În lumea asigurărilor și a gestionării riscurilor financiare, calcularea cerinței de capital de solvabilitate (SCR) pentru riscul de capitaluri proprii ar putea fi o sarcină intensivă din punct de vedere calculat care poate face sau rupe luarea deciziilor în timp real. Abordările tradiționale se bazează pe simulări scumpe de Monte Carlo care pot dura ore întregi, forțând practicienii să fie Dezvoltați scheme de aproximare. Dezvoltarea unei scheme de aproximare a fost un proiect Am abordat în 2007-2009 pentru teza de master în știința actuarială (a se vedea referințele de mai jos).
Ce am făcut atunci
O abordare probabilistică modernă
Astăzi, revizuiesc această aceeași provocare prin obiectivul Învățare automată probabilisticăși Obțineți expresii/aproximări funcționale în R și Python. Fascinant cum uşor S -ar putea să se uite acum!
Această abordare probabilistică oferă mai multe avantaje:
- Cuantificarea incertitudinii încorporate: Cunoașteți nu doar predicția, ci cât de încrezători ar trebui să fim
- Învățarea automată a caracteristicilor: Permiteți modelul să descopere reprezentări optime
- Rapid
Desigur, având un model funcțional de învățare automată, ne putem gândi la mai multe moduri de testare a stresului (adică obținerea analizelor What-If) aceste rezultate, pe baza modificărilor într-una (sau mai mult) din variabilele explicative
Referințe:
(scr_equity <- read.csv("ALIM4D.txt"))
| TMG | pct_actions | pvl_actions | PPE | Src_equity |
|---|---|---|---|---|
| 1.75 | 2.00 | 2.00 | 3.50 | 56471378 |
| 1.75 | 2.00 | 2.00 | 9.00 | 48531931 |
| 1.75 | 2.00 | 2.00 | 9.50 | 48558178 |
| 1.75 | 2.00 | 2.00 | 9.75 | 48570523 |
| 5.00 | 2.00 | 2.00 | 3.50 | 65111083 |
| 5.00 | 2.00 | 2.00 | 9.00 | 54433115 |
| 5.00 | 2.00 | 2.00 | 9.50 | 54436348 |
| 5.00 | 2.00 | 2.00 | 9.75 | 54526734 |
| 5.25 | 2.00 | 2.00 | 3.50 | 65244870 |
| 5.25 | 2.00 | 2.00 | 9.00 | 54325632 |
| 5.25 | 2.00 | 2.00 | 9.50 | 54387565 |
| 5.25 | 2.00 | 2.00 | 9.75 | 54418533 |
| 5.50 | 2.00 | 2.00 | 3.50 | 65396012 |
| 5.50 | 2.00 | 2.00 | 9.00 | 54239282 |
| 5.50 | 2.00 | 2.00 | 9.50 | 54302132 |
| 5.50 | 2.00 | 2.00 | 9.75 | 54333018 |
| 5.75 | 2.00 | 2.00 | 3.50 | 65581289 |
| 5.75 | 2.00 | 2.00 | 9.00 | 54168174 |
| 5.75 | 2.00 | 2.00 | 9.50 | 54209587 |
| 5.75 | 2.00 | 2.00 | 9.75 | 54210481 |
| 6.00 | 2.00 | 2.00 | 3.50 | 65785420 |
| 6.00 | 2.00 | 2.00 | 9.00 | 54042241 |
| 6.00 | 2.00 | 2.00 | 9.50 | 54103639 |
| 6.00 | 2.00 | 2.00 | 9.75 | 54134241 |
| 1.75 | 2.75 | 2.75 | 9.00 | 48435808 |
| 1.75 | 2.75 | 2.75 | 9.25 | 48446558 |
| 1.75 | 2.75 | 2.75 | 9.50 | 48459074 |
| 1.75 | 2.75 | 2.75 | 9.75 | 48473874 |
| 5.00 | 2.75 | 2.75 | 9.00 | 54501129 |
| 5.00 | 2.75 | 2.75 | 9.25 | 54531852 |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 5.75 | 6.00 | 6.00 | 9.50 | 53901737 |
| 5.75 | 6.00 | 6.00 | 9.75 | 53968463 |
| 6.00 | 6.00 | 6.00 | 3.50 | 62378886 |
| 6.00 | 6.00 | 6.00 | 9.25 | 53780562 |
| 6.00 | 6.00 | 6.00 | 9.50 | 53730182 |
| 6.00 | 6.00 | 6.00 | 9.75 | 53950814 |
| 1.75 | 6.25 | 6.25 | 3.50 | 51709654 |
