(Acest articol a fost publicat pentru prima dată pe John Russellși a contribuit cu drag la R-Bloggers). (Puteți raporta problema despre conținutul de pe această pagină aici)
Doriți să vă împărtășiți conținutul pe R-Bloggers? Faceți clic aici dacă aveți un blog sau aici dacă nu.
Distribuții grafice și cartografice
Îmi lucrez marți ordonate și am vrut să fac ceva care să combine atât datele spațiale, cât și cele temporale. Setul de date Frogid din săptămâna 35 din 2025 are ambele, așa că haideți să aruncăm o privire.
Aceasta este, de asemenea, prima mea postare folosind Positron peste Rstudio, așa că vom vedea cum merge!
Încărcarea pachetelor necesare și a datelor
Cod în r
library(tidyverse) library(rnaturalearth) library(sf) library(patchwork) tuesdata <- tidytuesdayR::tt_load(2025, week = 35) frogID <- tuesdata$frogID_data frognames <- tuesdata$frog_names view(frogID) view(frognames)
Îmi place cum Positron arată automat distribuții de date atunci când vizualizați un date de date! Privind cele două date de date, se pare că frogID are locațiile și momentele observațiilor, în timp ce frognames Are câteva informații taxonomice suplimentare, care poate fi plăcut de alăturat. Un lucru ciudat este că numele științifice din frogID Aveți câteva informații suplimentare după numele speciei, așa că va trebui să curățați un pic.
Alăturarea datelor de date și curățarea datelor
Cod în r
frogID <- frogID |>
left_join(frognames |>
select(scientificName, subfamily,tribe) |>
mutate(scientificName = word(scientificName, 1, 2)) |>
distinct(), by = "scientificName")
Distribuții peste spațiu
Prima distribuție la care vreau să mă uit este distribuția spațială a observațiilor de broaște. Datele sunt totul din Australia, așa că haideți să tragem o hartă a Australiei și să complotăm punctele de pe ea.
Cod în r
# pull the map of australia australia <- ne_states(country = "australia", returnclass = "sf")
De aici, este doar o chestiune de a complota punctele de pe hartă. Voi colora punctele de trib și le voi face un pic transparent, astfel încât să putem vedea zone cu mai multe observații.
Cod în r
## map the frogs over australia by density
australia |>
ggplot() +
