(Acest articol a fost publicat pentru prima dată pe R funcționeazăși a contribuit cu drag la R-Bloggers). (Puteți raporta problema despre conținutul de pe această pagină aici)
Doriți să vă împărtășiți conținutul pe R-Bloggers? Faceți clic aici dacă aveți un blog sau aici dacă nu.
Toamna trecută, coautorii mei Stephanie Zimmer, Rebecca Powell și am lansat explorarea analizei complexe a datelor sondajului folosind R. La începutul lunii august, am avut bucuria de a învăța un atelier bazat pe cartea de la utilizator! 2025.
Unul dintre exemplele noastre preferate atât în carte, cât și în atelier provine de la American National Election Studies (ANES), un proiect de lungă durată de la Universitatea Stanford și Universitatea din Michigan, susținută de Fundația Națională de Știință. Începând cu 1948, ANES a câștigat sondaje aproape la fiecare doi ani, ceea ce îl face una dintre cele mai bogate resurse pentru studierea opiniei publice și a comportamentului de vot la alegerile americane. Datele acoperă totul, de la afilierea partidului până la încrederea în guvern și sunt concepute cu atenție pentru a reprezenta populația de votare.
La doar câteva zile de la întoarcerea de la utilizator!, Am fost încântat să văd că noul set de date ANES 2024 a fost lansat!
Lansarea completă a seriei de timp ANES 2024 #Data este acum disponibilă. Mai multe detalii aici: ElectionStudies.org/anes-announc..
(imagine sau încorporat)
– Studii electorale naționale americane (@ElectionStudies.BSky.Social) 12 august 2025 la 12:24 pm
Datele sondajului precum ANE nu sunt la fel de simple ca un eșantion simplu aleatoriu. Unele grupuri sunt supraevaluate intenționat, altele sunt mai greu de atins și nu fiecare respondent are aceeași probabilitate de a fi inclus. Pentru a corecta acest lucru, sondajele oferă „greutăți” sau numere care ne spun cât de mult ar trebui să „numere” fiecare răspuns la estimarea rezultatelor pentru întreaga populație.
Dacă ignorăm aceste greutăți și calculăm procentele brute, riscăm să tragem concluzii greșite. Acolo vin pachetele {Survey} și {Srvyr}: gestionează greutăți, straturi și clustere în culise, astfel încât estimările noastre reflectă în mod corespunzător designul sondajului.
Așadar, să trecem prin cum puteți începe să analizați acest set de date în R cu pachetele {Survey} și {Srvyr}. Pentru mai multă profunzime, capitolul de începere a cărții noastre este un însoțitor la îndemână.
Descărcați datele
Mergeți pe site -ul Studiilor Electorale și apucați versiunea CSV a studiului din seria de timp 2024. Descărcarea vine ca un fișier zip care include atât setul de date, cât și documentația.
Încărcați pachete și date
Vom folosi Tidyverse pentru Wrangling și {Survey} plus {Srvyr} pentru analiză:
library(tidyverse)
library(survey)
library(srvyr)
anes_2024 <-
read_csv("anes_timeseries_2024_csv_20250808.csv")
Examinați documentația
Revizuirea documentației sondajului este o parte critică a analizei sondajului. Materialele ANES includ detalii despre eșantion, ponderare și cod.
Eşantion
Eșantionul din 2024 a fost proiectat pentru a reprezenta cetățenii americani cu vârsta de 18 ani sau mai mult. Respondenții au fost recrutați atât din probe personale, cât și din web, cu note atente despre eligibilitate și excluderi.
Cartea de cod
CODEBOOK decodează numele variabile în ceva care poate fi citit de oameni.

Iată două variabile pe care le vom folosi:
V240002b: Mod de interviu: post-alegeri: Această variabilă surprinde modul în care respondentul a finalizat majoritatea sondajului post-electoral.- -7. Parital insuficient, interviu șters
- -6. Fără interviu post
-
- Față în față (FTF)
-
- Internet (Web)
-
- Hârtie (PAPI)
-
- Telefon
-
- Video
V241229: Pre: Cât de des are încredere guvernul din Washington pentru a face ceea ce este corect (revizuit):- -9. Refuzat
- -8. Nu știu
- -1. Inaplicabil
-
- Întotdeauna
-
- De cele mai multe ori
-
- Aproximativ jumătate din timp
-
- O parte din timp
-
- Nu
Hai să ne recodificăm V241229 Pentru o analiză mai ușoară:
anes_2024_code <-
anes_2024 |>
mutate(
TrustGovernment = factor(
case_when(
V241229 == 1 ~ "Always",
V241229 == 2 ~ "Most of the time",
V241229 == 3 ~ "About half the time",
V241229 == 4 ~ "Some of the time",
V241229 == 5 ~ "Never",
.default = NA
),
levels = c("Always", "Most of the time", "About half the time", "Some of the time", "Never")
)
)
Vedeți mai multe despre cărțile de cod.
