(Acest articol a fost publicat pentru prima dată pe Generarea noastră de dateși a contribuit cu drag la R-Bloggers). (Puteți raporta problema despre conținutul de pe această pagină aici)
Doriți să vă împărtășiți conținutul pe R-Bloggers? Faceți clic aici dacă aveți un blog sau aici dacă nu.
În urmă cu patru ani, am descris un cadru simplu pentru organizarea simulărilor pentru a efectua analize de putere sau pentru a explora caracteristicile de funcționare ale abordărilor de modelare. În acest cadru, am introdus o funcție mică scenario_list Aceasta a generat o listă de scenarii care formează baza pentru simulări. Întotdeauna intenționasem să încorporez această funcție în simstudyși acum am făcut în sfârșit, așa că noua funcție este disponibilă la versiune 0.9.0.
Această postare oferă o scurtă introducere a funcției și se încheie cu o mică simulare.
Iată R Pachetele utilizate în codul care urmează:
library(simstudy) library(data.table) library(parallel) library(lmerTest) library(broom.mixed)
scenario_list ia o colecție de vectori și generează toate combinațiile posibile ale elementelor lor. Sub capotă, este în esență un înveliș în jurul bazei R funcţie expand.griddar funcția este concepută pentru a face procesul un pic mai convenabil atunci când setați scenarii de simulare.
În primul exemplu, să presupunem că există doi parametri: o (cu 3 elemente) și b (2 elemente). În acest caz, scenario_list va returna o listă de lungime (3 ori 2 = 6 ). Fiecare obiect din listă este un data.table cu un singur rând, unde coloanele sunt numite pentru parametri. O coloană suplimentară este inclusă pentru a identifica în mod unic fiecare scenariu.
a <- c(0.5, 0.7, 0.9) b <- c(8, 16) scenario_list(a, b) ## ((1)) ## a b scenario ## 0.5 8.0 1.0 ## ## ((2)) ## a b scenario ## 0.7 8.0 2.0 ## ## ((3)) ## a b scenario ## 0.9 8.0 3.0 ## ## ((4)) ## a b scenario ## 0.5 16.0 4.0 ## ## ((5)) ## a b scenario ## 0.7 16.0 5.0 ## ## ((6)) ## a b scenario ## 0.9 16.0 6.0
Dacă există un set (sau mai multe seturi) de parametri care vor varia împreună, este posibil să se utilizeze noul grouped Funcție pentru a le lega între ele. În acest exemplu C. şi D. (care au aceeași lungime), sunt grupate, iar numărul de scenarii posibile este încă (6 ) Și nu (3 ori 2 times 2 = 12 ):
Dacă un set (sau mai multe seturi) de parametri trebuie să varieze împreună, noul grouped Funcția poate fi utilizată pentru a le lega. În acest exemplu, C. şi D. (care au aceeași lungime) sunt grupate, astfel încât numărul total de scenarii posibile rămâne (6 )Mai degrabă decât (3 ori 2 times 2 = 12 ).
