(Acest articol a fost publicat pentru prima dată pe codificare-pastși a contribuit cu drag la R-Bloggers). (Puteți raporta problema despre conținutul de pe această pagină aici)
Doriți să vă împărtășiți conținutul pe R-Bloggers? Faceți clic aici dacă aveți un blog sau aici dacă nu.
În această postare, veți afla care este un test T și cum să îl efectuați în R. În primul rând, veți vedea o funcție simplă care vă permite să efectuați testul cu o singură linie de cod. Apoi, vom explora intuiția din spatele testului, construindu -l pas cu pas cu date despre pasagerii Titanic. Bucurați -vă de lectură!
1. Ce este un test t?
Un test T este o procedură statistică folosită pentru a verifica dacă diferența dintre două grupuri este semnificativă sau doar din cauza întâmplării. În această postare, vom analiza datele de la pasagerii din Titanic, împărțindu -le în bărbați și femei. Să presupunem că vrem să testăm ipoteza că bărbații și femeile au aceeași vârstă medie. Dacă datele noastre arată că femeile erau, în medie, cu 2 ani mai mici decât bărbații, trebuie să ne întrebăm: este o diferență reală sau s -ar fi putut întâmpla la întâmplare? Testul T ne ajută să răspundem la această întrebare.
2. De ce este important un test t?
Un test t este important atunci când dorim să tragem concluzii despre o populație pe baza unui eșantion. De exemplu, imaginați -vă că studiem demografia pasagerilor navei la începutul secolului XX și dorim să folosim eșantionul Titanic pentru a generaliza constatările unei populații mai largi de pasageri.
Desigur, astfel de inferențe pot fi părtinitoare, întrucât pasagerii titanice ar putea să nu reprezinte perfect toți pasagerii navei din acea epocă. Cu toate acestea, eșantionul poate oferi în continuare informații valoroase, atât timp cât contextul atât al eșantionului, cât și al populației este considerat cu atenție și explicat clar.
3. Pasagerii Titanicilor
Vom folosi titanic R biblioteca pentru a accesa date despre pasagerii Titanic. Mai exact, vom lucra cu un subset de pasageri conținute în titanic_train set de date. Mai jos, veți găsi codul pentru a încărca datele, pentru a calcula media și abaterea standard a vârstei pentru bărbați și femei și arătați câți pasageri sunt bărbați și femei.
content_copy
Copie
library(titanic)
data('titanic_train')
df <- titanic_train %>%
select(Sex, Age) %>%
na.omit()
df %>% group_by(Sex) %>%
summarize(mean(Age), sd(Age), n())
| Sex | Media (vârsta) | SD (vârstă) | n |
|---|---|---|---|
| femeie | 27.9 | 14.1 | 261 |
| bărbat | 30.7 | 14.7 | 453 |
Putem vedea că există o diferență de 2,8 ani între vârsta medie a bărbaților și femeilor din Titanic. Mai jos, puteți verifica, de asemenea, distribuția vârstelor.
content_copy
Copie
ggplot()+
geom_density(aes(x=df$Age, color = df$Sex), size = 0.7)+
scale_color_discrete("")+
xlab("Age")+
ylab("Density")
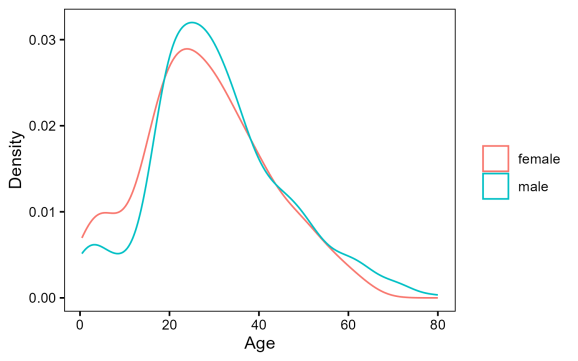
Se pare că într -adevăr distribuțiile sunt foarte similare. În acest caz, cea mai bună opțiune a noastră este să efectuăm un test T pentru a vedea dacă sunt într -adevăr atât de similare.
