Bitnet B1.58 2B4T depășește rivali precum Llama, Gemma și Qwen în sarcini comune
Ce s -a întâmplat? Microsoft a introdus BitNet B1.58 2B4T, un nou tip de model de limbaj mare conceput pentru o eficiență excepțională. Spre deosebire de modelele AI convenționale care se bazează pe numere cu punct flotant pe 16 sau 32 de biți pentru a reprezenta fiecare greutate, BitNET folosește doar trei valori discrete: -1, 0 sau +1. Această abordare, cunoscută sub denumirea de cuantificare ternară, permite stocarea fiecărei greutăți în doar 1,58 biți. Rezultatul este un model care reduce dramatic consumul de memorie și poate rula mult mai ușor pe hardware-ul standard, fără a necesita GPU-urile de înaltă calitate necesare de obicei pentru AI pe scară largă.
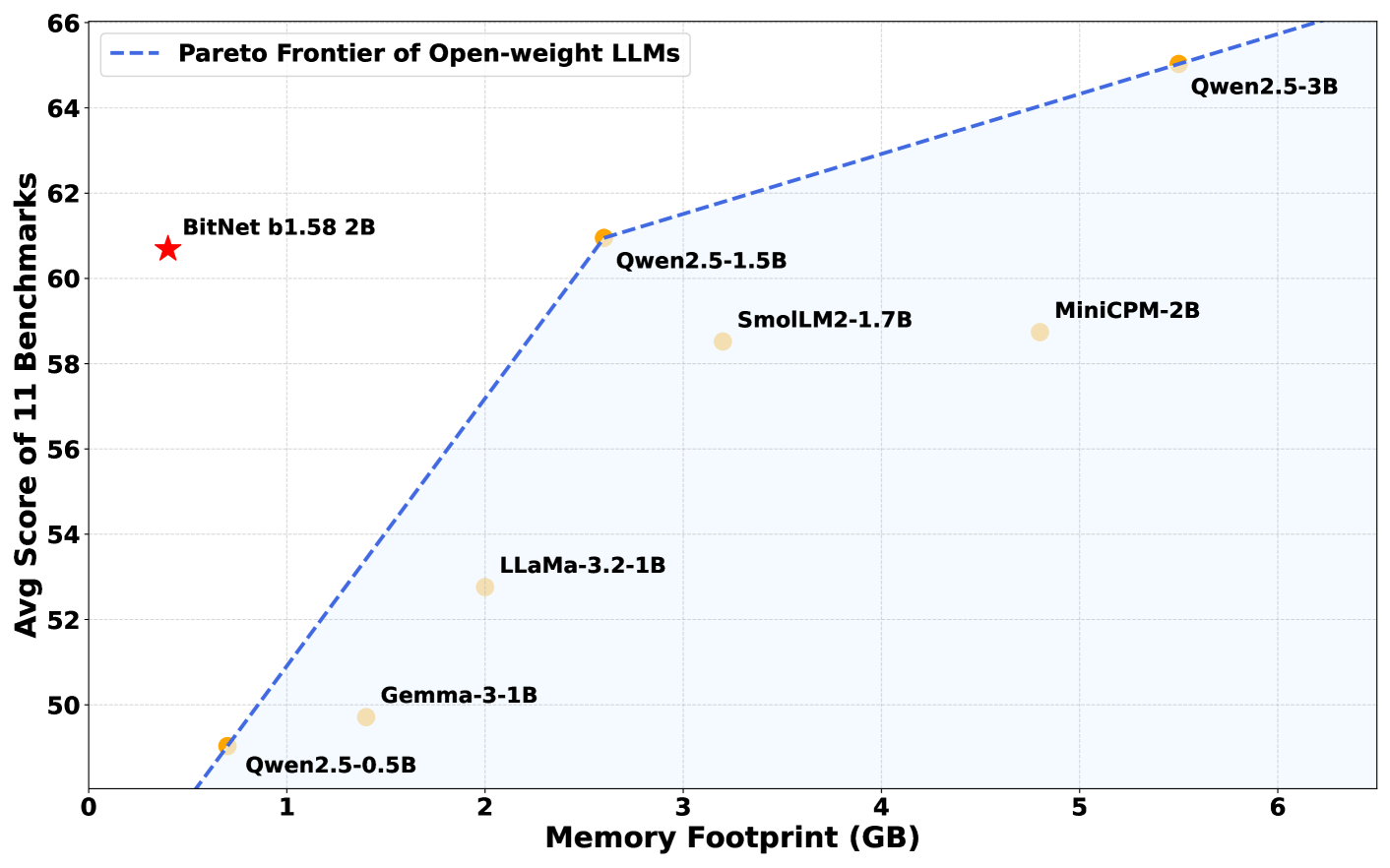
Modelul BitNET B1.58 2B4T a fost dezvoltat de grupul general de inteligență artificială Microsoft și conține doi miliarde de parametri – valori interne care permit modelului să înțeleagă și să genereze limbaj. Pentru a compensa greutățile sale cu precizie scăzută, modelul a fost instruit pe un set de date masiv de patru trilioane de jetoane, aproximativ echivalent cu conținutul a 33 de milioane de cărți. Această pregătire extinsă permite BitNET să funcționeze la egalitate cu – sau în unele cazuri, mai bine decât – alte modele de top de dimensiuni similare, cum ar fi meta -ul 3,2 1b, Google GEMMA 3 1B și QWEN 2,5 1,5 BOOGLE.
