(Acest articol a fost publicat pentru prima dată pe pacha.dev/blogși a contribuit cu drag la R-Bloggers). (Puteți raporta problema despre conținutul de pe această pagină aici)
Doriți să vă împărtășiți conținutul pe R-Bloggers? Faceți clic aici dacă aveți un blog sau aici dacă nu.
Dacă această postare vă este utilă, vă cer o donație minimă pentru a -mi cumpăra o cafea. Acesta va fi folosit pentru a continua eforturile mele open source. Explicația completă este aici: un mesaj personal de la un contribuabil open source.
Puteți să -mi trimiteți întrebări pentru blog folosind acest formular și să vă abonați pentru a primi un e -mail atunci când există o nouă postare.

Am creat un nou pachet R numit FouriousCorrelations care își propune să îi ajute pe educatori să explice de ce corelația nu implică cauzalitate. Ceea ce aveam în minte au fost cursurile de statistici AP și cursurile de statistici introductive la nivel de colegiu.
Pachetul include un set de date cu 15 corelații spuroase. Îl puteți instala de la CRAN cu:
# install.packages("spuriouscorrelations", repos = "https://cran.rstudio.com")
library(spuriouscorrelations)
Să complotăm una dintre corelațiile spuroase, de exemplu, corelația dintre numărul de persoane care s -au înecat căzând într -o piscină și numărul de filme Nicolas Cage a apărut în:
library(dplyr) library(ggplot2) spurious_correlations %>% distinct(var1_short, var2_short)
# A tibble: 15 × 2 var1_short var2_short1 US spending on science Suicides 2 Falling into a pool drownings Nicholas Cage 3 Cheese consumed Bedsheet tanglings 4 Divorce rate in Maine Margarine consumed 5 Age of Miss America Murders by steam 6 Arcade revenue Computer science doctorates 7 Space launches Sociology doctorates 8 Mozzarella cheese