mai jos și vă rugăm să vă înscrieți la lista mea de e-mail pentru a fi la curent când public conținut nou.
Ce sunt comenzile Apply în R?
Familia de aplicații a lui R vă permite în esență să aplicați o comandă sau o funcție într-o serie de date. Indiciul este în nume, nu? Deși nu este diferit de o buclă în concept, există o serie de diferențe care adesea le fac o alegere mai bună sau mai simplă.
Ca și în cazul buclelor, există câteva variații diferite pe care le putem folosi. Să ne uităm la ce sunt acestea înainte de a începe cu privire la modul în care putem folosi aceste metode diferite de aplicare a R în munca SEO.
Diferitele tipuri de metode de aplicare în R
Există patru aplicații cheie în familia de aplicații
- Aplica: Cel mai elementar. Aplicați rulări pe o coloană dintr-o matrice sau un cadru de date. În general, îl folosesc atunci când vreau să găsesc valoarea maximă sau minimă a unei coloane sau dacă încerc să aflu de câte ori un termen este menționat într-un corpus de text
- Laply: M-ați văzut folosind asta de câteva ori în această serie și, sincer, este cea pe care o folosesc cel mai mult. Lapply aplică o funcție pe o listă sau un vector și este excelent pentru utilizarea funcțiilor și a apelurilor API
- Sapply: Similar cu lapply, și încă unul îl folosesc destul de puțin. Sapply înseamnă „aplicare simplă” și încearcă să simplifice rezultatul în comparație cu lapply
- Mapply: Mapply înseamnă „aplicarea hărții” și este excelent atunci când trebuie să utilizați metoda de aplicare pe mai multe seturi de date sau elemente
Așa că acum știm ce sunt, haideți să vedem cum aplica (Ha! Sunt un geniu al comediei!) Acestea pentru a merge SEO.
Utilizarea metodei Apply a lui R pentru a număra cuvintele cheie din datele Google Search Console
Cel mai simplu mod de a arăta diferența dintre bucle și aplicații este probabil de a replica buclele noastre din ultima piesă folosind diferite metode de aplicare.
Pentru a folosi metoda de bază R de aplicare, să reluăm ceea ce am făcut cu prima buclă for pentru a număra numărul de cuvinte cheie care au 20 sau mai multe afișări din setul de date Google Search Console – puteți urma pașii din partea 2 pentru a obține acele date, sau pur și simplu exportați din Google Search Console și importați-l folosind funcția read.csv din partea 1.
Presupunând că ați denumit cadrul de date gsc, utilizați următoarea comandă:
kwCount <- sum(apply(gsc("Impressions"), 1, function(x) x >= 20))
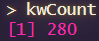
Acum, dacă investigăm obiectul nostru kwCount din consolă, folosind
kwCount
Ar trebui să vedem următoarele – datele dvs. vor fi diferite și probabil mult mai mari decât ale mele.

Dar am făcut asta într-o singură linie, în comparație cu liniile multiple ale buclei pe care le-am folosit anterior, nu-i așa?
Ca întotdeauna, haideți să o descompunem.
Comanda noastră de aplicare este defalcata
Comanda noastră de aplicație a făcut ceea ce bucla a realizat într-o singură linie, mai degrabă decât cinci. E interesant. Să vedem cum funcționează.
- kwCount <-: Ca și în cazul tuturor comenzilor pe care le-am folosit de-a lungul seriei, ne-am numit obiectul și am folosit <- pentru a-i spune lui R că vrem să-l păstrăm și să folosim acest nume special.
- suma(aplica: Invocăm comanda sum cu care suntem bine familiarizați și apoi folosim aplica pentru ao aplica fiecărui rând sau coloană din setul nostru de date
- gsc(„Afișări”),: Acest lucru îi spune lui R că vrem să folosim acest lucru pe setul nostru de date gsc și că vrem să ne concentrăm pe coloana Afișări
- 1: Numărul 1 specifică că vrem să folosim acest lucru pe rânduri. Dacă am vrea să fie peste coloane, am folosi 2
- funcția(x) x >= 20)): În cele din urmă, folosim o funcție foarte simplă pe care o aplicăm pe rânduri pentru a vedea dacă valoarea este mai mare sau egală cu 20
Destul de la îndemână, nu? Oferă aceeași ieșire ca prima noastră buclă din partea 7, dar mult mai rapid și mai eficient.
Acum să aruncăm o privire la Lapply.
Utilizarea lui R Lapply pe o listă sau un cadru de date
Lapply este una dintre cele mai populare metode de aplicare ale lui R și una pe care o folosesc mult mai intens decât comanda obișnuită de aplicare. Lapply rulează pe o listă sau un vector și este deosebit de bun pentru utilizare în mai multe apeluri API sau URL-uri, ceea ce este firesc, foarte util pentru analiza SEO.
Să aruncăm o privire la modul în care putem folosi lapply pentru a replica bucla noastră „listă” din partea 7, unde o folosim pentru a subseta setul de date Google Search Console pentru a afișa date pentru cuvintele cheie cu 20 sau mai multe afișări.