În testele de referință, BitNet B1.58 2B4T a demonstrat o performanță puternică într-o varietate de sarcini, inclusiv probleme de matematică de școală și întrebări care necesită raționament bun simț. În anumite evaluări, chiar și -a depășit concurenții.
Ceea ce diferențiază cu adevărat Bitnet este eficiența memoriei sale. Modelul necesită doar 400 MB de memorie, mai puțin de o treime din ceea ce modelele comparabile au nevoie de obicei. Drept urmare, acesta poate funcționa fără probleme pe procesoare standard, inclusiv cipul M2 de la Apple, fără a se baza pe GPU-uri de înaltă calitate sau pe hardware-ul AI specializat.
Acest nivel de eficiență este posibil de un cadru software personalizat numit bitnet.cpp, care este optimizat pentru a profita din plin de greutățile ternare ale modelului. Cadrul asigură o performanță rapidă și ușoară pe dispozitivele de calcul de zi cu zi.
Bibliotecile AI standard, cum ar fi îmbrățișarea Transformers Face’s nu oferă aceleași avantaje de performanță ca BitNET B1.58 2B4T, ceea ce face ca utilizarea caderului BitNet.CPP personalizat să fie esențială. Disponibil pe GitHub, cadrul este în prezent optimizat pentru procesoare, dar suportul pentru alte tipuri de procesor este planificat în actualizările viitoare.
Ideea reducerii preciziei modelului pentru a economisi memoria nu este nouă, deoarece cercetătorii au explorat de mult timp compresia modelului. Cu toate acestea, majoritatea încercărilor anterioare au implicat transformarea modelelor de precizie completă după antrenament, adesea cu costul exactității. Bitnet B1.58 2B4T adoptă o abordare diferită: este instruit de la sol folosind doar trei valori de greutate (-1, 0 și +1). Acest lucru îi permite să evite multe dintre pierderile de performanță observate în metodele anterioare.
Această schimbare are implicații semnificative. Rularea unor modele mari de AI necesită de obicei hardware puternic și energie considerabilă, factori care determină costurile și impactul asupra mediului. Deoarece BitNet se bazează pe calcule extrem de simple – în mare parte completări în loc de multiplicații – consumă mult mai puțină energie.
Cercetătorii Microsoft estimează că folosește cu 85 până la 96 % mai puțină energie decât modelele comparabile cu precizie completă. Acest lucru ar putea deschide ușa pentru a rula AI avansat direct pe dispozitivele personale, fără a fi nevoie de supercomputere bazate pe cloud.
Acestea fiind spuse, BitNet B1.58 2B4T are unele limitări. În prezent, acceptă doar hardware specific și necesită cadrul BitNet.cpp personalizat. Fereastra de context – cantitatea de text pe care o poate procesa simultan – este mai mică decât cea a celor mai avansate modele.
Cercetătorii încă investighează de ce modelul funcționează atât de bine cu o astfel de arhitectură simplificată. Lucrările viitoare își propune să -și extindă capacitățile, inclusiv suportul pentru mai multe limbi și intrări de text mai lungi.