consumption Engineering doctorates 9 Fishing boat deaths Kentucky marriages 10 US crude oil imports from Norway Railway train collisions 11 Chicken consumption US crude oil imports 12 Swimming pool drownings Nuclear power plants 13 Japanese cars sold Suicides by crashing 14 Spelling bee letters Spider deaths 15 Math doctorates Uranium stored
nic_cage <- filter(spurious_correlations, var2_short == "Nicholas Cage") cor(nic_cage$var1_value, nic_cage$var2_value)
ggplot(nic_cage, aes(x = var1_value, y = var2_value)) +
geom_point(size = 3) +
geom_smooth(method = "lm", se = FALSE, color = "blue") +
labs(
title = "Spurious Correlation: Drownings vs. Nicolas Cage Films",
x = "Number of Drownings by Falling into a Pool",
y = "Number of Films Nicolas Cage Appeared In"
) +
theme_minimal()
![]()
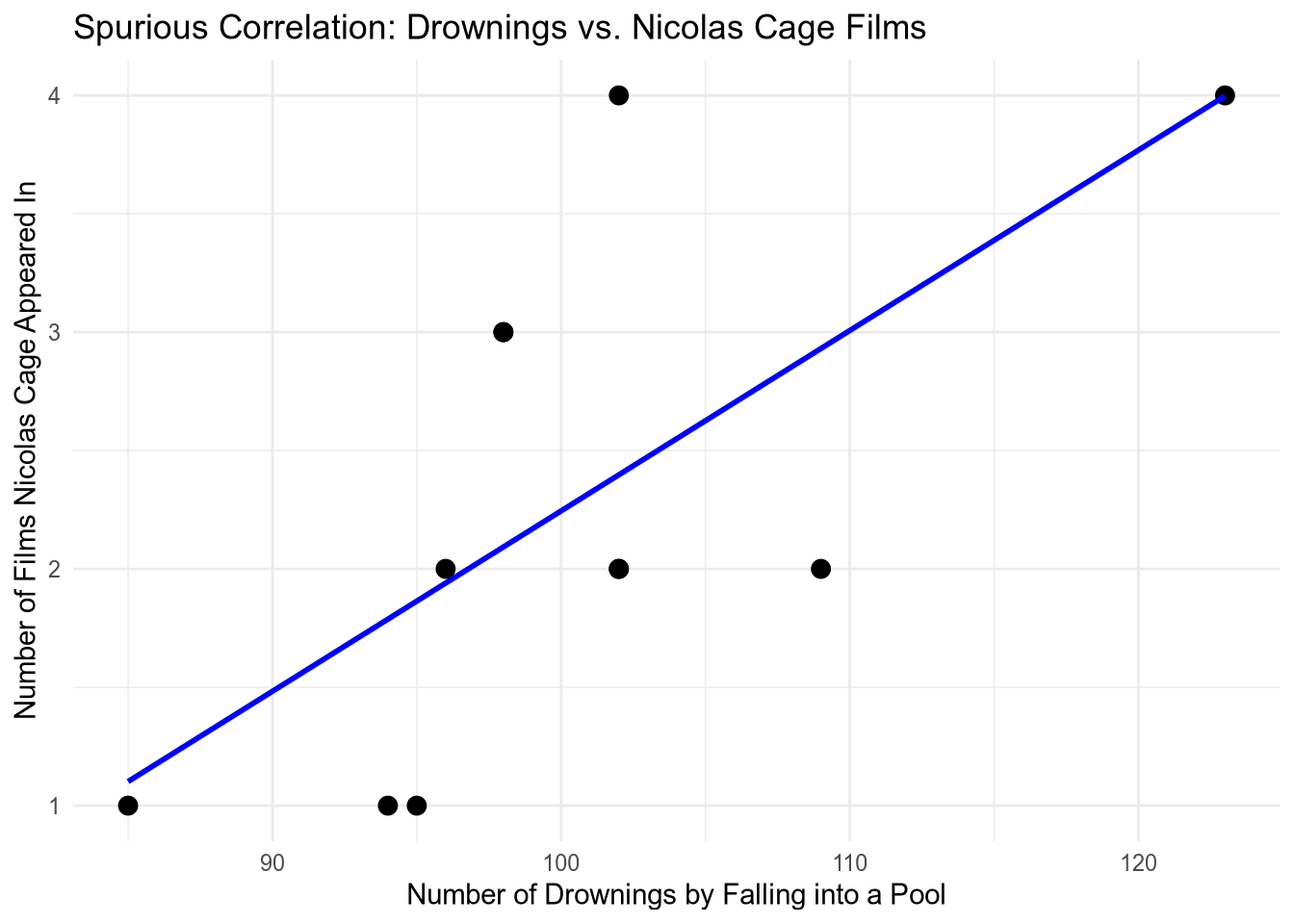
Cu o corelație de 67%, putem chiar să ne potrivim unui model liniar:
lm_model <- lm(var2_value ~ var1_value, data = nic_cage) summary(lm_model)
Call:
lm(formula = var2_value ~ var1_value, data = nic_cage)
Residuals:
Min 1Q Median 3Q Max
-0.9308 -0.5926 -0.1020 0.4836 1.6026
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -5.37515 2.86726 -1.875 0.0936 .
var1_value 0.07620 0.02845 2.678 0.0253 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.8678 on 9 degrees of freedom
Multiple R-squared: 0.4436, Adjusted R-squared: 0.3817
F-statistic: 7.174 on 1 and 9 DF, p-value: 0.02527
Cu o variație explicată de 38% (reglată R-pătrat), putem spune că numărul înecilor este un predictor semnificativ statistic al numărului de filme în care a apărut Nicolas Cage. Cu toate acestea, aceasta este o corelație spuroasă și nu există nicio relație cauzală între aceste două variabile, chiar și cu o valoare P de 0,025.
Acum să comparăm cu un complot dublu axa Y:
# install.packages("tintin", repos = "https://cran.rstudio.com")
library(tidyr)
library(tintin)
cor_val <- cor(nic_cage$var1_value, nic_cage$var2_value)
# Align the two series visually
v1 <- nic_cage$var1_value
v2 <- nic_cage$var2_value
fun_adjust <- function(v1, v2) {
s1 <- sd(v1, na.rm = TRUE)
s2 <- sd(v2, na.rm = TRUE)
a <- ifelse(s2 == 0, 1, s1 / s2)
b <- mean(v1, na.rm = TRUE) - a * mean(v2, na.rm = TRUE)
c(a = as.numeric(a), b = as.numeric(b))
}
adjust <- fun_adjust(v1, v2)
scale_a <- adjust("a")
scale_b <- adjust("b")
y1_title <- as.character(unique(nic_cage$var1))
y2_title <- as.character(unique(nic_cage$var2))
nic_cage_long <- nic_cage %>%
select(year, var1_value, var2_value) %>%
pivot_longer(
cols = c(var1_value, var2_value),
names_to = "variable",
values_to = "value"
) %>%
mutate(
variable_label = case_when(
variable == "var1_value" ~ y1_title,
variable == "var2_value" ~ y2_title
),
# apply transform to var2 for plotting: plot_value = a * var2 + b
plot_value = ifelse(variable == "var2_value", value * scale_a + scale_b, value)
)
# make a double y axis plot with year on the x axis
ggplot(nic_cage_long, aes(x = year)) +
geom_line(aes(y = plot_value, color = variable_label, group = variable_label), linewidth = 1.5) +
geom_point(aes(y = plot_value, color = variable_label), size = 3) +
labs(
x = "Year",
y = y1_title,
title = sprintf("%snvsn%sn", y1_title, y2_title),
subtitle = sprintf("Correlation: %.2f", cor_val),
color = ""
) +
# display all years on the x axis
scale_x_continuous(breaks = nic_cage$year) +
# primary y axis is the var1 scale
# secondary shows var2 original scale by inverse-transforming
scale_y_continuous(
sec.axis = sec_axis(~ (. - scale_b) / scale_a, name = y2_title)
) +
theme_minimal(base_size = 13) +
theme(legend.position = "top") +
# use tintin color palette
scale_colour_manual(
values = tintin_pal(option = "the black island")(2),
name = ""
) +
# center title and subtitle
theme(
plot.title = element_text(hjust = 0.5, size = 16, face = "bold"),
plot.subtitle = element_text(hjust = 0.5)
)
![]()
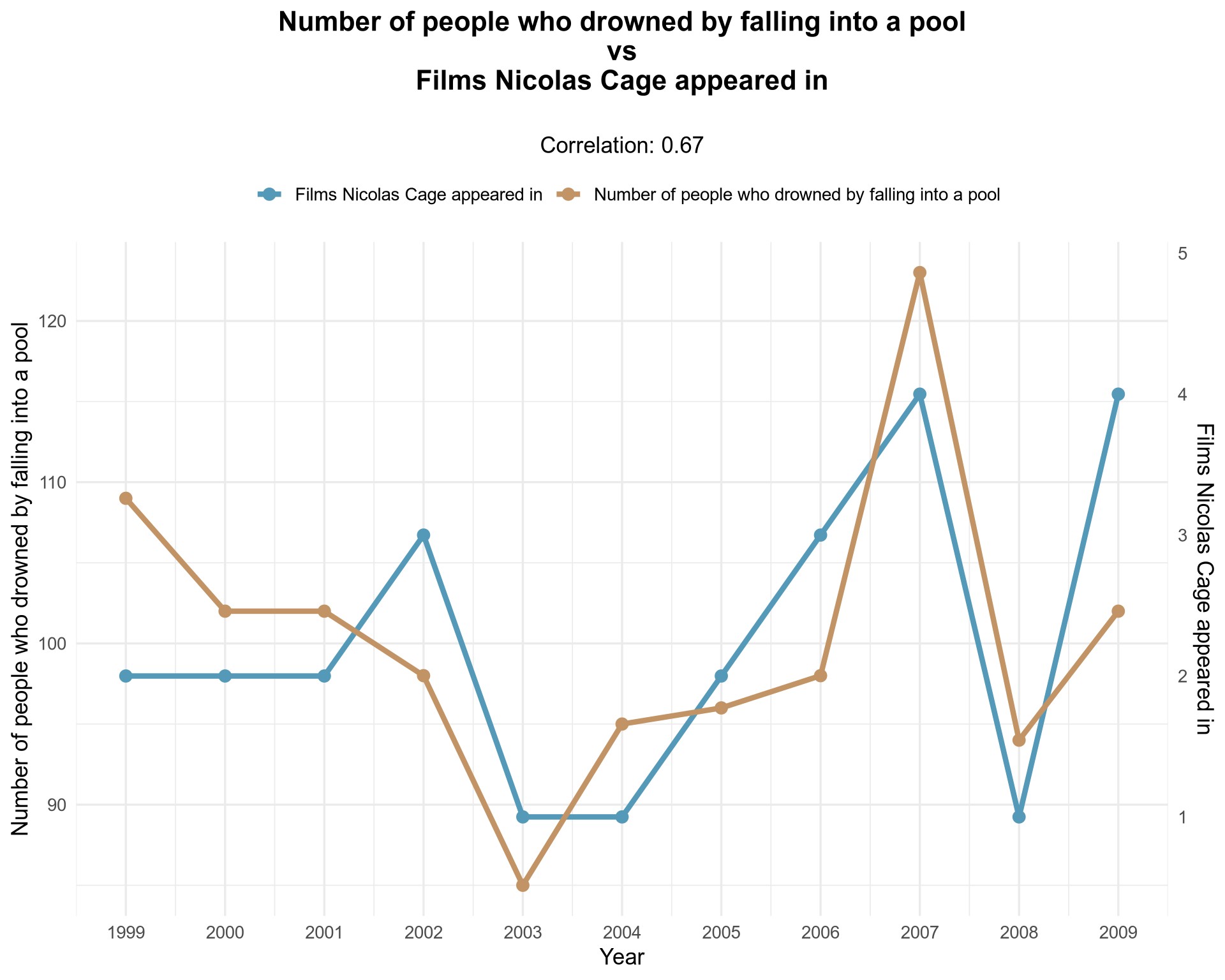
Ce zici de alte corelații spuroase? Iată unul:
engineering_doctorates <- filter(spurious_correlations, var2_short == "Engineering doctorates")
cor_val <- cor(engineering_doctorates$var1_value, engineering_doctorates$var2_value)
v1 <- engineering_doctorates$var1_value
v2 <- engineering_doctorates$var2_value
adjust <- fun_adjust(v1, v2)
scale_a <- adjust("a")
scale_b <- adjust("b")
y1_title <- as.character(unique(engineering_doctorates$var1))
y2_title <- as.character(unique(engineering_doctorates$var2))
engineering_doctorates_long <- engineering_doctorates %>%
select(year, var1_value, var2_value) %>%
pivot_longer(
cols = c(var1_value, var2_value),
names_to = "variable",
values_to = "value"
) %>%
mutate(
variable_label = case_when(
variable == "var1_value" ~ y1_title,
variable == "var2_value" ~ y2_title
),
# apply transform to var2 for plotting: plot_value = a * var2 + b
plot_value = ifelse(variable == "var2_value", value * scale_a + scale_b, value)
)
# make a double y axis plot with year on the x axis
ggplot(engineering_doctorates_long, aes(x = year)) +
geom_line(aes(y = plot_value, color = variable_label, group = variable_label), linewidth = 1.5) +
geom_point(aes(y = plot_value, color = variable_label), size = 3) +
labs(
x = "Year",
y = y1_title,
title = sprintf("%snvsn%sn", y1_title, y2_title),
subtitle = sprintf("Correlation: %.2f", cor_val),
color = ""
) +
# display all years on the x axis
scale_x_continuous(breaks = nic_cage$year) +
# primary y axis is the var1 scale
# secondary shows var2 original scale by inverse-transforming
scale_y_continuous(
sec.axis = sec_axis(~ (. - scale_b) / scale_a, name = y2_title)
) +
theme_minimal(base_size = 13) +
theme(legend.position = "top") +
# use tintin color palette
scale_colour_manual(
values = tintin_pal(option = "the black island")(2),
name = ""
) +
# center title and subtitle
theme(
plot.title = element_text(hjust = 0.5, size = 16, face = "bold"),
plot.subtitle = element_text(hjust = 0.5)
)
![]()
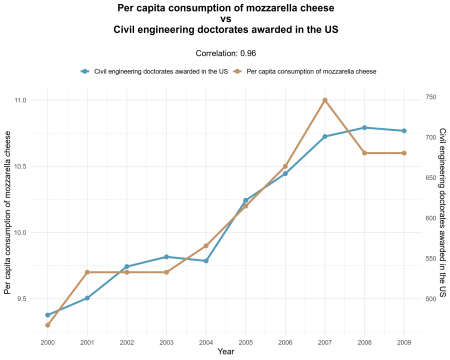
Pot merge ad nauseam cu aceste corelații spuroase. Ideea este că Corelația nu implică cauzalitateși ar trebui să fim atenți atunci când interpretăm corelațiile.