(Acest articol a fost publicat pentru prima dată pe pacha.dev/blogși a contribuit cu drag la R-Bloggers). (Puteți raporta problema despre conținutul de pe această pagină aici)
Doriți să vă împărtășiți conținutul pe R-Bloggers? Faceți clic aici dacă aveți un blog sau aici dacă nu.
Din cauza întârzierilor cu plata bursei mele, dacă această postare vă este utilă, vă cer cu drag o donație minimă pentru a -mi cumpăra o cafea. Acesta va fi folosit pentru a continua eforturile mele open source. Explicația completă este aici: un mesaj personal de la un contribuabil open source. Dacă cântați la chitară electrică, același haos de bursă m -a determinat să -mi transform pedalele de chitară și kiturile de bricolaj hobby într -o afacere și le puteți verifica aici.
A trebuit să citesc câteva fișiere XLSX (Microsoft Excel) pentru un proiect de consultanță pe care îl conduc acum în Chile, când am găsit un sever Problema organizării datelor. În loc să codifice municipalitățile dintr -un district ca:
Distrito Circunscripción Provincial Comuna 14 Talagante Talagante 14 Talagante El Monte 14 Talagante Isla de Maipo 14 Talagante Padre Hurtado 14 Talagante Peñaflor ...
Unele foi din fișiere au folosit mai multe culori de fundal pentru a indica districtul la care fiecare municipalitate („Comuna”) aparține atunci când vine vorba de a defini cine este Congresul pentru acea municipalitate (Map Congressperson-municipalitate este un 1-to-many atunci când primarul hărții primar-municipalitate este de la 1 la 1).
Acest mod de a reprezenta informații este rău pentru toată lumea. Nu este clar pentru cititor și este mai mult consumator de timp pentru care a creat fișierul. O resursă bună despre organizarea de date adecvată cu foi de calcul este organizarea de date în foile de calcul de Karl Broman și Kara Woo pe care le sugerez studenților mei în fiecare semestru.
Gândiți -vă la setul de date GapMinder. Dacă în loc de asta:
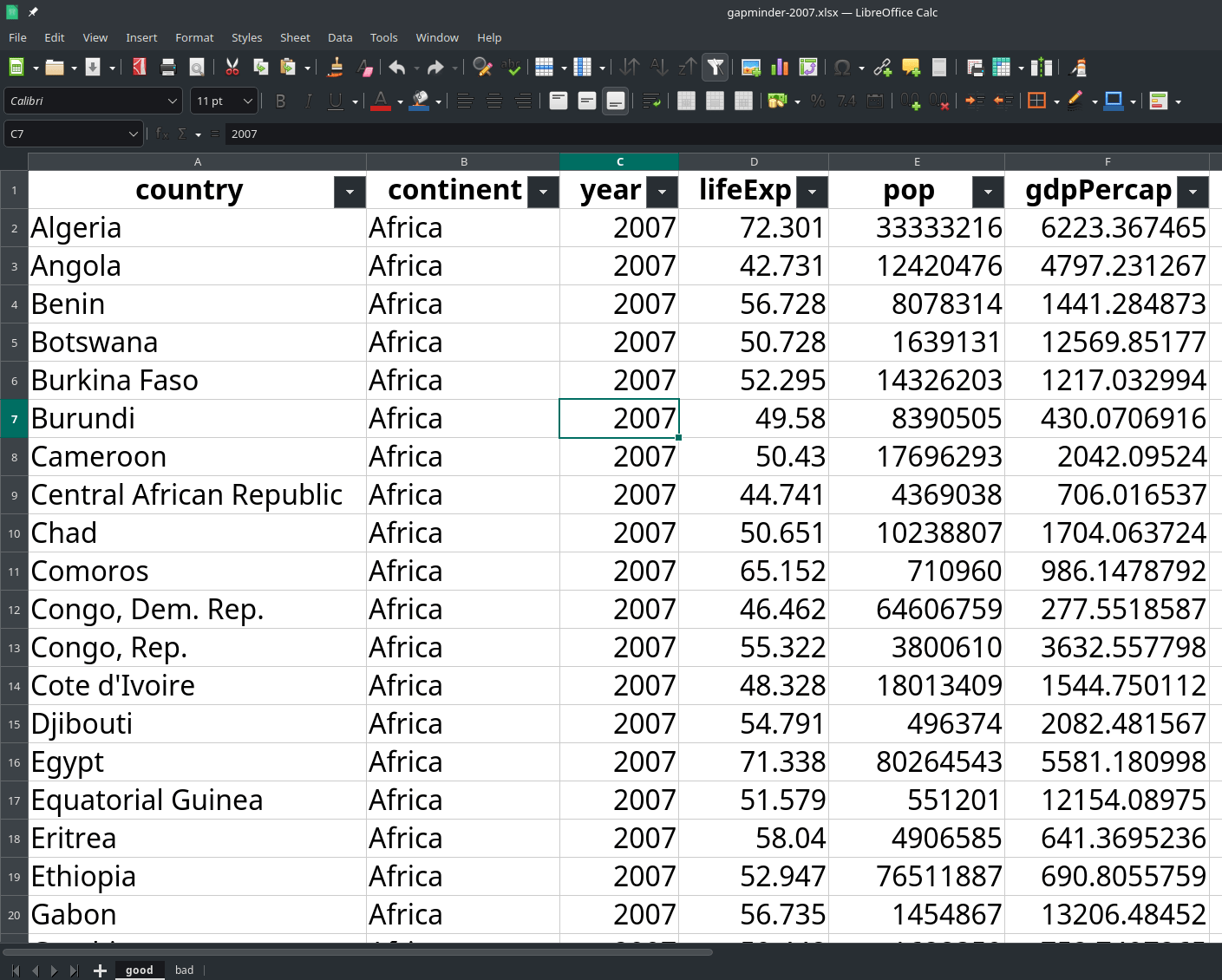
Obțineți asta:
![]()
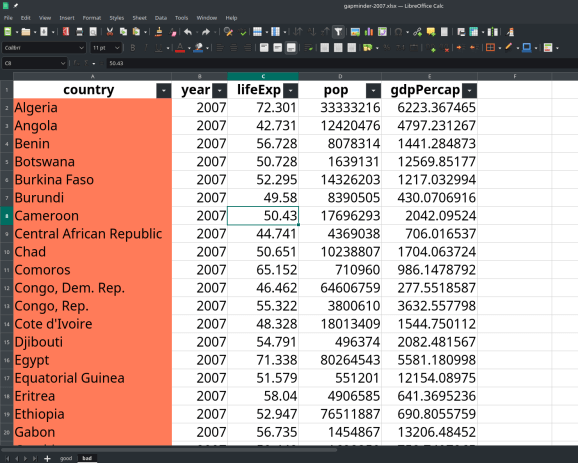
Apoi, aveți nevoie de informații suplimentare care nu sunt prezente în fișier pentru a cunoaște continentul pentru fiecare țară. Acest lucru nu este atât de rău, dar este pentru informații mai specifice (de exemplu, gândiți -vă la codul telefonic internațional).
