(Acest articol a fost publicat pentru prima dată pe R pe Nicola Rennieși a contribuit cu drag la R-Bloggers). (Puteți raporta problema despre conținutul de pe această pagină aici)
Doriți să vă împărtășiți conținutul pe R-Bloggers? Faceți clic aici dacă aveți un blog sau aici dacă nu.
Observabil este un mediu de programare reactiv bazat pe JavaScript, utilizat în mod obișnuit pentru explorarea interactivă a datelor, vizualizarea și tablourile de bord. Puteți crea și publica caiete observabile la ObservableHQ.com (care este, de asemenea, un loc minunat pentru a căuta inspirație și suport) sau puteți utiliza JavaScript observabil în documente și site -uri web autonom.
Deci, de ce ar dori un utilizator R să învețe sau să folosească observabil? Deși există mai multe pachete diferite pentru crearea de diagrame interactive direct în R, acestea pot fi uneori greu de personalizat, încărcat lent sau necesită un server R pentru implementare. Cu observabil, puteți utiliza diferite biblioteci JavaScript pentru o personalizare avansată (deși curba de învățare ar putea fi destul de abruptă pentru unii). Deoarece este bazat pe JavaScript, nu este nevoie ca un server să ruleze cod, iar modelul său reactiv și redarea eficientă într-un browser, înseamnă că vizualizările sale interactive pot fi adesea mai rapide.
Deși puteți face unele date de date și modelare în cadrul observabilului, R are, probabil, capacități mult mai bune pentru modelarea statistică. Dacă doriți tot ce este mai bun din ambele lumi, ar putea avea sens să folosiți pentru Wrangling și Modeling, atunci utilizați observabil pentru crearea de vizualizări interactive, bazate pe web. Din fericire, există o modalitate ușoară de a face doar asta folosind quarto. Această postare pe blog va parcurge procesul de efectuare a unor date care se luptă în R, transmiterea datelor la observabil și crearea unei vizualizări folosind observabil.
Quarto este un sistem de publicare științific și tehnic open-source, care vă permite să combinați cu ușurință codul cu textul narativ pentru a crea ieșiri reproductibile. Funcționează cu codul scris în Python, R, Julia sau observabil. Dacă nu ați mai folosit Quarto, v -aș recomanda să verificați secțiunea de pornire a documentației. Îl puteți vedea și pe al meu Introducere în quarto
Materiale de curs de instruire.
Dacă sunteți cineva care este intrigat de bibliotecile JavaScript precum D3.js pentru crearea de vizualizări, dar sunt descurajați de cât de complicat arată și cât de abrupt ar putea fi curba de învățare, atunci utilizarea observabilă cu Quarto poate fi o introducere mai blândă. De asemenea, nu trebuie să instalați sau să configurați niciun software suplimentar. Atâta timp cât ați instalat quarto, documentul dvs. va reda astfel încât să permită utilizarea observabilă în cadrul rezultatelor dvs.
Date care se ridică în R
Să ne scufundăm într -un exemplu! Începem prin crearea unui nou document de cvarto. Puteți alege să lăsați YAML gol dacă doriți, dar vă recomand să ascundeți codul setând echo: false Pentru a vă asigura că numai vizualizările dvs. se termină în ieșirea finală.
1 2 3 4 |
--- execute: echo: false --- |
Vom folosi date despre istoricul expedițiilor de alpinism din Himalaya, care a fost utilizat ca un set de date Tidytuesday în ianuarie 2025. Putem încărca datele folosind {tidytuesdayR} Pachet înainte de a efectua orice date care se ridică în R așa cum am fi în mod normal:
1 2 3 4 5 |
```{r}
tuesdata <- tidytuesdayR::tt_load("2025-01-21")
exped_tidy <- tuesdata$exped_tidy
peaks_tidy <- tuesdata$peaks_tidy
```
|
Ne vom concentra pe peaks_tidy Date aici unde arată primele câteva linii:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# A tibble: 480 × 29 PEAKID PKNAME PKNAME2 LOCATION HEIGHTM HEIGHTF HIMAL |
Aici, îl vom păstra rezonabil de simplu și vom privi relația dintre primul an a fost înregistrată o urcare (PYEAR) și înălțimea vârfului (HEIGHTM) De asemenea, ne vom uita la regiunea Himalaya în care se află fiecare vârf (REGION_FACTOR) Putem filtra datele și selecta coloanele pe care ne interesează să le utilizăm {dplyr} (sau baza r dacă preferați):
1 2 3 4 5 6 |
```{r}
library(dplyr)
plot_data <- peaks_tidy |>
filter(PSTATUS_FACTOR == "Climbed") |>
select(PYEAR, HEIGHTM, REGION_FACTOR)
```
|
Datele noastre arată acum astfel:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# A tibble: 368 × 3 PYEAR HEIGHTM REGION_FACTOR |
Este rezonabil ordonat și suntem gata să începem să complotăm (în observabil).