geom_sf(fill = "lightgrey") +
geom_point(data = frogID |>
filter(!is.na(tribe)),
aes(x = decimalLongitude, y = decimalLatitude, color=tribe), size = 0.5, alpha = 0.7) +
# geom_density_2d(data = frogID, aes(x = decimalLongitude, y = decimalLatitude), alpha = 0.6, contour_var = "count") +
theme_void() +
theme(legend.position = "bottom",
legend.text = element_text(size=12)) +
labs(title = "Frog Species in Australia",
subtitle = "Locations of various frog species across Australia",
caption = "Tidy Tuesday (2025, Week 35)",
color="") +
coord_sf(xlim = c(110, 155), ylim = c(-45, -10))
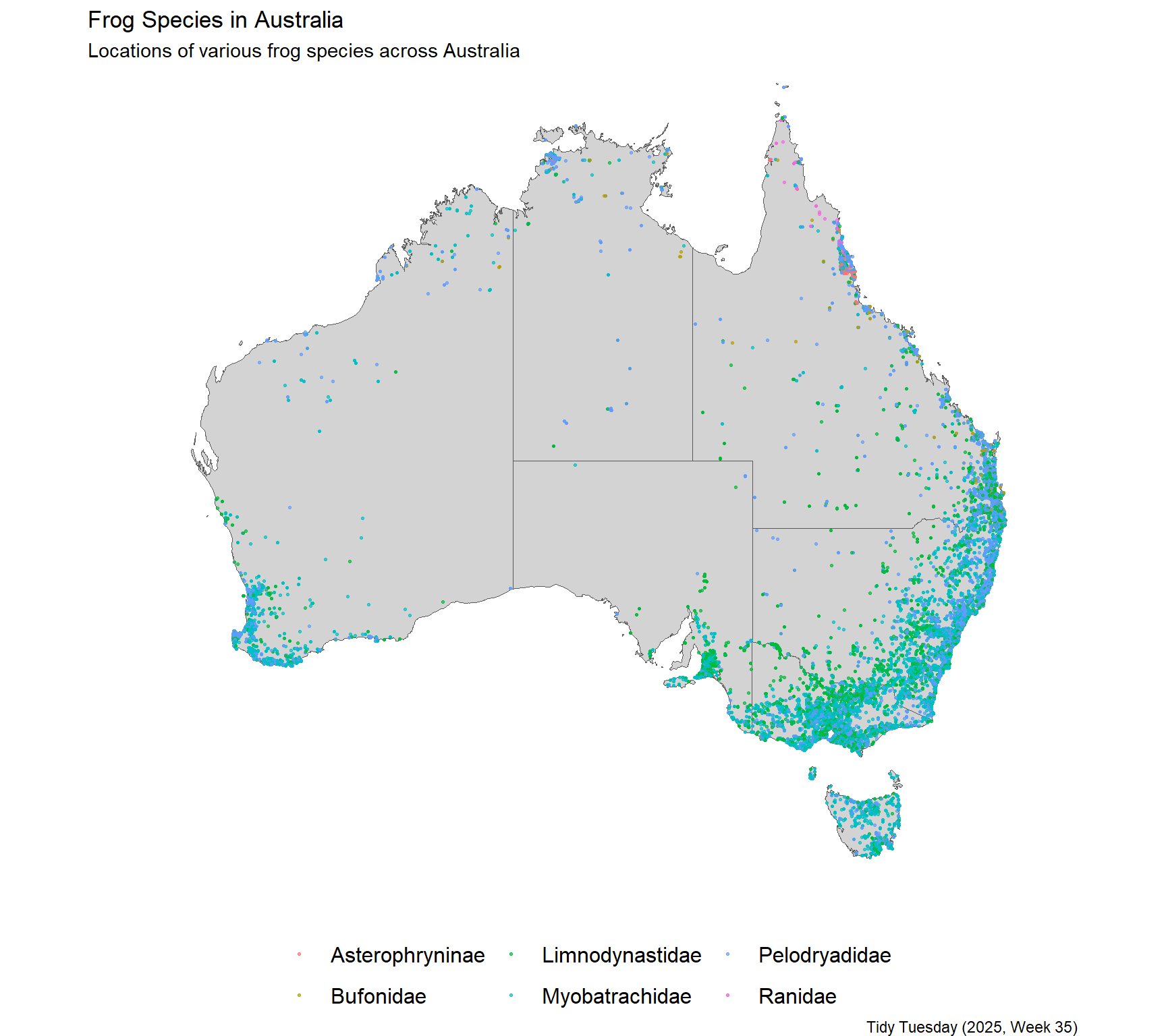
În mod surprinzător, majoritatea observațiilor sunt de -a lungul coastei, unde climatul este probabil mai ospitalier pentru broaște, dar și pentru oamenii de știință cetățeni (deci pot exista unele prejudecăți în date)!
Uitați -vă la distribuirea identificărilor la oră din zi
Am fost, de asemenea, curios de distribuția temporală a identificărilor de broaște. eventTime Coloana are momentul zilei în care s -a făcut identificarea, așa că haideți să ne uităm la asta până la ora zilei.
Cod în r
day <- frogID |>
filter(!is.na(hour(eventTime)),
!is.na(tribe)) |>
ggplot(aes(x = hour(eventTime), fill = tribe)) +
geom_histogram(binwidth = 1, position = "stack", color = "black") +
theme_minimal() +
labs(title = "Frog Identifications by Hour of Day",
x = "Hour of Day",
y = "Number of Identifications",
fill = "",
caption = "Tidy Tuesday (2025, Week 35)") +
scale_x_continuous(breaks = 0:23) +
theme(legend.position = "bottom")
day
![]()
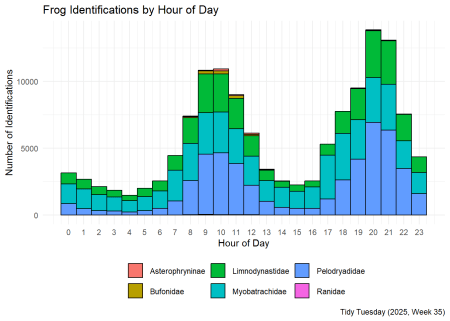
Interesant este că există două vârfuri în identificare, unul în jurul orei 9/10 și unul în jurul orei 8 pm. Acest lucru nu se potrivește destul de mult cu Dawn și amurg, care sunt probabil vremurile în care broaștele sunt cele mai active, dar s -ar putea să reflecte atunci când oamenii sunt cel mai probabil să fie afară și să caute broaște.
Uită -te la distribuția identificărilor pe lună
În cele din urmă, să ne uităm la distribuția identificărilor de broaște pe lună. Acest lucru ne va oferi o idee despre momentul în care oamenii sunt cel mai probabil să identifice broaște.