| 1.75 | 6.25 | 6.25 | 9.25 | 47537722 |
| 1.75 | 6.25 | 6.25 | 9.50 | 47543381 |
| 1.75 | 6.25 | 6.25 | 9.75 | 47555017 |
| 5.00 | 6.25 | 6.25 | 3.50 | 61268505 |
| 5.00 | 6.25 | 6.25 | 9.25 | 54207189 |
| 5.00 | 6.25 | 6.25 | 9.50 | 54234608 |
| 5.00 | 6.25 | 6.25 | 9.75 | 54268573 |
| 5.25 | 6.25 | 6.25 | 3.50 | 61467297 |
| 5.25 | 6.25 | 6.25 | 9.25 | 54070788 |
| 5.25 | 6.25 | 6.25 | 9.50 | 54096598 |
| 5.25 | 6.25 | 6.25 | 9.75 | 54154003 |
| 5.50 | 6.25 | 6.25 | 3.50 | 61671008 |
| 5.50 | 6.25 | 6.25 | 9.25 | 53964700 |
| 5.50 | 6.25 | 6.25 | 9.50 | 53994107 |
| 5.50 | 6.25 | 6.25 | 9.75 | 54052459 |
| 5.75 | 6.25 | 6.25 | 3.50 | 61868864 |
| 5.75 | 6.25 | 6.25 | 9.25 | 53862132 |
| 5.75 | 6.25 | 6.25 | 9.50 | 53881640 |
| 5.75 | 6.25 | 6.25 | 9.75 | 53941964 |
| 6.00 | 6.25 | 6.25 | 3.50 | 62112237 |
| 6.00 | 6.25 | 6.25 | 9.25 | 53734035 |
| 6.00 | 6.25 | 6.25 | 9.50 | 53764618 |
| 6.00 | 6.25 | 6.25 | 9.75 | 53825660 |
scr_equity$SRC_Equity <- scr_equity$SRC_Equity/1e6
options(repos = c(techtonique = "https://r-packages.techtonique.net",
CRAN = "https://cloud.r-project.org"))
install.packages(c("rvfl", "learningmachine"))
set.seed(13)
train_idx <- sample(nrow(scr_equity), 0.8 * nrow(scr_equity))
X_train <- as.matrix(scr_equity(train_idx, -ncol(scr_equity)))
X_test <- as.matrix(scr_equity(-train_idx, -ncol(scr_equity)))
y_train <- scr_equity$SRC_Equity(train_idx)
y_test <- scr_equity$SRC_Equity(-train_idx)
obj <- learningmachine::Regressor$new(method = "krr", pi_method = "none")
obj$get_type()
t0 <- proc.time()(3)
obj$fit(X_train, y_train, reg_lambda = 0.1)
cat("Elapsed: ", proc.time()(3) - t0, "s n")
„Regresie”
Elapsed: 0.005 s
print(sqrt(mean((obj$predict(X_test) - y_test)^2)))
(1) 0.7250047
obj$summary(X_test, y=y_test, show_progress=TRUE)
|======================================================================| 100%
$R_squared
(1) 0.9306298
$R_squared_adj
(1) 0.9121311
$Residuals
Min. 1st Qu. Median Mean 3rd Qu. Max.
-1.097222 -0.590318 -0.051308 -0.006375 0.447859 1.660139
$citests
estimate lower upper p-value signif
tmg 0.8311760 -0.8484270 2.51077903 3.133161e-01
pct_actions -0.4845265 -0.9327082 -0.03634475 3.555821e-02 *
pvl_actions -0.4845265 -0.9327082 -0.03634475 3.555821e-02 *
ppe -2.2492137 -2.4397536 -2.05867385 6.622214e-16 ***
$signif_codes
(1) "Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1"
$effects
── Data Summary ────────────────────────
Values
Name effects
Number of rows 20
Number of columns 4
_______________________
Column type frequency:
numeric 4
________________________
Group variables None
── Variable type: numeric ──────────────────────────────────────────────────────
skim_variable mean sd p0 p25 p50 p75 p100 hist
obj <- learningmachine::Regressor$new(method = "rvfl",
nb_hidden = 3L,
pi_method = "kdesplitconformal")
t0 <- proc.time()(3)
obj$fit(X_train, y_train, reg_lambda = 0.01)
cat("Elapsed: ", proc.time()(3) - t0, "s n")
Elapsed: 0.006 s
obj$summary(X_test, y=y_test, show_progress=FALSE)
$R_squared
(1) 0.8556358
$R_squared_adj
(1) 0.8171387
$Residuals
Min. 1st Qu. Median Mean 3rd Qu. Max.