Blocuri de cod observabile
În Quarto, un bloc de cod observabil este adăugat într -un mod foarte similar cu blocurile de cod R. În loc să specifice limba folosind {r}folosim {ojs} în schimb. Aici, ojs înseamnă JavaScript observabil (OJS), deși este important ca {ojs} este în minuscule:
Spre deosebire de R, blocurile de cod observabile nu trebuie să fie în ordine. Aceasta înseamnă că puteți grupa toate ieșire codificați împreună și toate Prelucrarea datelor Cod împreună pentru a menține documentul dvs. curat (similar cu separarea de ui şi server în aplicații strălucitoare).
Trecerea datelor de la R la observabil
Pentru a trece datele noastre curate, înfășurate de la R la observabil, folosim ojs_define() funcție, unde definim ceea ce dorim ca obiectul să fie numit în observabil (r_data) și ce obiect vrem să trecem de la r (plot_data):
1 2 3 |
```{r}
ojs_define(r_data = plot_data)
```
|
Rețineți că acesta este un bloc de cod R, nu un bloc de cod observabil. Numele obiectului observabil nu trebuie să fie r_datași poate fi același nume ca obiectul R (sau aproape orice altceva)!
R trece datele la observabile într -un de coloană format. În funcție de funcțiile sau bibliotecile din observabil pe care îl utilizați pentru a vizualiza datele dvs. de rând Format în schimb. În observabil, putem folosi transpose() Funcție de la care să comutați de la de coloană la de rând Format – De când de bază Plot() Funcția pe care o vom folosi mai târziu necesită -o în acest format:
1 2 3 |
```{ojs}
data = transpose(r_data)
```
|
O abordare alternativă ar putea fi salvarea datelor înfășurate într -un fișier CSV sau JSON în R și să le citiți în observabil ca fișier local folosind FileAttachment() funcţie. Consultați secțiunea Surse de date din documentația Quarto pentru diferite moduri de citire în date.
Folosind alte biblioteci
Când utilizați biblioteci de bază care vin cu observabil (cum ar fi Observable Plot), nu este nevoie să instalați sau să încărcați nimic suplimentar. Cu toate acestea, dacă doriți să utilizați biblioteci non-core precum D3 sau Arquero (o bibliotecă inspirată de {dPlyr} pentru transformarea datelor), este destul de simplu să o faceți. Pur și simplu trebuie să fim expliciți cu privire la importul acestor biblioteci. De exemplu, pentru a accesa funcțiile de la D3, am rula:
1 2 3 |
```{ojs}
d3 = require("d3@7")
```
|
Pentru acest exemplu, vom putea face totul să folosim biblioteca de complot observabilă de bază, deci nu trebuie să folosim biblioteci suplimentare.
Complotând cu observabil
Observabil Plot este o bibliotecă JavaScript, care vizează în principal crearea vizualizărilor de date exploratorii, care este una dintre bibliotecile de bază observabile. Puteți desena multe dintre cele mai frecvente tipuri de diagrame folosind plot() Funcție din Plot bibliotecă. În Plot.plot()specificăm marks Pentru a defini geometriile care sunt trase, cum ar fi liniile sau punctele; color pentru a defini culorile care sunt utilizate; precum și alte argumente precum title şi subtitle care poate folosi pentru a adăuga text. Dacă ești un {ggplot2} utilizator, puteți observa unele asemănări, deoarece urmează și un Gramatica grafică abordare.
Din nou, îl vom păstra simplu pentru acest exemplu introductiv și vom crea un complot de împrăștiere de bază al anului, împotriva înălțimii de vârf pentru datele noastre de expediții din Himalaya. În marks Argument, începem să trecem în funcția pentru geometria pe care vrem să o desenăm. Pentru a crea un complot de împrăștiere, trebuie să desenăm puncte, așa că folosim Plot.dot() funcţie. Primul argument este setul de date pe care îl tratăm, iar al doilea argument este locul în care specificăm ce coloane ale hărții de date pe care axa. Din nou, dacă ești un {ggplot2} utilizator, acest lucru este foarte similar cu setarea argumentelor pentru date și mapare estetică folosind aes().