Cod în r
month <- frogID |>
filter(!is.na(month(eventDate)),
!is.na(tribe)) |>
ggplot(aes(x = month(eventDate), fill = tribe)) +
geom_histogram(binwidth = 1, position = "stack", color = "black") +
theme_minimal() +
labs(title = "Frog Identifications by Month",
x = "Month",
y = "Number of Identifications",
fill = "",
caption = "Tidy Tuesday (2025, Week 35)") +
scale_x_continuous(breaks = 1:12, labels = month.abb) +
theme(legend.position = "bottom")
month
![]()
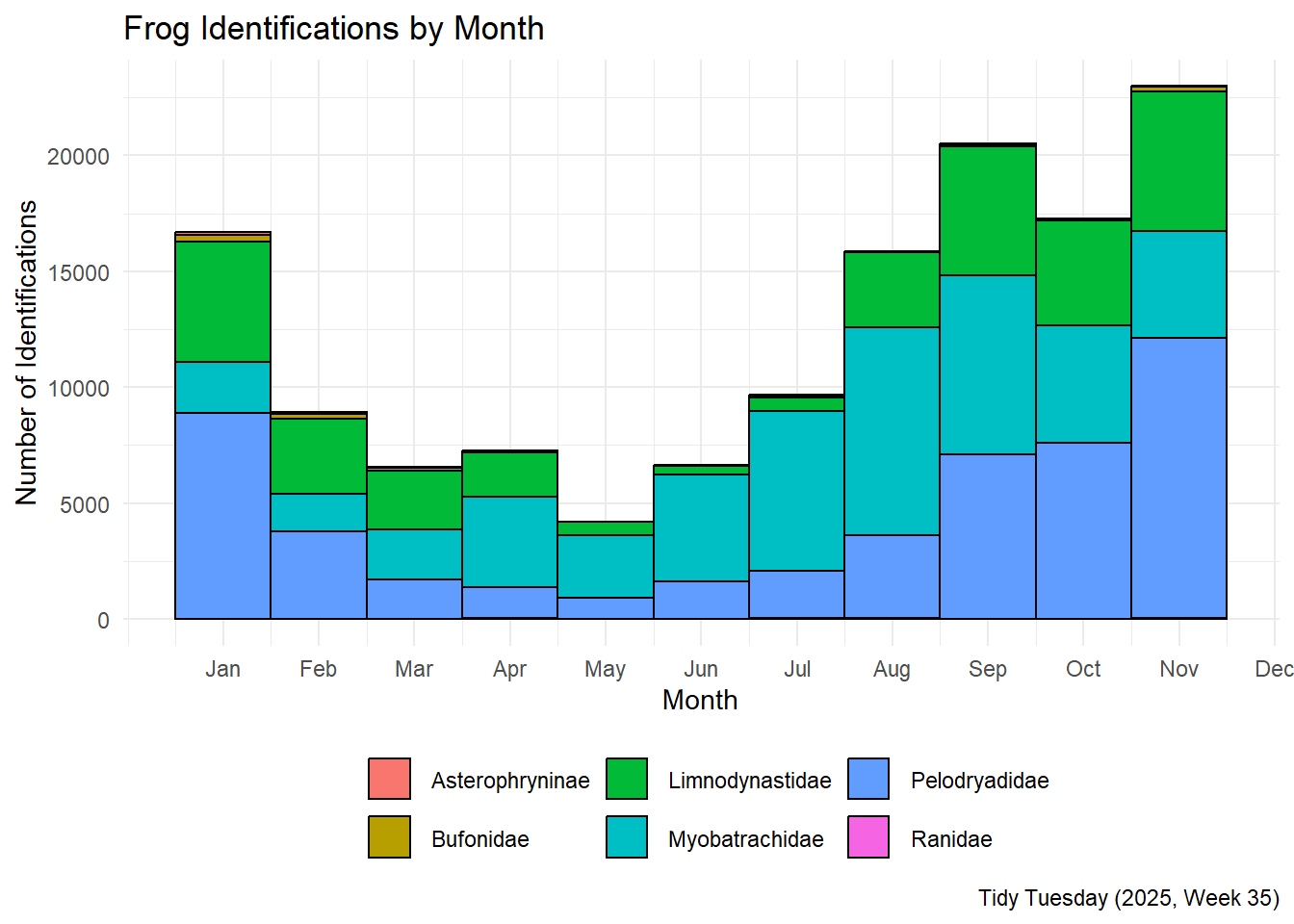
În mod surprinzător, lunile de primăvară și vară (octombrie -februarie) au cele mai multe identificări, ceea ce este probabil atunci când broaștele sunt cele mai active și când oamenii sunt mai susceptibili să fie în afara lor.
Combinarea parcelelor temporale
Cod în r
collected <- (month + labs(caption="")) + day + plot_layout(ncol = 2, guides = "collect") & theme(legend.position = "bottom") collected
![]()
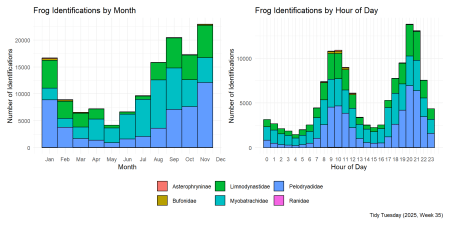
Acest lucru atrage cele două parcele temporale într -o singură figură, ceea ce este puțin mai ușor de comparat.
Citare
Citarea Bibtex:
@online{russell2025,
author = {Russell, John},
title = {Tidy {Tuesday} - {Frog} {Distributions} in {Time} and
{Space}},
date = {2025-09-02},
url = {https://drjohnrussell.github.io/posts/2025-09-02-time-and-frogs/},
langid = {en}
}
Pentru atribuire, vă rugăm să citați această lucrare ca:
Russell, Ioan. 2025. „Marți ordonate – distribuții de broaște în timp și spațiu.” 2 septembrie 2025.