(Acest articol a fost publicat pentru prima dată pe Florian Teschnerși cu amabilitate a contribuit la R-bloggeri). (Puteți raporta problema legată de conținutul acestei pagini aici)
Doriți să vă distribuiți conținutul pe R-bloggeri? dați clic aici dacă aveți un blog, sau aici dacă nu aveți.
În ultima mea postare, am discutat că clicurile sunt o valoare proastă pentru optimizare în sistemele de publicitate. Cu toate acestea, optimizarea față de valorile care sunt mai aproape de conversie are limitele lor. Practic, dacă feedback-ul către sistemele AI (de exemplu, sistemele de optimizare a reclamelor) este prea rar, afirmațiile de optimizare/personalizare automată a anunțurilor nu rezistă.
Scurte sfaturi practice privind optimizarea reclamelor pe piețele mai mici:
-
Cunoașteți densitatea buclei de feedback — Sistemele de optimizare AI necesită suficiente evenimente de conversie pentru a învăța. Pe piețele mici, pur și simplu nu veți avea suficient feedback pentru a pregăti modele de încredere.
-
Calculați afișările necesare în avans — Înainte de a lansa teste complexe (mai multe reclame, mai multe segmente de public), executați calculul privind dimensiunea eșantionului. Dacă numerele nu se adună la ceva realizabil în intervalul de timp, simplificați designul testului.
-
Utilizați proxy cu frecvență mai mare — Când conversiile sunt rare, optimizați pentru vizitele pe site, adăugarea în coș sau alte evenimente la mijlocul canalului. Acestea oferă de 10-100 de ori mai mult semnal de antrenament.
-
Acceptați că sistemele proiectate în SUA nu se reduc — Platformele construite pentru piața din SUA (330 de milioane+ persoane) presupun date abundente. Aceiași algoritmi nu funcționează când ai 1/50 din populație.
-
Manual bate automate sparte — Dacă aveți nevoie de 34 de milioane de afișări pentru semnificație statistică, dar aveți o capacitate de numai 2 milioane, direcționarea creată de oameni va depăși AI, care este încă „pornire la rece”.
Versiune lungă
Sistemele de optimizare și personalizare a anunțurilor bazate pe inteligență artificială sunt impresionante. TikTok, Google, Meta; vă pot afișa anunțul potrivit persoanei potrivite la momentul potrivit, învățând și îmbunătățindu-se continuu. Dar există un secret murdar: aceste sisteme sunt construite pentru piața SUA/Chineză.
Când încerci să le folosești pe piețe mai mici, cum ar fi Germania (80 de milioane de oameni) sau Suedia (10 milioane), matematica se strică. Bucla de feedback care permite învățarea AI devine prea rară pentru ca algoritmii să funcționeze.
Nu este vorba despre calitatea AI, ci despre dimensiunea eșantionului. Iar implicațiile sunt brutale pentru oricine care desfășoară campanii publicitare sofisticate în afara celor mai mari piețe din lume.
Constrângerea fundamentală: evenimente per model
Sistemele de optimizare AI învață din feedback. Fiecare conversie (sau eveniment proxy) este un exemplu de antrenament. Cu cât sunt mai multe exemple, cu atât modelul este mai bun. Dar există un prag sub care învățarea pur și simplu nu are loc.
În SUA, cu 330 de milioane de oameni și miliarde de afișări de anunțuri zilnic, acumulezi rapid date de antrenament. În Suedia, cu 10 milioane de oameni, s-ar putea să obțineți 1/30 din volum, dar sistemul AI nu are nevoie de 1/30 din date. Are nevoie de aproximativ aceleaşi cantitatea de date pentru a converge.
Rezultatul: Optimizarea AI nu converge niciodată. Este permanent în modul „pornire la rece”, luând decizii mai degrabă bazate pe zgomot decât pe semnal.
Verificarea realității dimensiunii eșantionului
Permiteți-mi să lucrez printr-un exemplu concret. Să presupunem că doriți să efectuați un test A/B care compară reclamele publicitare:
- CTR = 0,5% (tipic pentru anunțuri grafice)
- Rata clic-pentru-conversie = 2% (persoane care fac clic și convertesc)
- Acest lucru ne oferă o impresie despre Rata de conversie = 0,01%
- Dorim să detectăm care reclamă este cu 30% mai bună decât celelalte
De câte impresii avem nevoie?
3 reclame
Doar 3 variante ale aceluiași anunț:
# Sample size calculation for detecting 30% lift in LPEV
# Base rate: 0.01% (CTR 0.5% x Conversion 2%)
base_rate <- 0.0001 # 0.01%
lift_to_detect <- 0.30 # 30% improvement
alpha <- 0.05
power <- 0.80
# For 3 arms (3 comparisons), need Bonferroni correction
# Z for 95% confidence with 3 comparisons
z_alpha <- qnorm(1 - (0.05 / 6))
z_beta <- qnorm(power)
delta <- base_rate * lift_to_detect
# Sample size per arm
n_per_arm <- ((z_alpha + z_beta)^2 * 2 * base_rate * (1 - base_rate)) / (delta^2)
n_per_arm
Aceasta ne oferă aproximativ 2,3 milioane de afișări per reclamă.
Total pentru 3 reclame: ~7 milioane de afișări
5 reclame
Testarea a 5 reclame diferite înseamnă 10 comparații în perechi. Aceasta crește dimensiunea eșantionului:
| Scenariu | Afișări pe braț | Total de impresii |
|---|---|---|
| 3 reclame | ~2,3 milioane | ~7M |
| 5 reclame | ~3,0 milioane | ~15 milioane |
| 9 brațe (3 segmente de public × 3 reclame) | ~3,8 milioane | ~34 de milioane |
Personalizarea reclamelor: problema celor 9 brațe
Acum imaginați-vă că testați 3 segmente de public diferite cu câte 3 reclame fiecare – 9 variante în total. Ai nevoie 34 de milioane de afișări pentru semnificație statistică.
Simulare R: dimensiunea eșantionului în funcție de numărul de brațe
Permiteți-mi să văd cum crește dimensiunea eșantionului odată cu complexitatea:
library(ggplot2)
library(dplyr)
library(scales)
set.seed(42)
# Parameters
base_rate <- 0.0001 # 0.01% LPEV
lift <- 0.30 # 30% improvement to detect
# Sample sizes for different numbers of arms
arms <- c(2, 3, 5, 9, 15)
comparisons <- sapply(arms, function(n) n choose 2) # Pairwise comparisons
alpha_adjusted <- 0.05 / comparisons
# Z-scores for each scenario
z_alpha <- qnorm(1 - alpha_adjusted / 2)
z_beta <- qnorm(0.80)
delta <- base_rate * lift
sample_per_arm <- ((z_alpha + z_beta)^2 * 2 * base_rate * (1 - base_rate)) / (delta^2)
total_impressions <- sample_per_arm * arms
df_sample <- data.frame(
arms = factor(arms),
per_arm = round(sample_per_arm / 1e6, 1),
total = round(total_impressions / 1e6, 1)
)
ggplot(df_sample, aes(x = arms, y = total, fill = arms)) +
geom_col(alpha = 0.7) +
geom_text(aes(label = paste0(total, "M")),
vjust = -0.5, size = 4, fontface = "bold") +
scale_y_continuous("Total impressions (millions)",
labels = comma_format(),
limits = c(0, 45)) +
scale_fill_viridis_d(option = "plasma") +
labs(title = "Sample Size Explodes with Test Complexity",
subtitle = "Detecting 30% lift at 0.01% conversion rate",
caption = "US-scale campaigns can hit these numbers; smaller markets never will") +
theme_minimal(base_size = 12) +
theme(legend.position = "none",
axis.text.x = element_text(angle = 45, hjust = 1))

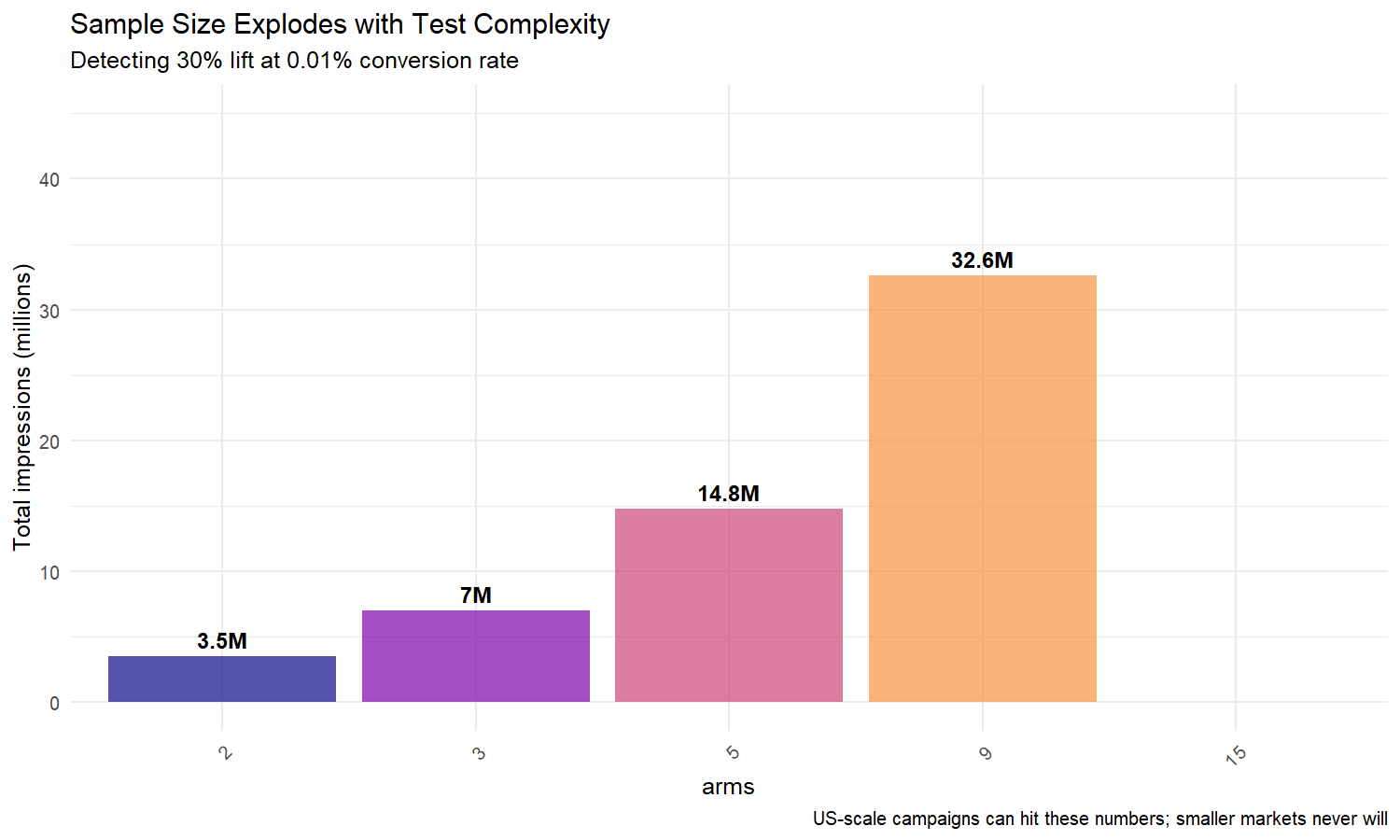
Perspectiva cheie: dimensiunea eșantionului crește super-liniar cu numărul de arme. 9 brațe necesită aproape de 5 ori impresiile a 2 brațe.
Problema dimensiunii pieței
Acum să comparăm dimensiunile pieței:
| Piaţă | Populația | Afișări zilnice de anunțuri | Timp până la 34 de milioane de afișări |
|---|---|---|---|
| NE | 330M | ~5 milioane | ~7 săptămâni |
| Germania | 80M | ~0,5 milioane | ~68 de săptămâni |
| Suedia | 10M | ~0,1 milioane | ~85 de săptămâni |
În SUA, un test cu 9 brațe converge în câteva săptămâni. În Suedia, același test durează aproape doi ani; până în care piața s-a schimbat, reclamele sunt învechite, iar rezultatele testelor sunt lipsite de sens.
Problema per capita
Nu este vorba doar despre dimensiunea totală a pieței. Este vorba despre evenimente de conversie pe cap de locuitor.
Sistemele AI nu învață din populația totală, ci învață din evenimente per utilizator. Dacă populația ta este de 1/30 din mărime și cheltuielile tale cresc proporțional, vei obține 1/30 din numărul evenimentelor. Dar sistemul AI are nevoie de aceleaşi număr de evenimente pentru a atinge același nivel de sofisticare.
Ce se întâmplă de fapt în practică
Când implementați optimizarea AI proiectată în SUA pe piețe mai mici, iată ce se întâmplă:
-
Sistemul nu părăsește niciodată pornirea la rece: Este perpetuu incert, schimbând ținte aleatoriu în funcție de zgomot.