Creați un obiect de proiectare
Obiectul de proiectare este coloana vertebrală a analizei sondajului. Datele sondajului folosesc greutăți, straturi și clustere pentru a reflecta populația. Asta înseamnă că avem nevoie de un obiect de proiectare a sondajului înainte de a rula orice analize, iar obiectul de proiectare spune R care greutăți să utilizeze, modul în care respondenții au fost eșantionați și ce ajustări sunt necesare. Fără ea, orice estimări pe care le calculăm ar putea fi înșelătoare.
Pentru a construi obiectul de proiectare, avem nevoie de trei ingrediente cheie:
- Greutăți: pentru a vă asigura că rezultatele reflectă populația.
- STRATA: Grupuri utilizate în eșantionare pentru a asigura acoperirea.
- Clustere (PSU): unități primare de eșantionare, cum ar fi gospodăriile sau adresele.
Găsirea greutății potrivite
Documentarea ANES listează ce variabile de greutate merg cu ce eșantion:
![]()
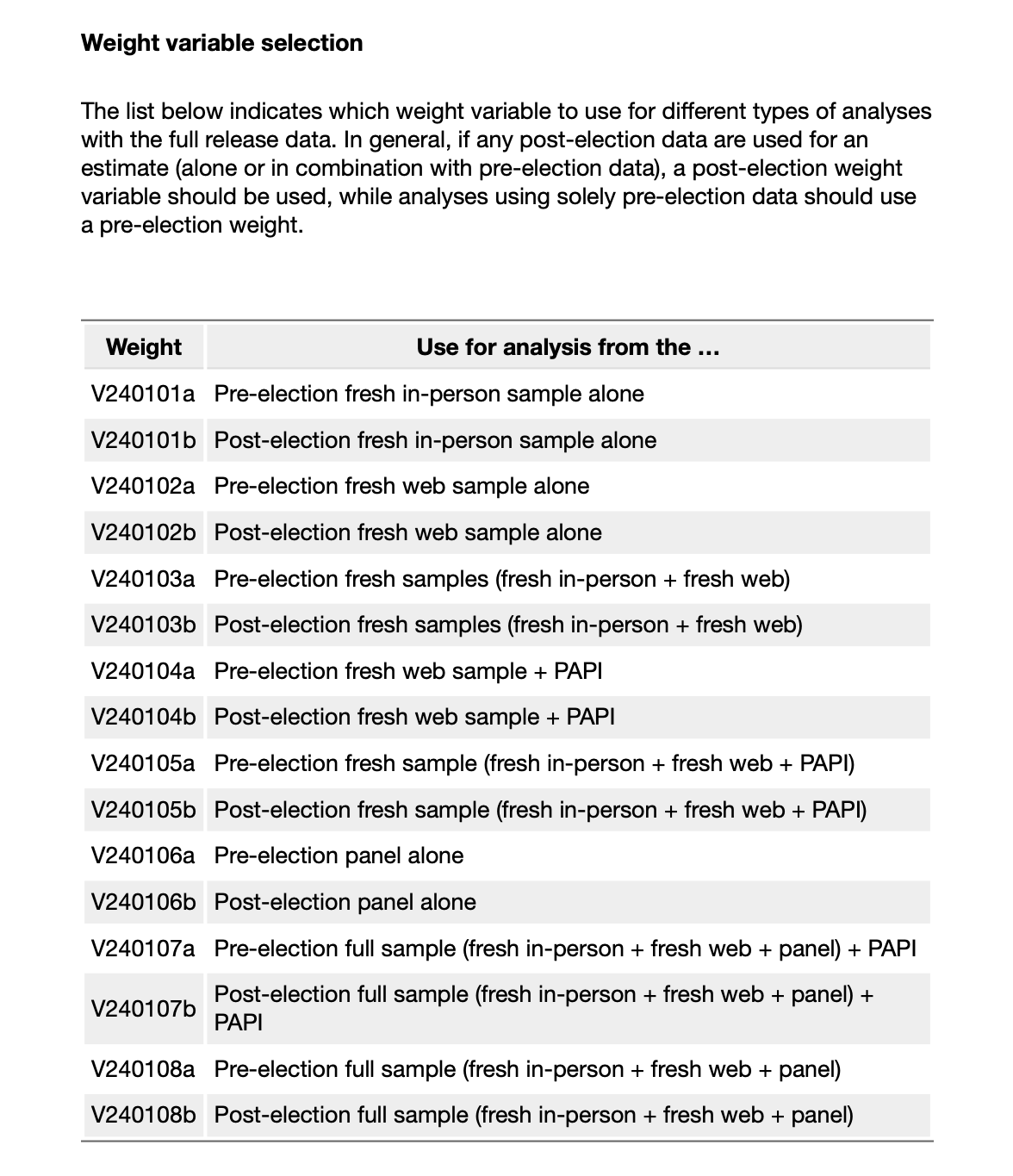
Din moment ce ne uităm la eșantionul proaspăt post-electoral, vom folosi variabila de greutate V240101b.