1 2 3 4 5 6 7 |
```{ojs}
Plot.plot({
marks: (
Plot.dot(data, {x: "PYEAR", y: "HEIGHTM"})
)
})
```
|
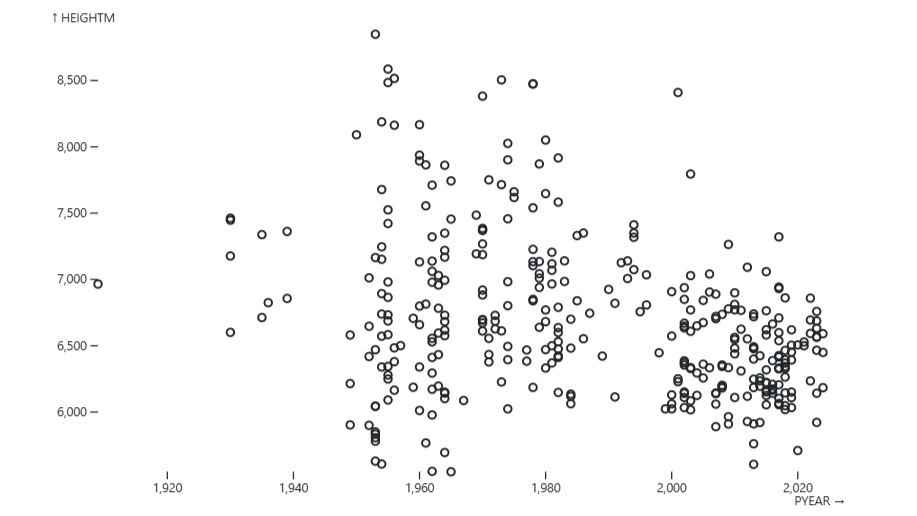
Acest lucru ne oferă un complot de împrăștiere foarte de bază și există câteva ajustări pe care am putea dori să le facem pentru a îmbunătăți claritatea acesteia. S-ar putea să observați că axa X arată puțin ciudat pentru datele care reprezintă ani. Valorile anului sunt tratate ca numere și astfel le formatează cu virgule. Acest lucru este util atunci când complotăm un număr mare, dar nu atât de util atunci când sunt de fapt ani. Există câteva abordări pe care le -am putea adopta, dar cel mai simplu mod este să convertim PYEAR coloana de la un număr la o dată, iar observabil va ști cum să o formateze corect:
1 2 3 4 5 6 7 |
```{ojs}
dataTyped = data.map(({ PYEAR, HEIGHTM, REGION_FACTOR }) => ({
PYEAR: new Date(PYEAR, 0, 1),
HEIGHTM,
REGION_FACTOR
}))
```
|
Să edităm, de asemenea, etichetele axei la ceva mai lizibil decât numele coloanelor și să adăugăm o grilă în fundal. Folosim grid, xși y Argumente pentru a face aceste ajustări, amintindu -ne de a actualiza și datele la noul nostru set de date (corect tastat):
Putem adăuga comentarii pentru a ne documenta codul folosind
//În același mod în care folosim#În R.
1 2 3 4 5 6 7 8 9 10 11 12 |
```{ojs}
Plot.plot({
// Draw points
marks: (
Plot.dot(dataTyped, {x: "PYEAR", y: "HEIGHTM"})
),
// Grid and axes styling
grid: true,
x: {label: "Year of the first recorded climbing attempt on the peak"},
y: {label: "Peak height (m)"}
})
```
|

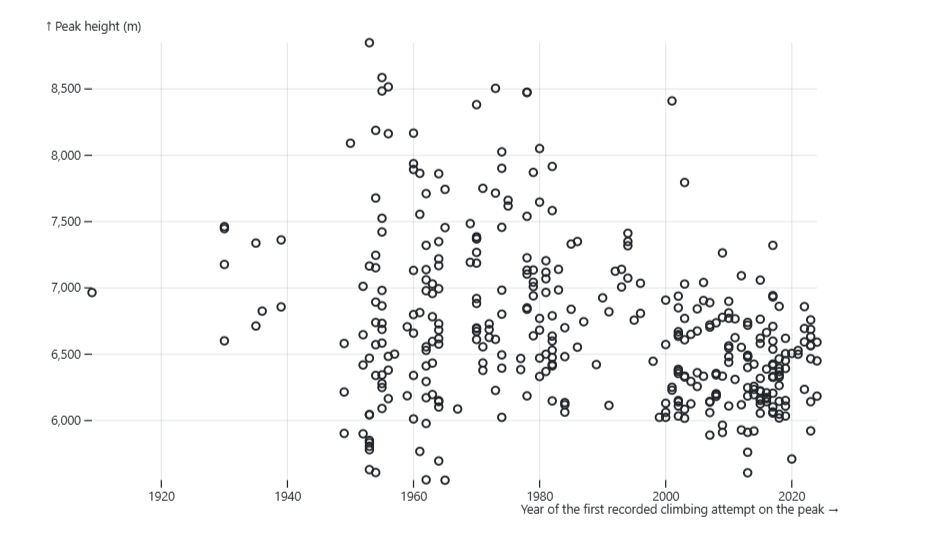
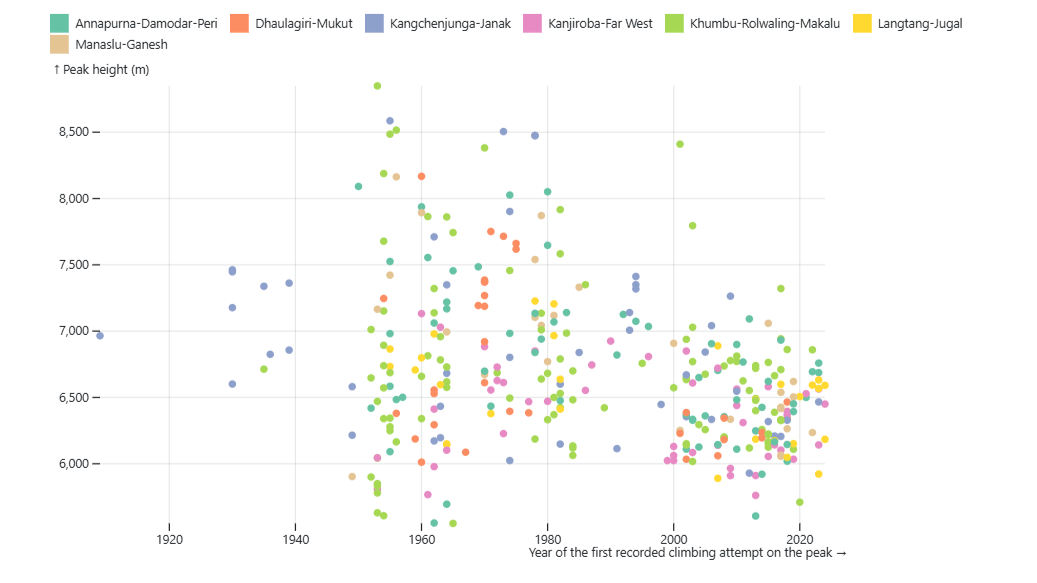
