(Acest articol a fost publicat pentru prima dată pe R pe statistici și rși a contribuit cu drag la R-Bloggers). (Puteți raporta problema despre conținutul de pe această pagină aici)
Doriți să vă împărtășiți conținutul pe R-Bloggers? Faceți clic aici dacă aveți un blog sau aici dacă nu.
Motivație
Întârzierile epidemiologice informează despre timpul dintre două evenimente bine definite legate de o boală. Intervalul serial (SI) al unei boli infecțioase este definit ca timpul dintre debutul simptomelor într -un caz primar (infector) și debutul simptomelor într -un caz secundar (infectee). Este o cantitate de întârziere epidemiologică utilizată pe scară largă și joacă un rol central în modelele matematice/statistice ale transmiterii bolilor. Există o legătură strânsă între numărul de reproducere (numărul mediu de infecții secundare generate de un individ infectat) și intervalul de serie. Prin urmare, obținerea de cunoștințe exacte despre distribuția SI este esențială pentru a obține o înțelegere clară a dinamicii de transmisie în timpul focarelor. Timeurile debutului simptomelor pentru perechile de infecție infectoare pot fi obținute din datele listei de linie, iar observațiile constau de obicei din datele calendaristice. Din perspectivă matematică, este mai convenabil să lucrați cu numere decât cu datele calendaristului, iar acestea din urmă sunt de obicei transformate în numere întregi de dragul analizei statistice.
Principala provocare atunci când lucrați cu datele SI este cenzurarea în sensul că timpii de debut exact ai simptomelor sunt de obicei neobservate și cunoscute doar că au avut loc între două puncte de timp. Dacă rezoluția de timp a unui moment raportat al debutului bolii este o zi calendaristică, de exemplu, 15 iulie, nu există suficiente informații pentru a determina timpul exact al debutului bolii în acea zi. Ca atare, se presupune că debutul simptomelor a avut loc între 15 iulie și 16 iulie și spunem că datele de intervale seriale sunt cenzurate de interval. Figura de mai jos ilustrează structura grosieră a datelor SI care adaugă un strat de complexitate problemei de estimare.
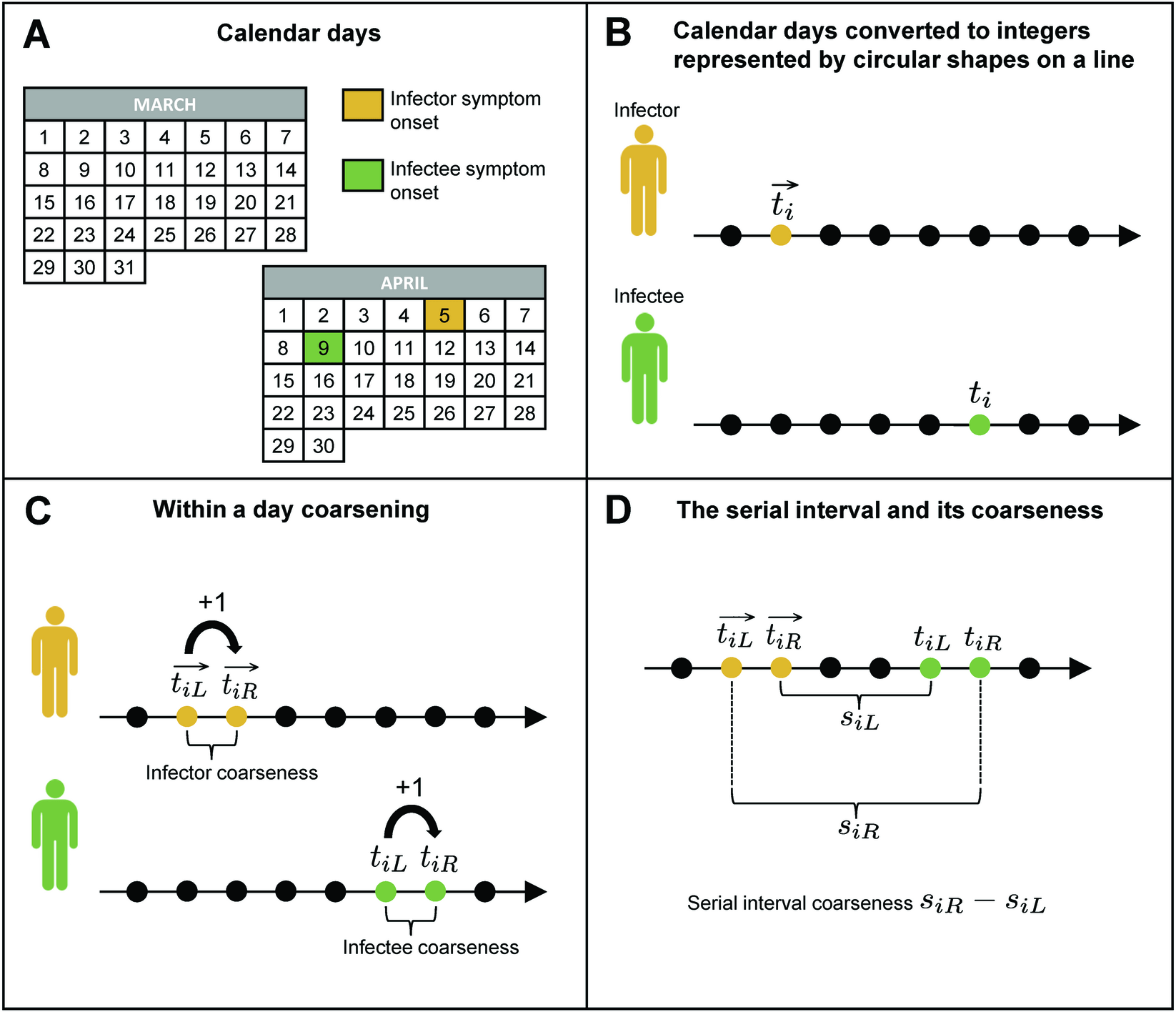
Sursa: Gressani O, Hens N. (2025). Estimarea intervalului serial nonparametric cu amestecuri uniforme. PLOS COMPECT BIOL 21 (8): E1013338.
install.packages("devtools")
devtools::install_github("oswaldogressani/EpiDelays")
Date simulate
