(Acest articol a fost publicat pentru prima dată pe R.IRESMI.NETși a contribuit cu drag la R-Bloggers). (Puteți raporta problema despre conținutul de pe această pagină aici)
Doriți să vă împărtășiți conținutul pe R-Bloggers? Faceți clic aici dacă aveți un blog sau aici dacă nu.

Problema zilei de naștere este un rezultat clasic matematic contra-intuitiv cu privire la probabilitatea ca două persoane, într-un grup, să aibă aceeași zi de naștere. Soluția formală este prea complexă pentru mine, dar pot folosi simulări pentru a afla …
Configurare
# parameters -------------------------------------------------------------- max_group_size <- 60 # we work on groups from 1 to max_group_size individuals iterations <- 1e5 # for a good precision use more than 1e4 cores <- 10 # number of CPU cores to use # config ------------------------------------------------------------------ library(dplyr) library(ggplot2) library(tibble) library(furrr) library(purrr) plan(multisession, workers = cores)
Utilități
Două funcții pentru a găsi coliziunea datei de naștere într -un grup simulat și repetarea acestei simulări pentru dimensiuni diferite ale grupului.
#' detect a collision in a group of simulated birthdays
#'
#' bissextiles years are taken into account
#'
#' @param group_size (int) : group size
#' @returns (lgl) : is there at least 2 people with the same birthday date ?
birthday_collision <- function(group_size) {
days <- sample(c(365, 366), size = 1, prob = c(.7575, .2425))
birthdays <- sample(1:days, group_size, replace = TRUE)
collisions <- group_size - length(unique(birthdays))
return(collisions > 0)
}
#' simulate many groups and compute the collision probability
#'
#' @param group_size (int) : group size
#' @param iterations (int) : number of simulations to run
#' @returns (dbl) : collision probability
collision_prob <- function(group_size, iterations = 1e5) {
res <- vector(length = iterations) |>
map_lgl((x) birthday_collision(group_size))
return(sum(res) / length(res))
}
#' Convert scientific number to plotmath expression
#'
#' @param x (num) : a number in scientific format like 1e5
#'
#' @returns : plotmath expresion
scientific_10 <- function(x) {
parse(text = gsub("e\+*", " %*% 10^", scales::scientific_format()(x))) }
Hai să -l rulăm! (în paralel)
# simulate for groups with different size
groups <- 1:max_group_size |>
future_map_dbl(
.options = furrr_options(seed = TRUE)) |>
imap((x, y) tibble(group_size = y, proba = x)) |>
list_rbind()
# find the 50% limit
pcent50 <- groups |>
filter(proba >= .5) |>
slice_head(n = 1)
Și complotează -l …
groups |>
ggplot(aes(group_size, proba)) +
geom_step(direction = "hv") +
geom_segment(data = pcent50, aes(xend = group_size, yend = 0), linetype = 3) +
geom_segment(data = pcent50, aes(xend = 0, yend = proba), linetype = 3) +
annotate(geom = "text", x = pcent50((1, "group_size")), y = -.02,
size = 3,
label = pcent50((1, "group_size"))) +
scale_x_continuous(breaks = scales::breaks_pretty()) +
scale_y_continuous(breaks = scales::breaks_pretty(),
labels = scales::label_percent(decimal.mark = ",",
suffix = " %")) +
labs(title = "Probability that at least two people share the same birthday",
subtitle = "in a group",
x = "group size",
y = "probablity",
caption = bquote(atop("https://r.iresmi.net/",
simulations~with~
.(parse(text = scientific_10(iterations))((1)))~
iterations))) +
theme_minimal() +
theme(plot.caption = element_text(size = 6),
plot.background = element_rect(fill = "white"))

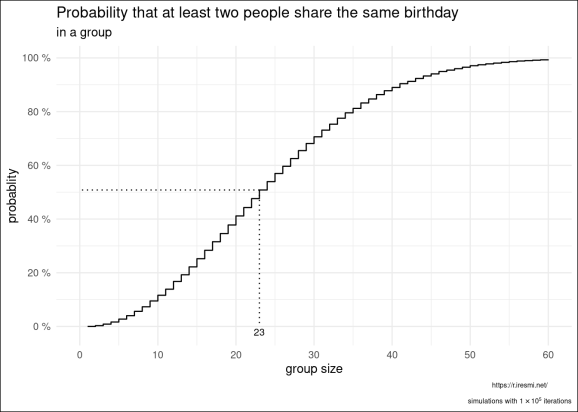
Figura 1: Rezultatele simulării
Putem vedea că un grup de 23 de persoane este suficient pentru a obține o probabilitate de 50% pentru a avea cel puțin două persoane cu aceeași dată de naștere.