Din nou, evident, am folosi subsetul din partea 1 pentru aceasta de cele mai multe ori, dar este un prim exemplu bun pentru utilizarea lapply.
kw20 <- reduce(lapply(seq_along(gsc$Impressions), function(x) if (gsc$Impressions(x) >= 20) gsc(x, ) else NULL), bind_rows)
Aici, folosim funcția reduce din tidyverse pentru a acoperi do.call(bind în mai puțin cod.
Acest lucru vă va oferi un cadru de date numit kw20, care include numai cuvinte cheie, afișări, clicuri și CTR în cazul în care afișările sunt de 20 sau mai mult.
Rulați-l în consola dvs. și acum, ca întotdeauna, să o descompunem.
Comanda noastră Lapply s-a defectat
Din nou, ne-am replicat bucla într-o cantitate mai mică de cod folosind o metodă de aplicare – lapply în acest caz – decât am folosit-o cu bucla.
Sperăm că începeți să vedeți puterea familiei de aplicații pentru a scrie mai puțin cod, dar pentru a obține aceleași rezultate. L-am redus și mai mult utilizând funcția de reducere a lui Tidyverse. Probabil că înțelegi de ce nu încep niciodată R fără Tidyverse.
Să aruncăm o privire la cum funcționează:
- kw20 <- reduce(laply(: Creăm un obiect numit kw20 și invocăm comanda reduce a Tidyverse înainte de a apela lapply. Reducere ne permite să legăm rezultatul pentru fiecare rând în rezultatul nostru
- seq_along(gsc$ Impresii: Ca și în bucla anterioară, folosim seq_along în coloana Impresii a setului nostru de date gsc pentru a ne aplica funcția pe fiecare rând
- funcția(x): Creăm funcția noastră foarte simplă cu variabila x, similar cu felul în care am procedat pe tot parcursul acestei serii
- dacă (gsc$Impressions(x) >= 20) gsc(x, ) else NULL),: Dacă vă întoarceți mintea la partea 5, unde am vorbit despre afirmațiile if din R, acest lucru nu va fi prea necunoscut. Funcția noastră este o declarație if foarte simplă, în care vedem dacă valoarea Impresiilor din rândul specific al aplicației este mai mare sau egală cu 20. Dacă nu este, restul returnează NULL, ceea ce nu înseamnă nimic.
- bind_rows): În cele din urmă, folosim dplyr din comanda bind_rows a Tidyverse pentru a adăuga valorile coloanei la următorul rând din setul nostru de date de ieșire
Așa că o avem – o comandă lapply foarte simplă pentru a rula o funcție simplă pe mai multe rânduri ale unui set de date.
Acum să ne uităm la sapply și cum este similar, dar și puțin diferit.
Folosind Sapply-ul lui R pe o listă sau un cadru de date
Sapply – adică „aplicare simplă” poate funcționa foarte asemănător cu lapply în multe cazuri, dar se concentrează pe simplificarea ieșirii într-un cadru de date sau un vector, mai degrabă decât o listă. Găsesc că atunci când folosesc reduce și bind_rows din Tidyverse, obțin rezultate mai bune de la lapply decât la saply.
Oricum, haideți să vedem cum putem face aceeași comandă pe care tocmai am făcut-o la Lapply folosind Sapply.
kw20 <- reduce(sapply(seq_along(gsc$Impressions),
function(x) if (gsc$Impressions(x) >= 20) gsc(x, ),
simplify = FALSE), bind_rows)
Dacă aceasta rulează așa cum ar trebui, vă va oferi aceeași ieșire în kw20 ca și comanda lapply, dar există unele diferențe în comandă pe care vrem să le analizăm.
Comanda noastră Sapply
După cum veți vedea privind codul, comanda pe care am folosit-o aici este aproape exact aceeași cu comanda out lapply, cu o diferență cheie – avem următorul parametru acolo:
simplify = FALSE
Deoarece principiul de bază al sapply este să se aplice „pur și simplu”, acesta încearcă să simplifice ieșirile către un cadru de date. Deoarece lucrăm deja cu un cadru de date, putem folosi simplify = FALSE aici, deoarece nu avem nevoie de el.
Cu toate acestea, dacă încercați să forțați o listă sau o matrice în ceva mai ușor de lucrat, Sapply este o alegere excelentă. Mă trezesc că îl folosesc mai ales atunci când lucrez la ieșiri JSON, dar pentru acest exemplu, puteți vedea că funcționează destul de bine în același mod în care a făcut metoda noastră laply.
Sunt sigur că vedeți o mulțime de moduri prin care familia de aplicații a lui R poate fi folosită pentru SEO până acum. Să aruncăm o privire la cele mai complexe metode de aplicare acum – puternicul mapply().
Folosind metoda Maply a lui R
Mapply vă permite să executați comenzi de aplicare pe mai multe elemente de cadru de date sau vectori și este foarte util atunci când trebuie să faceți acest lucru. Este o funcție foarte puternică și vă permite să faceți o analiză foarte complexă cu foarte puțin cod. Să folosim un exemplu foarte simplu pentru a identifica o diferență între ratele noastre de clic în raport cu o țintă, folosind datele din Google Search Console.