estimSI() Rutina pachetului Epidelays poate fi utilizată pentru a calcula estimări nonparametrice (estimări punctuale cu erori standard și intervale de încredere) ale diferitelor caracteristici ale intervalului de serie (de exemplu, media, mediana, abaterea standard). Rutina este simplă de utilizat și necesită doar două intrări:
-
x: Un cadru de date cu (n ) rânduri (corespunzătoare numărului de perechi de transmisie pentru care sunt disponibile date de debut ale bolii) și două coloane care conțin limita inferioară a ferestrei SI (s_ {il} ) (prima coloană) și limita superioară a ferestrei SI (s_ {ir} ) (a doua coloană). -
nboot: Un număr întreg pentru dimensiunea eșantionului de bootstrap (implicit este 2000) utilizat pentru a construi ( (90 %) şi (95 %)) intervale de încredere (CSI).
Începem prin a ilustra utilizarea estimSI() pe date simulate. simSI() Rutina poate fi utilizată pentru a simula datele de intervale artificiale în serie, cu ferestrele SI având o lățime (grosime) de cel puțin două zile. Se presupune că distribuția Si țintă de bază are o distribuție gaussiană cu medie muS și abatere standard sdS care trebuie specificate de utilizator. Codul de mai jos poate fi utilizat pentru a genera (n = 15 ) Ferestre Si dintr -o distribuție gaussiană cu o medie de (3 ) zile și abatere standard de (2 ) zile. Mai multe detalii cu privire la mecanismul de generare a datelor pot fi găsite în articol.
set.seed(2025) simdata <- simSI(muS = 3, sdS = 2, n = 15) gt::gt(round(simdata, 2))
| s | SL | sr | SW |
|---|---|---|---|
| 4.24 | 3 | 5 | 2 |
| 3.07 | 2 | 4 | 2 |
| 4.55 | 4 | 6 | 2 |
| 5.54 | 5 | 7 | 2 |
| 3.74 | 3 | 5 | 2 |
| 2.67 | 2 | 4 | 2 |
| 3.79 | 3 | 5 | 2 |
| 2.84 | 2 | 4 | 2 |
| 2.31 | 1 | 5 | 4 |
| 4.40 | 3 | 6 | 3 |
| 2.21 | 1 | 3 | 2 |
| -0.51 | -2 | 1 | 3 |
| 2.16 | 1 | 3 | 2 |
| 4.53 | 2 | 5 | 3 |
| 5.13 | 3 | 7 | 4 |
Prima coloană a setului de date simulat conține adevărata valoare (neobservată) a intervalului de serie generat din distribuția Gaussiană aleasă. A doua și a treia coloană conțin limita stângă și dreapta a ferestrei SI (sl şi sr) În cele din urmă, ultima coloană conține lățimea ferestrei SI observate, adică sw=sr-sl. Distribuția Si țintă de bază este specificată a fi gaussiană cu o medie de (3 ) zile și abatere standard de (2 ) zile. A 5 -a, 25, 75 și 95 de cantități ale acestei din urmă distribuție sunt:
round(qnorm(p = c(0.05, 0.25, 0.75, 0.95), mean = 3, sd = 2), 1) ## (1) -0.3 1.7 4.3 6.3
Acum creăm un cadru de date care conține sl şi sr și folosiți -l pe acesta din urmă ca intrare în estimSI() rutină. Estimările nonparametrice ale diferitelor caracteristici SI pot fi accesate $npestim$.