4. test în r
La testare poate fi efectuat într -un mod foarte ușor. Există o funcție numită t.testal cărui prim argument este o formulă, în cazul nostru, am dori să știm cum variază vârsta de la diferite genuri. Thomas Leeper a scris o explicație foarte clară despre formulele din această pagină. Important pentru noi este că formula este compusă dintr -o variabilă dependentă de stânga (vârstă), urmată de „~” și una sau mai multe variabile independente din dreapta (sex). Al doilea argument este pur și simplu DataFrame cu datele pe care dorim să le testăm. Acest test presupune că cele două probe sunt independente și că vârsta este distribuită în mod normal, pe care am confirmat -o prin graficul de densitate de mai sus.
content_copy
Copie
t.test(Age ~ Sex, data = df)

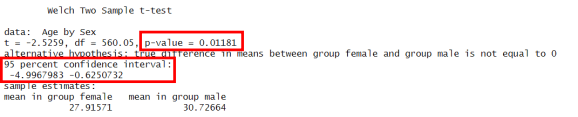
Cum să interpretezi aceste rezultate?
- Valoarea p de 0,0118 înseamnă că, dacă nu există nicio diferență în vârsta medie între pasagerii bărbați și femei (adică, dacă ipoteza nulă ar fi adevărată), ar exista doar o șansă de 1,18% de a observa o diferență la fel de mare ca cea pe care am găsit-o sau mai mare. Deoarece această valoare p este mai mică de 0,05, respingem ipoteza nulă la nivelul de încredere de 95%, ceea ce sugerează că există o diferență reală. Cu toate acestea, dacă am fi ales un nivel de încredere de 99%, nu am respinge ipoteza nulă, deoarece valoarea p este mai mare de 0,01.
- Intervalul nostru de încredere ne spune că, dacă am lua multe probe precum cel pe care îl avem, în 95% la sută din timp, am obține o diferență între medii între -0,62 și -5. Acest interval de încredere nu include 0 și, prin urmare, respingem ipoteza nulă și acceptăm ipoteza că există o diferență între vârsta medie a bărbaților și femeilor.
5. T test cu bootstrap
La testare cu Bootstrap este o modalitate bună de a înțelege conceptele necesare pentru a interpreta rezultatele testului t de mai sus. Totul se bazează pe teorema limită centrală în funcție de care, dacă trag multe probe ale unei populații și calculez media fiecărui eșantion, atunci distribuția tuturor acestor mijloace va:
(i) Urmați o distribuție normală;
(ii) media mijloacelor de eșantion va aproxima media populației;
(iii) Abaterea standard a acestei distribuții se va numi eroare standard.
În exemplul nostru, avem un eșantion de pasageri. Imaginați -vă că am putea colecta multe dintre aceste mostre. Dacă am putea face acest lucru, atunci mijloacele tuturor eșantioanelor ar aproxima parametrul populației. Bootstrap este o tehnică pentru a crea practic tot atâtea probe pe care le dorim din eșantionul nostru unic. În exemplul nostru, avem 712 vârste după eliminarea NAS. Am putea realiza 712 observații din aceste valori, permițându -le să se repete. Aceasta este ideea de bază din spatele bootstrapping -ului.