O notă importantă: greutățile ANES se adaugă la dimensiunea eșantionului, nu la dimensiunea populației. Să confirmăm:
anes_2024_code |> filter(V240101b > 0) |> summarize(sum = sum(V240101b))
# A tibble: 1 × 1
sum
1 925
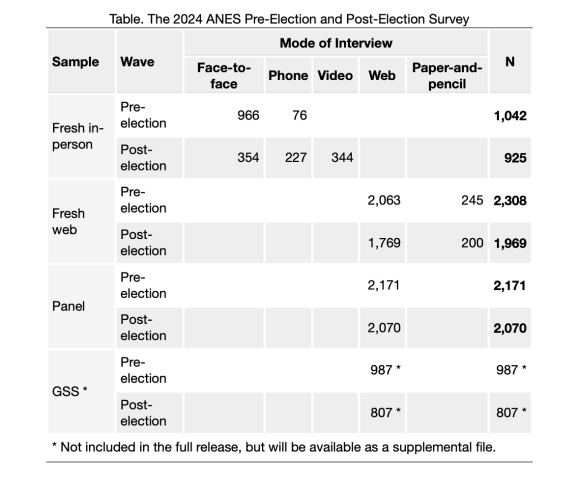
Acest lucru se potrivește cu 925 Respondenții au prezentat în tabelul de eșantion al documentației.
![]()
Reglarea populației
Dacă dorim să facem inferențe despre întreaga populație din SUA, trebuie să ajustăm greutățile. Populația țintă pentru acest eșantion este de aproximativ 232,5 milioane de cetățeni americani în vârstă de 18 ani sau mai mari, dar acesta este doar un număr dur. Conform documentației, pentru ceva mai precis, putem trage numărul de populație din estimările de un an de un an din 2023 American Community Survey.
Mulțumesc, Stephanie, pentru că a scris codul pentru estimările populației!
library(tidycensus)
varlist_2023 <- load_variables(2023, "acs1")
citizen_pop_18_plus <-
get_acs(
geography = "state",
variable = "S2901_C01_001",
year = 2023,
survey = "acs1"
)
pums_vars_2023 <- pums_variables |>
as_tibble() |>
filter(year == 2023, survey == "acs1")
pums_vars_2023 |>
filter(var_code %in% c("AGEP", "TYPEHUGQ", "CIT")) |>
select(var_code, var_label, val_min, val_max, val_label) |>
print(n = 50)
# Find those who are 18+ and in group quarters
get_citizen_pop_18_plus_gq <- function(state) {
get_pums(
variables = c("AGEP", "TYPEHUGQ"),
state = state,
year = 2023,
survey = "acs1",
variables_filter = list(
TYPEHUGQ = 2:3 ,
CIT = 1:4,
AGEP = (18:200)
)
) |>
summarize(estimate = sum(PWGTP), .by = STATE)
}
citizen_pop_18_plus_gq_l <- c(state.abb, "DC") |>
map(get_citizen_pop_18_plus_gq)
citizen_pop_18_plus_gq_df <-
citizen_pop_18_plus_gq_l |>
list_rbind() |>
rename(estimate_gq = estimate)
state_pops <- citizen_pop_18_plus |>
select(GEOID, NAME, estimate_tot = estimate) |>
full_join(citizen_pop_18_plus_gq_df, by = c("GEOID" = "STATE")) |>
filter(NAME != "Puerto Rico") |>
mutate(estimate_scope = estimate_tot - estimate_gq)
# Total without AK and HI
targetpop <-
state_pops |>
filter(!GEOID %in% c("02", "15")) |>
summarize(TargetPop = sum(estimate_scope))
# Total with AK and HI
state_pops |>
summarize(TargetPop = sum(estimate_scope))
Populația țintă estimată (targetpop) pentru 2024 este 232.449.541. Acum putem rescala greutățile ANES, astfel încât acestea să se adauge la dimensiunea populației:
anes_adjwgt <- anes_2024_code |> mutate(Weight = V240101b / sum(V240101b, na.rm = TRUE) * targetpop)
Straturi și clustere
Documentația ne spune, de asemenea, ce variabile Strata și PSU (cluster) se împerechează cu fiecare greutate.