-2.1720 -1.2977 -0.8132 -0.8003 -0.3254 0.5877
$Coverage_rate
(1) 100
$citests
estimate lower upper p-value signif
tmg 179.13631 162.48868 195.78394 3.639163e-15 ***
pct_actions -73.14222 -89.12337 -57.16108 1.046939e-08 ***
pvl_actions 62.46782 46.48668 78.44896 1.199526e-07 ***
ppe -125.26721 -144.19952 -106.33490 2.223349e-11 ***
$signif_codes
(1) "Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1"
$effects
── Data Summary ────────────────────────
Values
Name effects
Number of rows 20
Number of columns 4
_______________________
Column type frequency:
numeric 4
________________________
Group variables None
── Variable type: numeric ──────────────────────────────────────────────────────
skim_variable mean sd p0 p25 p50 p75 p100 hist
obj$set_level(95)
res <- obj$predict(X = X_test)
plot(c(y_train, res$preds), type="l",
main="(Probabilistic) Out-of-sample n Equity Capital Requirement in m€",
xlab="Observation Index",
ylab="Equity Capital Requirement (m€)",
ylim = c(min(c(res$upper, res$lower, y_test, y_train)),
max(c(res$upper, res$lower, y_test, y_train))))
lines(c(y_train, res$upper), col="gray70")
lines(c(y_train, res$lower), col="gray70")
lines(c(y_train, res$preds), col = "red")
lines(c(y_train, y_test), col = "blue", lwd=2)
abline(v = length(y_train), lty=2, col="black", lwd=2)
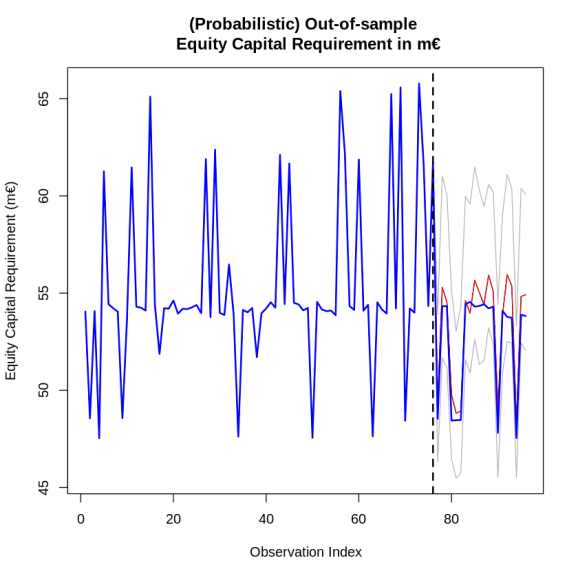
100*mean((y_test >= as.numeric(res$lower)) * (y_test <= as.numeric(res$upper)))
100
!pip install skimpy
!pip install ydata-profiling
!pip install nnetsauce
import pandas as pd
from skimpy import skim
from ydata_profiling import ProfileReport
scr_equity = pd.read_csv("ALIM4D.csv")
scr_equity('SRC_Equity') = scr_equity('SRC_Equity')/1e6
skim(scr_equity)
ProfileReport(scr_equity)
import nnetsauce as ns
import numpy as np
X, y = scr_equity.drop('SRC_Equity', axis=1), scr_equity('SRC_Equity').values
from sklearn.utils import all_estimators
from tqdm import tqdm
from sklearn.utils.multiclass import type_of_target
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from time import time
# Get all scikit-learn regressors
estimators = all_estimators(type_filter="regressor")
results_regressors = ()
seeds = (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
for i, (name, RegressorClass) in tqdm(enumerate(estimators)):
if name in ('MultiOutputRegressor', 'MultiOutputClassifier', 'StackingRegressor', 'StackingClassifier',
'VotingRegressor', 'VotingClassifier', 'TransformedTargetRegressor', 'RegressorChain',
'GradientBoostingRegressor', 'HistGradientBoostingRegressor', 'RandomForestRegressor',
'ExtraTreesRegressor', 'MLPRegressor'):
continue
for seed in seeds:
try:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=42+seed*1000)
regr = ns.PredictionInterval(obj=ns.CustomRegressor(RegressorClass()),
method="splitconformal",
level=95,
seed=312)
start = time()
regr.fit(X_train, y_train)
print(f"Elapsed: {time() - start}s")
preds = regr.predict(X_test, return_pi=True)
coverage_rate = np.mean((preds.lower<=y_test)*(preds.upper>=y_test))
rmse = np.sqrt(np.mean((preds-y_test)**2))
results_regressors.append((name, seed, coverage_rate, rmse))
except:
continue
results_df = pd.DataFrame(results_regressors, columns=('Regressor', 'Seed', 'Coverage Rate', 'RMSE'))
results_df.sort_values(by='Coverage Rate', ascending=False)
results_df.dropna(inplace=True)
results_df('logRMSE') = np.log(results_df('RMSE'))