xdf <- data.frame(sl = simdata$sl, sr = simdata$sr) SIfit <- estimSI(x = xdf, nboot = 2000) gt::gt(round(SIfit$npestim, 1), rownames_to_stub = TRUE )
| medie | SD | Q0.05 | Q0.25 | Q0.5 | Q0.75 | Q0.95 | |
|---|---|---|---|---|---|---|---|
| punct | 3.4 | 1.7 | 0,3 | 2.5 | 3.5 | 4.6 | 6.0 |
| SE | 0,4 | 0,3 | 1.1 | 0,4 | 0,3 | 0,4 | 0,5 |
| CI90L | 2.8 | 1.1 | -1.3 | 1.8 | 2.9 | 3.9 | 5.0 |
| CI90R | 4.0 | 2.1 | 2.1 | 3.2 | 4.1 | 5.2 | 6.6 |
| CI95L | 2.7 | 1.1 | -1.3 | 1.5 | 2.8 | 3.8 | 4.9 |
| CI95R | 4.2 | 2.2 | 2.1 | 3.3 | 4.2 | 5.4 | 6.6 |
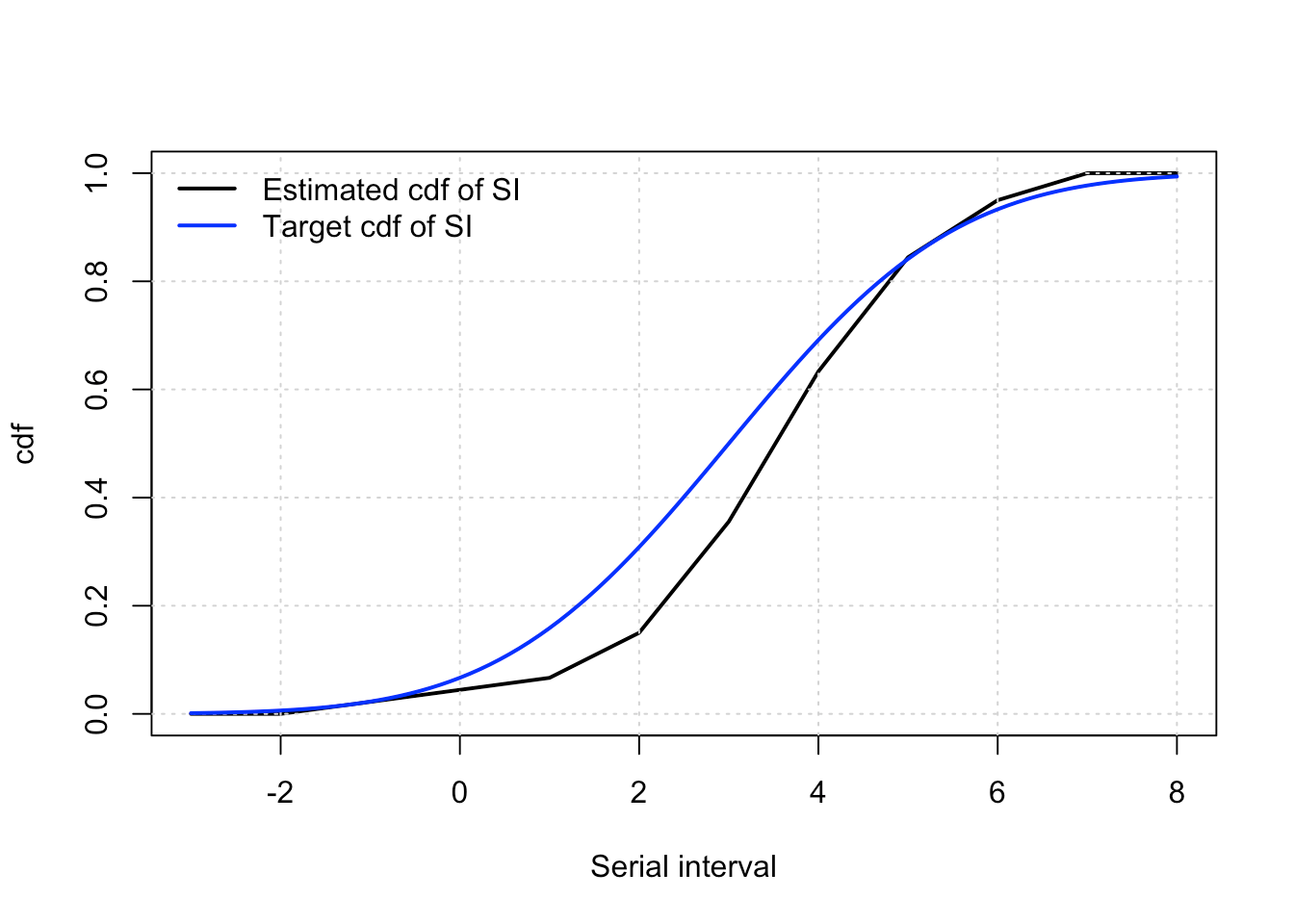
Ieșirea arată estimările punctului (punct), erorile standard (SE) și limitele intervalelor de încredere (CI) pentru media intervalului serial, abaterea standard (SD) și a 5 -a, 25, 50, 75 și 95th Quantiles dentorate de Q0.05, Q0.25, etc. Putem complota, de asemenea, funcția de distribuție cumulativă estimată (CDF). Calitatea potrivirii va depinde de obicei de dimensiunea eșantionului (n ) și pe gradul de grosime prezent în date. Rețineți că metodologia nonparametrică se ocupă în mod natural de valorile SI negative.
sl <- simdata$sl
sr <- simdata$sr
Fhat <- function(s) (1 / SIfit$n) * sum((s - sl) / (sr - sl) * (s >= sl & s <= sr) + (s > sr))
sf <- seq(-3, 8, length = 100)
plot(sf, sapply(sf, Fhat), type = "l", lwd = 2, xlab = "Serial interval", ylab = "cdf")
grid()
lines(sf, pnorm(sf, mean = 3, sd = 2), col = "blue", lwd = 2)