În primul rând, dacă ați importat setul de date Google Search Console dintr-un export CSV în loc să utilizați API-ul, va trebui să faceți o mică pregătire pentru a elimina caracterul procentual, a seta coloana ca număr și a o împărți la 100. Aceasta Funcția simplă de mai jos va face asta:
ctrCleanup <- function(x){
x <- gsub("%", "", x)
x <- as.numeric(x)
x <- x/100
}
Veți fi văzut toate acestea de-a lungul seriei, dar haideți să le dezvăluim oricum:
- ctrCleanup <- function(x){: Funcția noastră se numește ctrCleanup (catchy, nu?) și are o variabilă x
- x <- gsub(„%”, „”, x): Pe x, (coloana noastră CTR), rulăm gsub pentru a găsi și înlocui caracterul % cu nimic. Îndepărtând-o, în mod eficient
- x <- ca.numeric(x): Acum setăm acea coloană ca număr, mai degrabă decât caracterul care era anterior, deoarece am eliminat caracterul %
- x <- x/100: În cele din urmă, îl împărțim la 100, astfel încât să putem obține procentul nostru ca zecimală
Rulați acest lucru în consola dvs. cu următoarea comandă:
gsc$CTR <- ctrCleanup(gsc$CTR)
și veți avea coloana CTR ca zecimale, gata să lucrați cu comanda noastră mapply.
Acum vrem să ne definim CTR-ul țintă. Să luăm 5%.
targetCTR <- 0.05
Acum suntem pregătiți, să rulăm comanda noastră mapply.
gsc$ctrDiff <- mapply(function(x, y) abs(x - y), gsc$CTR, targetCTR)
Acest lucru va crea o nouă coloană în setul nostru de date numită ctrDiff cu diferența dintre rata de clic reală și ținta noastră.
Comanda noastră Maply s-a defectat
Ca întotdeauna, haideți să o descompunem:
- gsc$ctrDiff <- mapply(: Creăm o nouă coloană numită ctrDiff în cadrul nostru de date gsc și folosim mapply pentru a rula funcția noastră
- funcția(x, y) abs(x – y): Funcția noastră folosește parametrii x și y (cele două elemente ale noastre de date) și folosește abs pentru a găsi diferența absolută dintre ei
- gsc$CTR, targetCTR): În cele din urmă, ne definim variabilele x și y – rata noastră reală de clic din Google Search Console și CTR-ul nostru vizat
Rularea acestui lucru va crea o nouă coloană în gsc și vă va oferi diferența prin interogare față de CTR-ul țintă. Sperăm că vă va oferi o idee despre unde trebuie să lucrați cu eforturile dvs. de SEO. Sau poate nu, dar cel puțin îți dă o idee despre cum funcționează mapply!
Deci, acestea sunt bazele modului în care pot funcționa diferitele metode de aplicare din R. Există un fir comun în anatomia lor, nu-i așa?
Să ne uităm la asta acum.
Anatomia metodelor de aplicare a lui R
În general, familia de aplicații are un fir comun al modului în care funcționează – o anatomie comună. Te vei trezi că lucrezi în jurul asta pe măsură ce mergi mai departe în călătoria ta R, dar, în general, vei privi astfel:
dataframe <- applyMethod(data, function, extra parameters)
Pare puțin înapoi, nu-i așa? De obicei, numim funcția noastră înainte de date. Adevărat, nu știu pe deplin de ce se procedează astfel, dar bănuiesc că are de-a face cu faptul că definim datele la care să aplicăm funcția înainte de a începe efectiv să o aplicăm. Toate limbajele de programare au aceste mici elemente distractive și cred că acesta este unul dintre R.
Cred că aceasta ar putea fi de fapt cea mai scurtă dintre postările pe care le-am scris în această serie, dar nu lăsați ca acesta să fie un indiciu al puterii familiei de aplicații a lui R – sunt absolut vitale în programarea R și un element esențial în utilizarea R. pentru SEO.
Până data viitoare, unde vom vorbi despre web scraping în R.
Codul nostru de azi
# Install Packages
install.packages("tidyverse")
library(tidyverse)
# Read In Data
gsc <- read.csv("Queries.csv", stringsAsFactors = FALSE)
# Apply Methods
## Apply()
kwCount <- sum(apply(gsc("Impressions"), 1, function(x) x >= 20))
## Lapply()
kw20 <- reduce(lapply(seq_along(gsc$Impressions), function(x) if
(gsc$Impressions(x) >= 20) gsc(x, ) else NULL), bind_rows)
## Sapply()
kw20 <- reduce(sapply(seq_along(gsc$Impressions),
function(x) if (gsc$Impressions(x) >= 20) gsc(x, ),
simplify = FALSE), bind_rows)
## Mapply
ctrCleanup <- function(x){
x <- gsub("%", "", x)
x <- as.numeric(x)
x <- x/100
}
gsc$CTR <- ctrCleanup(gsc$CTR)
targetCTR <- 0.05
gsc$ctrDiff <- mapply(function(x, y) abs(x - y), gsc$CTR, targetCTR)
Această postare a fost scrisă de Ben Johnston pe Ben Johnston