![]()
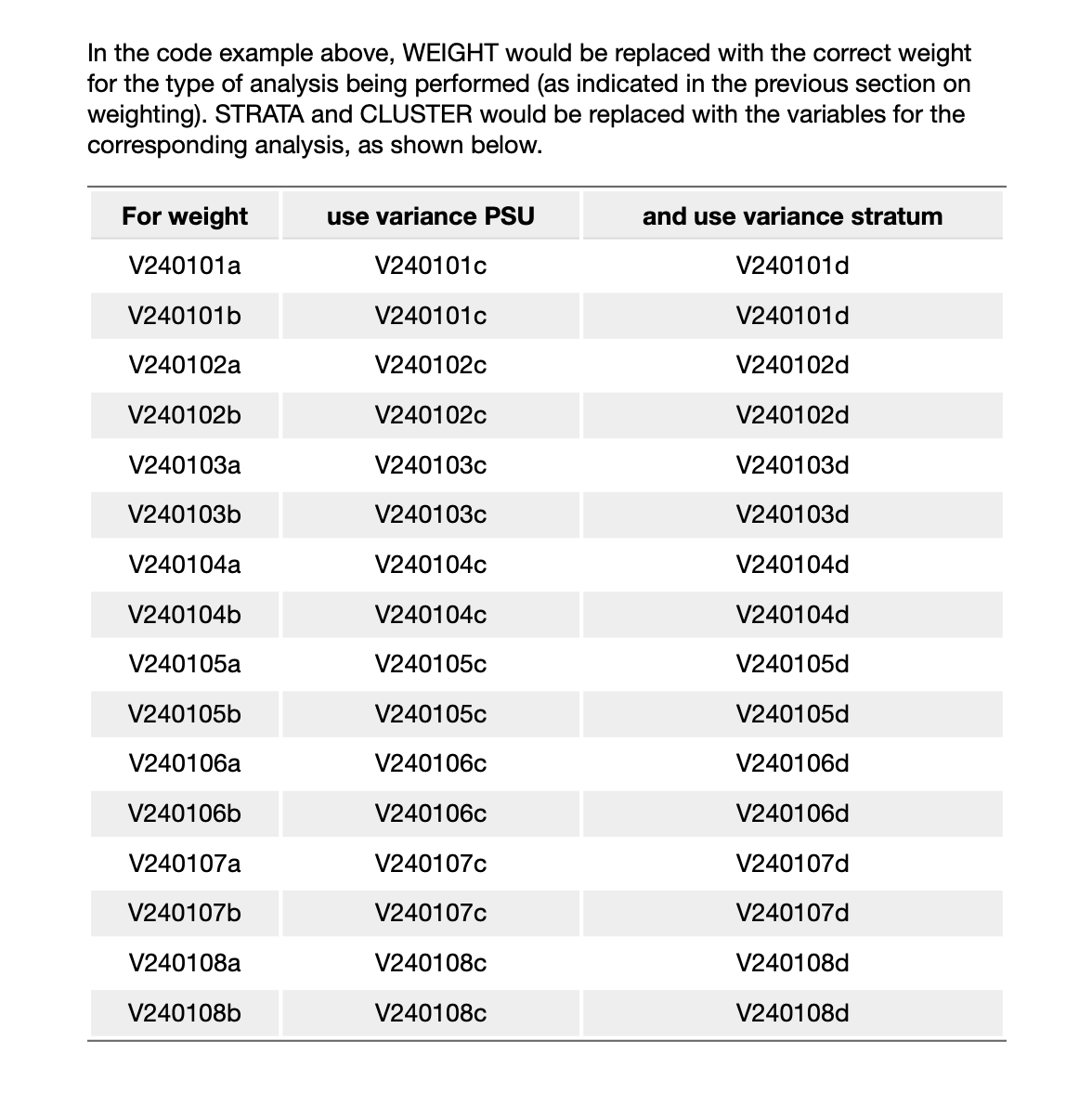
Pentru V240101b, acestea sunt:
- STRATA:
V240101d - PSU:
V240101c
Mai multe despre proiectarea eșantionării pot fi găsite în acest capitol.
