Să încercăm să aplicăm aceste tehnici unui scenariu mai realist.
# Create a realistic customer feedback dataset
set.seed(456)
feedback_df <- data.frame(
text = c(
"Absolutely love this product! Best purchase I've made all year. Quality is outstanding.",
"Terrible experience. Product broke after one week. Customer service was unhelpful.",
"Good value for the price. Works as expected. Would buy again.",
"Shipping took forever. Product is okay but not worth the wait.",
"Amazing quality and fast delivery. Highly recommend to everyone!",
"Product description was misleading. Not what I expected at all.",
"Decent product but customer support needs improvement. Long wait times.",
"Exceeded my expectations! Great features and easy to use.",
"Poor quality control. Received damaged item. Return process was difficult.",
"Perfect! Exactly what I needed. Five stars all around.",
"Overpriced for what you get. Better alternatives available elsewhere.",
"Good product but instructions were confusing. Setup took hours.",
"Love it! Works perfectly and looks great too.",
"Not satisfied. Product feels cheap and flimsy.",
"Best customer service ever! They resolved my issue immediately.",
"Average product. Nothing special but gets the job done.",
"Fantastic! Will definitely purchase from this company again.",
"Disappointed with the quality. Expected much better.",
"Great features but battery life is poor.",
"Excellent value. Highly recommend for budget shoppers."
),
rating = c(5, 1, 4, 2, 5, 1, 3, 5, 1, 5, 2, 3, 5, 2, 5, 3, 5, 2, 3, 4),
category = sample(c("Electronics", "Home & Kitchen", "Clothing"), 20, replace = TRUE),
helpful_votes = sample(0:50, 20, replace = TRUE),
stringsAsFactors = FALSE
)
# Create corpus
feedback_corp <- corpus(feedback_df, text_field = "text")
# Complete preprocessing pipeline
feedback_dfm <- feedback_corp %>%