-
Apare o simplificare excesivă: A obține orice semnal, sistemul grupează utilizatorii în segmente largi. „Personalizarea” devine abia mai bună decât întâmplătoare.
-
Optimizări greșite: Când sistemul ia o decizie (de exemplu, creația A depășește creația B), aceasta este adesea nevalidă din punct de vedere statistic. „Câștigătorul” a câștigat din întâmplare, nu prin performanță reală.
-
Deteriorarea buclei de feedback: Deciziile proaste timpurii se întăresc singure. Sistemul se optimizează către ținta greșită, creând un optim local de care este greu de scăpat.
Soluții pentru piețele mai mici
Dacă rulați campanii publicitare sofisticate în afara SUA, ce puteți face?
1. Simplificați designul testului
Nu efectuați teste cu 9 brațe. Rulați teste cu două brațe (A/B) sau chiar campanii cu o singură variantă cu ipoteze clare. Matematica devine manevrabilă:
- 2 brațe: ~2 milioane de afișări
- 3 brațe: ~7 milioane de afișări
- 9 brațe: ~34 milioane de afișări
2. Utilizați proxy cu frecvență mai mare
În loc să optimizați pentru achiziții (rată de 0,01%), optimizați pentru:
- Vizite pe site (rată de 1-2%) — de 100-200 de ori mai multe evenimente
- Adaugă în coș (rata de 0,5-1%) — de 50-100 de ori mai multe evenimente
- Valori de implicare a paginii (rată de 0,5-2%) — variază în funcție de pagină
Este exact ceea ce recomandă lucrarea lui Dalessandro et al. (vezi ultimul post). Un proxy cu o rată de 1% are nevoie de ~100 de ori mai puține afișări decât unul cu o rată de 0,01%.
3. Pool pe piețe
Dacă operați pe mai multe piețe mai mici, luați în considerare:
- Instruire pe date reunite, cu aplicare local (cu controale geografice)
- Efectuarea de teste paneuropene atunci când testele individuale de țară nu sunt fezabile
- Utilizarea modelelor globale cu reglaj regional
4. Acceptați batai manuale automate sparte
Uneori, cel mai bun „AI” este un om care înțelege:
- Dinamica dumneavoastră specifică a pieței
- Modele sezoniere unice pentru regiunea dvs
- Creativ și mesaje care rezonează la nivel local
Un planificator media cu experiență care ia decizii bazate pe cunoștințele domeniului va învinge un sistem AI care este încă la început după doi ani de „învățare”.
Lecția mai largă
Nu este vorba doar de publicitate. Este vorba despre o limitare fundamentală a AI: sistemele necesită o densitate suficientă de feedback pentru a funcționa.
Observăm că IA proiectată de SUA este implementată la nivel global – în HR, sănătate, finanțe, logistică – fără a lua în considerare dacă există suficiente date locale pentru a face algoritmii să funcționeze. Rezultatele sunt previzibile proaste.
În publicitate, simptomul este „învățarea” nesfârșită care nu converge niciodată. În alte domenii, arată ca recomandări părtinitoare, predicții slabe sau instabilitate a sistemului.
Înainte de a implementa optimizarea AI în sistemele publicitare, întrebați:
- Câte evenimente de feedback primim pe perioadă de timp?
- De câte are nevoie algoritmul de fapt pentru a converge?
- Vom ajunge vreodată la acest număr pe această piață?
Dacă răspunsul este nu, simplificați. Veți avea mai multă încredere în optimizarea AI bazată pe feedback decât într-un sistem mai simplu, care să corespundă constrângerilor dvs.
Takeaways
Sistemele de optimizare AI sunt puternice, dar nu sunt magice. Au nevoie de date, multe, iar piețele mai mici pur și simplu nu le oferă.
Designul centrat pe SUA al majorității platformelor de anunțuri înseamnă că funcțiile sofisticate se defectează atunci când reduceți. Pe piețe precum Germania sau Suedia, abordarea corectă este adesea:
- Modele de testare mai simple
- Proxy cu frecvență mai mare
- Mai multă supraveghere umană
- Acceptarea faptului că „personalizarea completă” nu este fezabilă din punct de vedere matematic
Uneori, cea mai sofisticată soluție este recunoașterea limitelor rafinamentului.