d <- c(12, 18) scenario_list(a, grouped(b, d)) ## ((1)) ## a b d scenario ## 0.5 8.0 12.0 1.0 ## ## ((2)) ## a b d scenario ## 0.7 8.0 12.0 2.0 ## ## ((3)) ## a b d scenario ## 0.9 8.0 12.0 3.0 ## ## ((4)) ## a b d scenario ## 0.5 16.0 18.0 4.0 ## ## ((5)) ## a b d scenario ## 0.7 16.0 18.0 5.0 ## ## ((6)) ## a b d scenario ## 0.9 16.0 18.0 6.0
În cele din urmă, putem genera mai multe replici ale fiecărui scenariu folosind fiecare argument. De exemplu, există patru combinații posibile de b şi D. (nu este grupat) și setarea fiecare = 2 Creează două replici ale fiecărei combinații:
scenario_list(b, d, each = 2) ## ((1)) ## b d scenario ## 8 12 1 ## ## ((2)) ## b d scenario ## 8 12 1 ## ## ((3)) ## b d scenario ## 16 12 2 ## ## ((4)) ## b d scenario ## 16 12 2 ## ## ((5)) ## b d scenario ## 8 18 3 ## ## ((6)) ## b d scenario ## 8 18 3 ## ## ((7)) ## b d scenario ## 16 18 4 ## ## ((8)) ## b d scenario ## 16 18 4
Simulare de probe folosind scenarios_list
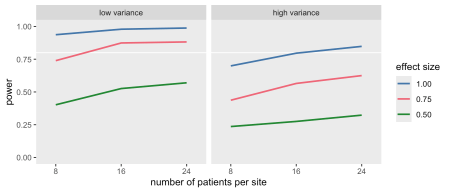
Iată un exemplu simplu de simulare pentru un studiu randomizat de cluster. Scopul este de a explora modul în care patru parametri afectează puterea estimată: dimensiunea eșantionului la nivel de site (npat), variație între site (Svar), variație în interiorul site-ului (Ivar) și dimensiunea efectului (Delta)
Codul de mai jos definește trei funcții de ajutor:
s_define: specifică definițiile datelor pentru datele la nivel de cluster și la nivel individual,s_generate: generează atât date la nivel de site, cât și la nivel individual,s_model: se potrivește unui model cu efecte mixte.
O a patra funcție, s_replicateleagă totul împreună apelând primele trei funcții folosind un singur set de valori ale parametrilor:
s_define <- function() {
#--- data definition code ---#
def1 <- defData(varname = "site_eff",
formula = 0, variance = "..svar", dist = "normal", id = "site")
def1 <- defData(def1, "n", formula = "..npat", dist = "poisson")
def2 <- defDataAdd(varname = "Y", formula = "5 + site_eff + ..delta * rx",
variance = "..ivar", dist = "normal")
return(list(def1 = def1, def2 = def2))
}
s_generate <- function(list_of_defs, argsvec) {
list2env(list_of_defs, envir = environment())
list2env(as.list(argsvec), envir = environment())
#--- data generation code ---#
ds <- genData(40, def1)
ds <- trtAssign(ds, grpName = "rx")
dd <- genCluster(ds, "site", "n", "id")
dd <- addColumns(def2, dd)
return(dd)
}
s_model <- function(generated_data) {
#--- model code ---#
lmefit <- lmer(Y ~ rx + (1|site), data = generated_data)
return(data.table(tidy(lmefit)))
}
s_replicate <- function(argsvec) {
list_of_defs <- s_define()
generated_data <- s_generate(list_of_defs, argsvec)
model_results <- s_model(generated_data)
return(list(argsvec, model_results))
}
Cei patru parametri –npat (2 valori), Svar (2 valori), Ivar (2 valori) și Delta (3 valori) – sunt specificate ca vectori. Deoarece parametrii de varianță sunt meniți să fie testați împreună, ei sunt grupați. Acest lucru rezultă în (3 ori 2 times 3 = 18 ) scenarii distincte. Cu 1000 de replici pe scenariu, scenarii Lista conține 18.000 de obiecte. Obiectul model_fits Apoi va stoca estimările modelului pentru fiecare replicare:
#------ set simulation parameters npat <- c(8, 16, 24) svar <- c(0.40, 0.80) ivar <- c(3, 6) delta <- c(0.50, 0.75, 1.00) scenarios <- scenario_list(delta, npat, grouped(svar, ivar), each = 1000) model_fits <- mclapply(scenarios, function(a) s_replicate(a), mc.cores = 5)
După ce datele au fost colectate, este destul de ușor să rezumați și să creați un tabel sau o cifră.
summarize <- function(m_fit) {
args <- data.table(t(m_fit((1))))
reject <- m_fit((2))(term == "rx", p.value <= 0.05)
cbind(args, reject)
}
reject <- rbindlist(lapply(model_fits, function(a) summarize(a)))
power <- reject(, .(power = mean(reject)), keyby = .(delta, npat, svar, ivar, scenario))