Punând totul împreună
În cele din urmă, putem construi obiectul de proiectare. De asemenea, vom filtra respondenții care au finalizat efectiv interviul post-electoral în persoană (V240002b == 1):
options(survey.lonely.psu = "adjust")
anes_des <- anes_adjwgt |>
filter(V240002b == 1) |>
as_survey_design(
weights = Weight,
strata = V240101d,
ids = V240101c,
nest = TRUE
)
anes_des
Și acolo mergem! anes_des este obiectul nostru de proiectare a sondajului complet specificat. De aici, o folosim, astfel încât fiecare estimare pe care o calculăm în mod corespunzător reflectă proiectarea sondajului.
Analizați datele
Acum pentru partea distractivă! Să vedem cum oamenii au răspuns la întrebarea guvernului de încredere:
(
trustgov <- anes_des |>
drop_na(TrustGovernment) |>
group_by(TrustGovernment) |>
summarize(p = survey_prop(vartype = "ci")) |>
mutate(Variable = "V241229") |>
rename(Answer = TrustGovernment) |>
select(Variable, everything())
)
# A tibble: 5 × 5 Variable Answer p p_low p_upp1 V241229 Always 0.00774 0.00288 0.0206 2 V241229 Most of the time 0.174 0.122 0.242 3 V241229 About half the time 0.283 0.225 0.351 4 V241229 Some of the time 0.402 0.341 0.465 5 V241229 Never 0.133 0.0857 0.201
Și un complot rapid:
![]()
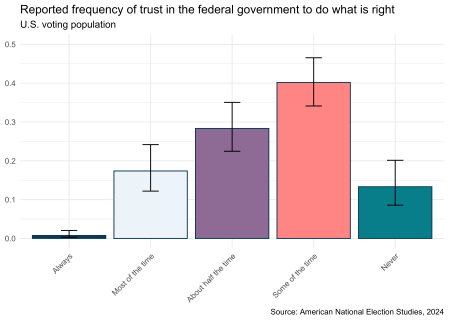
Rezultatele arată cât de variată este încrederea publică, doar o mică parte din respondenți spunând că au întotdeauna încredere în guvern.
De asemenea, putem analiza datele de subgrupuri:
anes_des <-
anes_des |>
mutate(Gender = factor(
case_when(V241550 == 1 ~ "Male", V241550 == 2 ~ "Female", .default = NA),
levels = c("Male", "Female")
))
(
trustgov_gender <- anes_des |>
drop_na(Gender, TrustGovernment) |>
group_by(Gender, TrustGovernment) |>
summarize(p = survey_prop(vartype = "ci")) |>
mutate(Variable = "V241229") |>
rename(Answer = TrustGovernment) |>
select(Variable, everything())
)
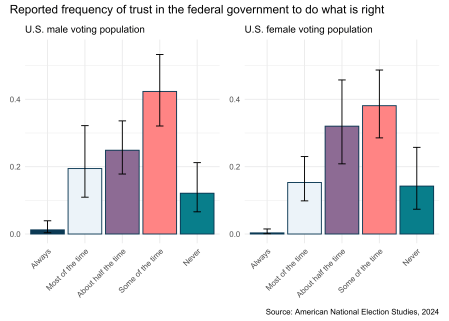
# A tibble: 10 × 6 # Groups: Gender (2) Variable Gender Answer p p_low p_upp1 V241229 Male Always 0.0123 0.00379 0.0393 2 V241229 Male Most of the time 0.194 0.109 0.322 3 V241229 Male About half the time 0.249 0.178 0.336 4 V241229 Male Some of the time 0.423 0.321 0.533 5 V241229 Male Never 0.121 0.0659 0.212 6 V241229 Female Always 0.00336 0.000744 0.0150 7 V241229 Female Most of the time 0.153 0.0984 0.230 8 V241229 Female About half the time 0.320 0.208 0.457 9 V241229 Female Some of the time 0.381 0.285 0.487 10 V241229 Female Never 0.142 0.0736 0.257
![]()
Învelire
Eliberarea ANES 2024 este plină de informații, iar ceea ce am acoperit aici este doar începutul. Cu sute de variabile între atitudini, demografii și comportamente, veți găsi cu siguranță întrebări care merită explorate.
Dacă încercați setul de date, mi -ar plăcea să aud ce descoperiți. Simțiți -vă liber să vă împărtășiți propriile analize sau vizualizări!
Găsește -mă pe Bluesky: @ivelasq3
Consultați mai multe resurse: