(Acest articol a fost publicat pentru prima dată pe Laboratorul software al lui Adamși a contribuit cu drag la R-Bloggers). (Puteți raporta problema despre conținutul de pe această pagină aici)
Doriți să vă împărtășiți conținutul pe R-Bloggers? Faceți clic aici dacă aveți un blog sau aici dacă nu.
Introducere
În postările anterioare din această serie (Folosind r în excel) Am demonstrat câteva cazuri de utilizare de bază în care utilizarea R în Excel este utilă. Mai exact am analizat statisticile descriptive, regresia liniară, prognoza și apelarea Python. În această postare, voi analiza statisticile inferențiale și modul în care R poate fi utilizat (în Excel) pentru a efectua unele teste statistice tipice. Excel oferă multe facilități excelente pentru Wrangling și Analiza datelor. Cu toate acestea, pentru anumite tipuri de analize de date statistice, limitările funcțiilor încorporate și instrumentul de analiză nu este suficientă, iar R oferă facilități superioare.
Cartea de lucru pentru această parte a seriei este: „Partea V – R în Excel – Statistici inferențiale.xlsx”. Ca și înainte, fișele de lucru „Referințe” listează link -uri către referințe externe. Fișa de lucru „Biblioteci” încarcă pachete suplimentare (fără default). În această demonstrație, folosesc ggpubr și lsr pachet. ggpubr Pachetul oferă câteva funcții ușor de utilizat pentru crearea și personalizarea parcelelor gata de publicație bazate pe GGPLOT2. lsr Pachetul oferă câteva ambalaje utile pentru testele comune de ipoteză și manipularea de bază a datelor. Aceste pachete ar trebui să fie prezente și încărcate înainte de a continua cu analizele.
Fișa de lucru „Seturi de date” conține datele la care se face referire în foile de lucru. Datele pentru analizele principale reprezintă greutățile (în KG) de 9 femei și 9 bărbați. Datele au fost încărcate și un tabel Excel creat numit tWeightData.
Analiza i
Crearea cadrului de date
Primul lucru de făcut este să creezi un cadru de date R. Cu toate acestea, mai degrabă decât să avem un tabel cu două coloane (Women_weight și Men_Weight), dorim o coloană „grup” și o coloană „greutate”. Pentru a face acest lucru, creăm mai întâi vectori folosind:
=RScript.CreateVector('women_weight',Datasets!N2:N10)
şi
=RScript.CreateVector('men_weight',Datasets!O2:O10)
După aceasta, creăm cadrul de date care specifică factorii de grupare și datele. Vectorii corespunzători și weight_data Cadrul de date ar trebui să apară în panoul Excel R Addin.
Compararea mijloacelor
Prima analiză verifică dacă există o diferență semnificativă în greutățile diferitelor grupuri. Pentru aceasta, efectuăm un test T de probe independente. Înainte de efectuarea testului, este util să oferim un rezumat al datelor, astfel încât să grupăm datele pentru a obține mijloacele și abaterile standard și, de asemenea, producem un boxplot.
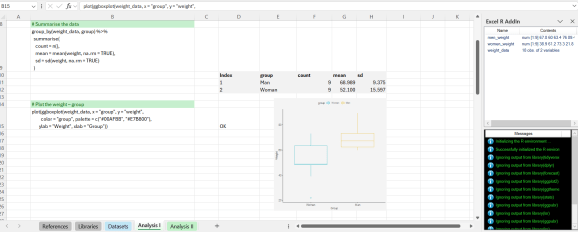
Din complot, pare să existe o diferență plauzibilă în mijloace. Este demn de remarcat că folosim standardul ggboxplot(...) Funcționează, dar înfășurați -l într -un apel la plot(...) funcţie. Aceasta scoate rezultatul la o fereastră grafică separată, de care putem lipi graficul rezultat ca un metafile Windows. Acest lucru nu este ideal, dar încă nu am găsit o modalitate de a desena un complot direct într -o foaie de lucru Excel.
Înainte de a face testul T, vrem să verificăm presupunerile independente de testare T. Mai exact, cele două probe sunt independente, deoarece observațiile provin din grupuri distincte (bărbați și femei). De asemenea, dorim să verificăm dacă datele din fiecare dintre grupuri urmează o distribuție normală. Efectuăm un test de normalitate Shapiro-Wilk pentru fiecare grup. De asemenea, am fi putut inspecta datele vizual cu o histogramă sau un QQPlot.
Din ieșirea testului Shapiro-Wilk, cele două valori p sunt mai mari decât nivelul de semnificație 0.05, ceea ce implică faptul că distribuția datelor nu este semnificativ diferită de distribuția normală. Prin urmare, putem presupune că observațiile de la fiecare grup urmează o distribuție normală.
Compararea variațiilor
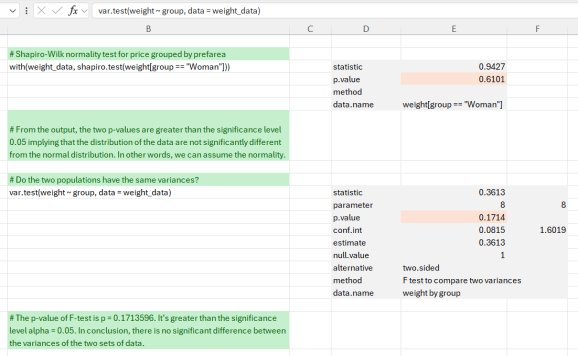
În plus față de testul Shapiro-Wilk, efectuăm un test F pentru a compara variațiile, deoarece una dintre presupunerile unui test t este că variațiile populației ar trebui să fie egale. Ieșirea din var.test este o listă care conține rezultatele individuale, pe care le afișăm. Valoarea p a testului F este p = 0,17136. Deoarece este mai mare decât nivelul de semnificație (alfa = 0,05), concluzionăm că nu există nicio diferență semnificativă între variațiile celor două seturi de date. Prin urmare, putem folosi testul T clasic care presupune egalitatea celor două variații.

T-testul T de două eșantioane nepereche
În cele din urmă, calculăm un test T independent. Ca și înainte, extragem statisticile individuale. Valoarea p a testului este 0,01327, care este mai mică decât nivelul de semnificație (alfa = 0,05). Putem concluziona că greutatea medie a bărbaților este semnificativ diferită de greutatea medie a femeilor în acest set de date cu o valoare p = 0,01327.
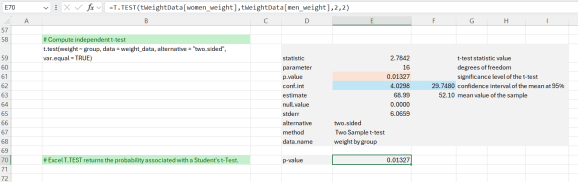
Putem verifica, de asemenea, dacă Excel’s =T.TEST() funcția produce același rezultat.
Analiza II
ANOVA unidirecțional
Pentru a doua analiză, dorim să efectuăm un test ANOVA unidirecțional. Folosim setul de date R încorporat numit PlantGrowth. Conține greutatea plantelor obținute sub un control și două afecțiuni diferite de tratament.
Ca și înainte, afișăm un scurt rezumat al datelor și un boxplot pentru a afișa vizual mijloacele fiecărui grup. Apoi calculăm ANOVA unidirecțional. Ieșirea conține o mulțime de date, așa că extragem componentele individuale, după cum este necesar.
Putem folosi și anova Funcție pentru a rezuma rezultatele testelor.