Pentru a face această procedură, vom crea o funcție care ne va reșufla cadrul de date. Prima linie de cod folosește slice_sample Pentru a selecta la întâmplare n Rânduri ale datelor noastre de date care permit să fie aleasă același rând de mai mult de o dată. Rețineți că n este numărul de rânduri ale datelor de date. După aceea, folosim dplyr Pentru a calcula media după gen. Rețineți că suntem de fapt interesați de diferența dintre media masculină și media feminină. Asta fac cele două ultime linii de cod.
content_copy
Copie
diff_means <- function(data) {
sample_df <- data %>% slice_sample(n = nrow(data), replace = TRUE)
means <- sample_df %>%
group_by(Sex) %>%
summarize(mean_age = mean(Age, na.rm = TRUE))
male_mean <- means %>% filter(Sex == "male") %>% pull(mean_age)
female_mean <- means %>% filter(Sex == "female") %>% pull(mean_age)
return(male_mean - female_mean)
}
Acum putem folosi replicate Funcție pentru a executa funcția noastră pentru n ori. Pentru scopul nostru de 1000 de ori este suficient. Rețineți că replicate Funcționează ca o buclă pentru. Cu toate acestea, înainte de a face acest lucru, să facem o mică ajustare, astfel încât să putem calcula și valoarea p. Valoarea p presupune că ipoteza nulă este adevărată. Prin urmare, înainte de a ne eșantiona datele, să facem diferența dintre mijloacele 0. Pentru asta, să scădem diferența observată, 2.81, de la vârstele tuturor bărbaților.
content_copy
Copie
df_null <- df %>%
mutate(Age = ifelse(Sex=="male", Age-2.81, Age))
set.seed(1308)
diffs <- replicate(1000, diff_means(df_null))
sd(diffs)
mean(diffs)
ggplot()+
geom_histogram(aes(x = diffs), color = "white", fill = "#2E3031")+
geom_vline(xintercept = -2.8, color = "#A33F3F")+
geom_vline(xintercept = 2.8, color = "#A33F3F")+
scale_color_discrete("")+
xlab("Age Differences (Null Hypothesis)")+
ylab("Number of Individuals")+
theme_bw()
Executarea comenzilor de mai sus, obținem că media distribuției de eșantionare – întrucât distribuția mijloacelor de probă este numită – este de aproximativ 0, așa cum era de așteptat, iar abaterea sa standard este de 1,1.
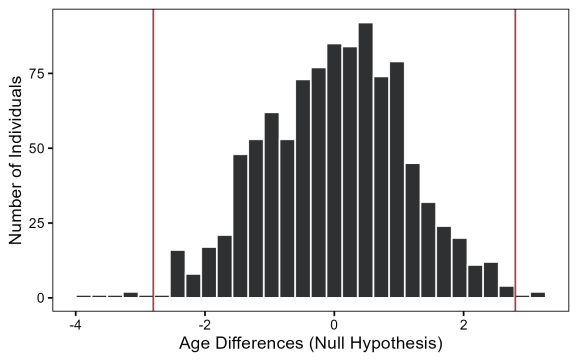
Histograma de mai sus ne arată cum ar arăta diferențele de eșantion dacă ipoteza nulă ar fi adevărate. Liniile roșii arată diferența pe care am observat -o în realitate. Crezi că este probabil să observăm ceea ce am observat sub ipoteza nulă? De fapt nu este și îl puteți calcula cu codul de mai jos:
content_copy
Copie
sum(diffs>=2.81)/1000
sum(diffs<=-2.81)/1000
Codul calculează numărul de eșantioane ale căror mijloace au fost mai mari decât 2,8 (vârsta masculină – vârsta feminină) sau -2,8 (vârsta feminină – vârsta masculină). Aceasta duce la 9 probe din 1.000, sau 0,9%. Această estimare este foarte aproape de valoarea p găsită folosind funcția R t.test. Din nou, putem respinge ipoteza nulă și concluzionăm că există o diferență între vârsta medie a bărbaților și femeilor.
Pe lângă faptul că ne ajută să înțelegem mai bine testul, metoda Bootstrap are avantajul de a nu presupune că distribuția vârstei urmează o distribuție normală. Acesta este un alt beneficiu al utilizării acestei abordări.
Vă rugăm, utilizați comentariile de mai jos dacă nu ați înțeles un punct specific al testului sau dacă aveți o sugestie pentru a îmbunătăți testul.