Pentru a schimba culoarea punctelor, edităm cartografiere Pentru a seta și fill culoarea punctelor care se bazează pe valorile din REGION_FACTOR coloană. În interiorul color argument, putem seta dacă dorim sau nu o legendă și, de asemenea, alegem o paletă de culori în scheme argument.
Palete de culori observabile: Documentația observabilă are un vizualizator de palete de culori interactive, unde puteți răsfoi diferite palete de culori secvențiale, divergente și discrete. Opțiunile încorporate includ paletele Colorbrewer, care sunt disponibile și în R.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
```{ojs}
Plot.plot({
// Draw points
marks: (
Plot.dot(dataTyped, {x: "PYEAR", y: "HEIGHTM", fill: "REGION_FACTOR"})
),
// Colours
color: {legend: true, scheme: "set2"},
// Grid and axes styling
grid: true,
x: {label: "Year of the first recorded climbing attempt on the peak"},
y: {label: "Peak height (m)"}
})
```
|
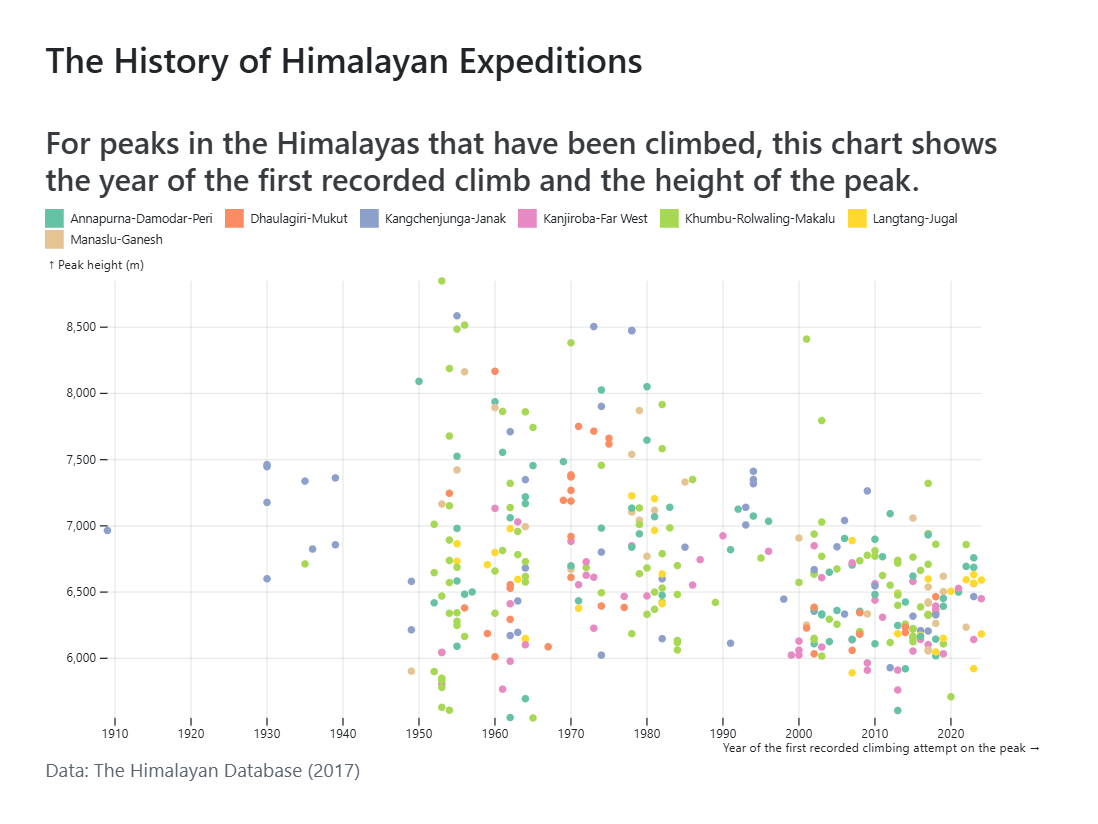
În cele din urmă, putem adăuga un titlu, un subtitrare și o legendă la complot. De asemenea, putem seta dimensiunea zonei parcelei și putem schimba dimensiunile marjelor pentru a adăuga un pic mai mult spațiu în jurul parcelei:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
```{ojs}
Plot.plot({
// Draw points
marks: (
Plot.dot(dataTyped, {x: "PYEAR", y: "HEIGHTM", fill: "REGION_FACTOR"})
),
// Colours
color: {legend: true, scheme: "set2"},
// Grid and axes styling
grid: true,
x: {label: "Year of the first recorded climbing attempt on the peak"},
y: {label: "Peak height (m)"},
// Text
title: "The History of Himalayan Expeditions",
subtitle: "For peaks in the Himalayas that have been climbed, this chart shows the year of the first recorded climb and the height of the peak.",
caption: "Data: The Himalayan Database (2017)",
// Size
height: 400,
width: 800,
marginLeft: 50,
marginRight: 50
})
```
|