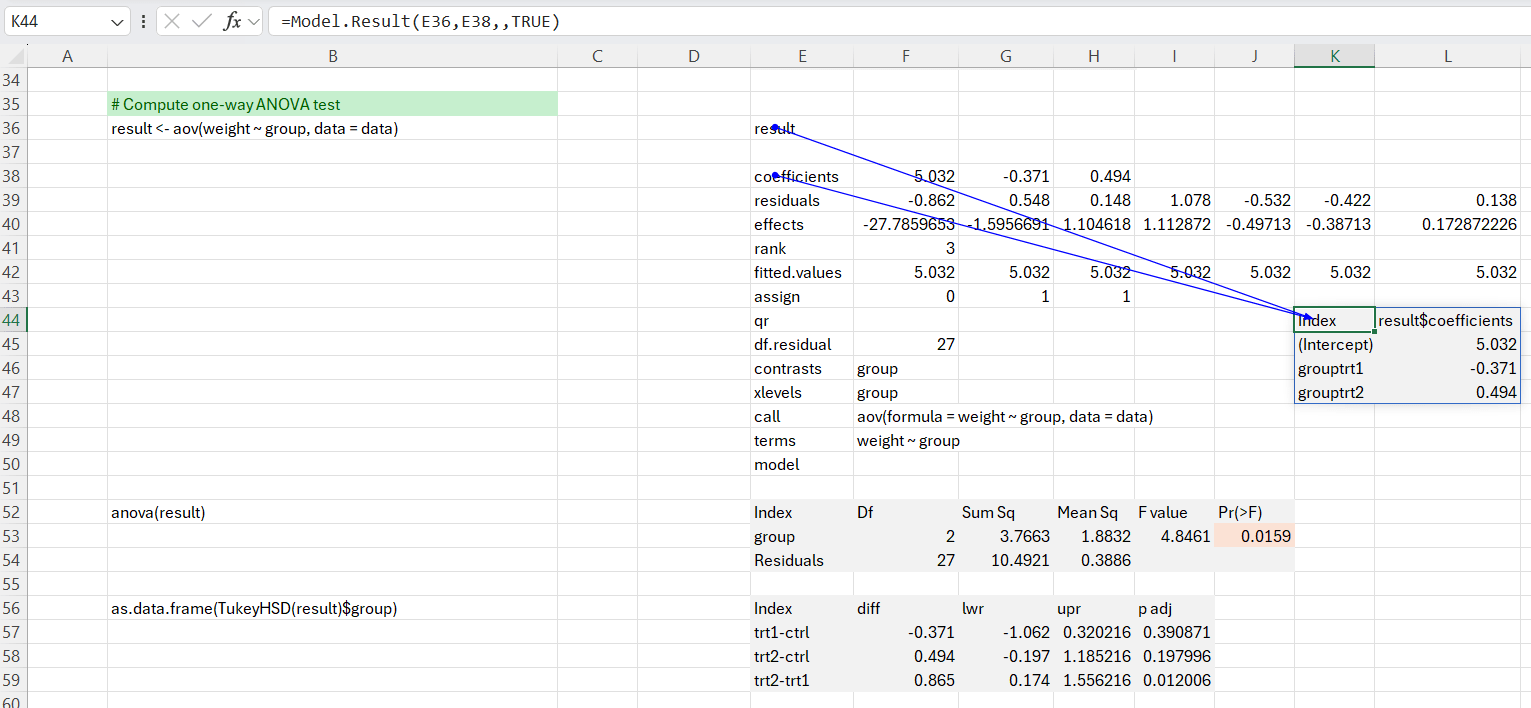
Deoarece valoarea p este mai mică decât nivelul de semnificație 0.05, putem concluziona că există diferențe semnificative între grupuri.
Deoarece rezultatul testului este semnificativ, calculăm Tukey HSD pentru efectuarea mai multor comparații în perechi între mijloacele grupurilor. Se poate observa din ieșire, că numai diferența dintre trt2 şi trt1 este semnificativ cu o valoare p ajustată de 0,012. Același test poate fi efectuat folosind funcția de instrument de analiză Excel „un singur factor ANOVA”. Acest lucru este demonstrat în foaia de lucru „un singur factor ANOVA”.
Învelire
În acest post am folosit R în Excel pentru a efectua câteva teste de bază pentru statistici inferențiale. Am efectuat un test Shapiro-Wilk, un test F, un test T de probe independente și un ANOVA unidirecțional. În trecere, am văzut, de asemenea, cum să complotăm datele și cum să configurați și să recuperați rezultatele modelului. În timp ce o parte din acestea s -ar fi putut face folosind funcțiile native ale Excel, avantajul utilizării R din interiorul Excel este că ne oferă acces la un ecosistem extins, ceea ce la rândul său ne oferă o mare flexibilitate în crearea de soluții.