legend("topleft", c("Estimated cdf of SI", "Target cdf of SI"), col = c("black", "blue"), lwd = c(2, 2), bty = "n")
![]()
Date reale
Lessler și colab. (2009) partajează un set de date care conține ferestre cu intervale seriale obținute din (n = 16 ) perechi de infecție infector pentru gripă A (2009 H1N1 Gripalenza) la o școală din New York. Ferestrele SI sunt disponibile direct de la apendicele suplimentare a ultimei referințe și sunt codificate într -un cadru de date xNY. Se obțin apoi estimări nonparametrice ale caracteristicilor intervalului în serie estimSI().
xNY <- data.frame(sl = c(1, 1, 1, 0, 0, 4, 2, 3, 0, 3, 0, 3, 4, 1, 3, 3), sr = c(3, 3, 3, 2, 2, 6, 4, 5, 2, 5, 2, 5, 6, 3, 5, 5)) set.seed(123) SIfitNY <- estimSI(xNY, nboot = 2000) gt::gt(round(SIfitNY$npestim, 1), rownames_to_stub = TRUE )
| medie | SD | Q0.05 | Q0.25 | Q0.5 | Q0.75 | Q0.95 | |
|---|---|---|---|---|---|---|---|
| punct | 2.8 | 1.5 | 0,4 | 1.5 | 2.8 | 4.1 | 5.2 |
| SE | 0,3 | 0,1 | 0,2 | 0,4 | 0,6 | 0,4 | 0,3 |
| CI90L | 2.2 | 1.3 | 0,2 | 1.1 | 1.8 | 3.2 | 4.7 |
| CI90R | 3.4 | 1.7 | 1.1 | 2.2 | 3.7 | 4.6 | 5.6 |
| CI95L | 2.1 | 1.2 | 0,2 | 1.0 | 1.8 | 3.0 | 4.6 |
| CI95R | 3.5 | 1.7 | 1.1 | 2.5 | 3.8 | 4.7 | 5.7 |
Cititorii interesați pot găsi mai multe exemple de date reale în Gressani și Hens (2025) și să afle despre punctele forte și limitările acestei noi metodologii nonparametrice pentru estimarea intervalului în serie.