Acest exemplu introductiv prezintă doar o cantitate foarte mică din ceea ce puteți face cu observabil. Dacă începeți să faceți mai multe parcele în observabil, veți observa că există o mulțime de moduri diferite de a face lucrurile. De exemplu, puteți edita etichetele axei folosind Plot.AxisX() funcționați în loc de în x argument. Puteți utiliza, de asemenea, o altă bibliotecă în întregime (cum ar fi D3) pentru a crea un complot de împrăștiere. Și din moment ce observabilul este bazat pe JavaScript, puteți utiliza, de asemenea, CSS pentru a edita stilul elementelor de complot sau pentru a adăuga efecte de hover. În ceea ce privește interactivitatea, puteți adăuga cu ușurință meniuri derulante sau glisoare pentru a complota diferite subseturi ale datelor dvs., folosind Observable Inputs (Core) Biblioteca.
Una dintre celelalte caracteristici frumoase ale observabilului este că, dacă vedeți un complot complicat care vă place, este destul de simplu să importați caietul care îl creează și să înlocuiască datele cu ale dvs. Consultați quarto.org/docs/interactive/ojs/examples/population pentru un exemplu de importare a unei diagrame Sunburst.
Salvarea unei imagini statice
Când creați un complot folosind observabil în documentul dvs. Quarto, imaginile sunt redate ca SVG. Cu toate acestea, este posibil să doriți, de asemenea, să salvați un fișier de imagine static sau raster (cum ar fi un PNG) pentru a partaja pe social media, de exemplu. Desigur, cea mai simplă cale ar putea fi să luați pur și simplu o captură de ecran. Dar îl puteți automatiza folosind webshot() Funcție din {webshot2} pachet și folosind selectori CSS pentru a capta ieșirea de celule observabile cu selector = ".cell-output.cell-output-display".
Resurse suplimentare