Am căutat online și am găsit câteva soluții greoaie de acum aproape zece ani folosind pachetul XLSX. Nu sunt mulțumit de acestea, am folosit cunoștințele mele C ++ obținute în ECE244 și am făcut unele modificări la pachetul Readxl.
Schimbarea adaugă un plus extract_colors parametru la read_excel()și permite să facă acest lucru:
# extract_colors = FALSE (default) good_data <- read_excel(file, sheet = "good") > good_data # A tibble: 142 × 6 country continent year lifeExp pop gdpPercap1 Algeria Africa 2007 72.3 33333216 6223. 2 Angola Africa 2007 42.7 12420476 4797. 3 Benin Africa 2007 56.7 8078314 1441. 4 Botswana Africa 2007 50.7 1639131 12570. 5 Burkina Faso Africa 2007 52.3 14326203 1217. 6 Burundi Africa 2007 49.6 8390505 430. 7 Cameroon Africa 2007 50.4 17696293 2042. 8 Central African Republic Africa 2007 44.7 4369038 706. 9 Chad Africa 2007 50.7 10238807 1704. 10 Comoros Africa 2007 65.2 710960 986. # ℹ 132 more rows # ℹ Use `print(n = ...)` to see more rows bad_data <- read_excel(file, sheet = "bad", extract_colors = TRUE) > bad_data # A tibble: 142 × 6 country year lifeExp pop gdpPercap country_bg 1 Algeria 2007 72.3 33333216 6223. #FF6600 2 Angola 2007 42.7 12420476 4797. #FF6600 3 Benin 2007 56.7 8078314 1441. #FF6600 4 Botswana 2007 50.7 1639131 12570. #FF6600 5 Burkina Faso 2007 52.3 14326203 1217. #FF6600 6 Burundi 2007 49.6 8390505 430. #FF6600 7 Cameroon 2007 50.4 17696293 2042. #FF6600 8 Central African Republic 2007 44.7 4369038 706. #FF6600 9 Chad 2007 50.7 10238807 1704. #FF6600 10 Comoros 2007 65.2 710960 986. #FF6600
În acest fel, putem grupa țările cumva, iar una dintre numeroasele posibilități este de a converti country_bg la un factor cu cinci categorii (de exemplu, o culoare pe continent) cu:
library(dplyr) bad_data %>% mutate(country_bg = as.factor(country_bg))
sau potrivirea codurilor hexagonale cu un șir:
bad_data %>%
inner_join(
bad_data %>%
distinct(country_bg) %>%
mutate(
continent = case_when(
country_bg == "#FF6600" ~ "Asia",
country_bg == "#99CCFF" ~ "Europe",
country_bg == "#FFFFCC" ~ "Africa",
country_bg == "#993366" ~ "Americas",
country_bg == "#666699" ~ "Oceania",
TRUE ~ NA_character_
)
)
)
Sper că acest lucru este util!