tokens(remove_punct = TRUE,
remove_numbers = TRUE,
remove_symbols = TRUE) %>%
tokens_tolower() %>%
tokens_remove(stopwords("english")) %>%
tokens_wordstem() %>%
dfm()
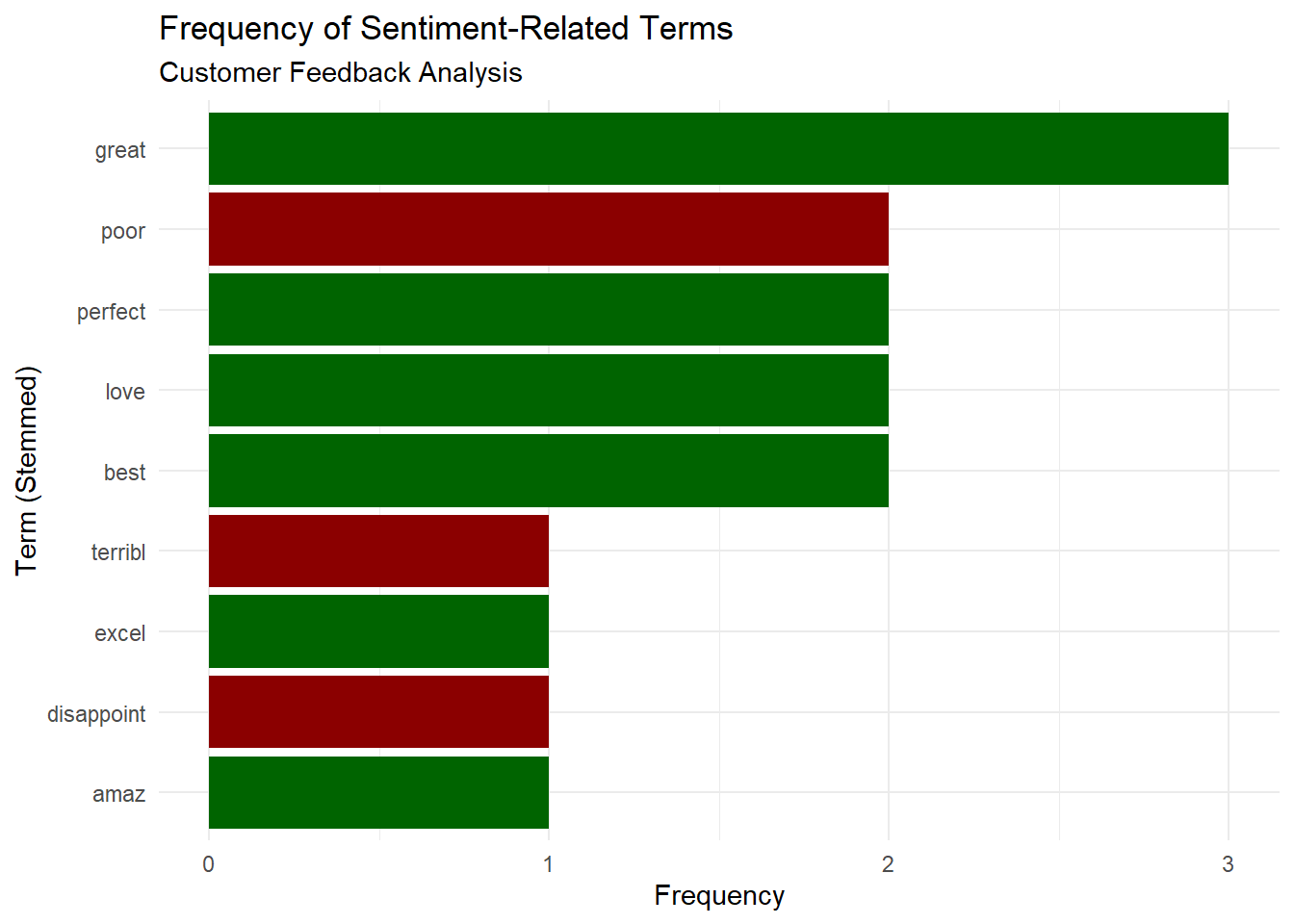
# Analyze overall sentiment-related terms
sentiment_terms <- c("love", "best", "great", "excel", "amaz", "perfect",
"terribl", "poor", "worst", "disappoint", "bad")
sentiment_dfm <- dfm_select(feedback_dfm, pattern = sentiment_terms)
# Calculate sentiment term frequencies
sentiment_freq <- textstat_frequency(sentiment_dfm)
# Visualize sentiment terms
ggplot(sentiment_freq, aes(x = reorder(feature, frequency), y = frequency)) +
geom_col(aes(fill = feature), show.legend = FALSE) +
coord_flip() +
labs(title = "Frequency of Sentiment-Related Terms",
subtitle = "Customer Feedback Analysis",
x = "Term (Stemmed)",
y = "Frequency") +
theme_minimal() +
scale_fill_manual(values = c(
"love" = "darkgreen", "best" = "darkgreen", "great" = "darkgreen",
"excel" = "darkgreen", "amaz" = "darkgreen", "perfect" = "darkgreen",
"terribl" = "darkred", "poor" = "darkred", "worst" = "darkred",
"disappoint" = "darkred", "bad" = "darkred"
))
![]()
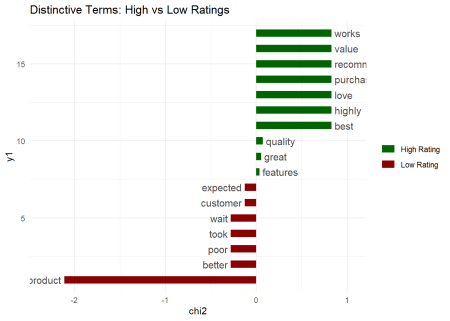
# Compare high vs low-rated reviews
# Create a rating category variable
rating_category <- ifelse(docvars(feedback_corp, "rating") >= 4, "High Rating", "Low Rating")
feedback_grouped <- feedback_corp %>%
tokens(remove_punct = TRUE, remove_numbers = TRUE) %>%
tokens_tolower() %>%
tokens_remove(stopwords("english")) %>%
dfm() %>%
dfm_group(groups = rating_category)
# Calculate keyness (distinctive terms)
keyness_stats <- textstat_keyness(feedback_grouped, target = "High Rating")
# Visualize keyness
textplot_keyness(keyness_stats, n = 10, color = c("darkgreen", "darkred")) +
labs(title = "Distinctive Terms: High vs Low Ratings") +
theme_minimal()
![]()