(Acest articol a fost publicat pentru prima dată pe Modele de peisaje maritimeși cu amabilitate a contribuit la R-bloggeri). (Puteți raporta problema legată de conținutul acestei pagini aici)
Doriți să vă distribuiți conținutul pe R-bloggeri? dați clic aici dacă aveți un blog, sau aici dacă nu aveți.
Ne place sau nu, toată lumea folosește modele mari de limbaj pentru a-și face statisticile.
Există o mulțime de afirmații despre dacă LLM-urile pot sau nu pot face statistici ecologice utile. În noua noastră lucrare „Prompting large language models for quality ecological statistics” (în Methods in Ecology and Evolution) am vrut să testăm acele afirmații cantitativ.
Oferim linii directoare pentru utilizarea LLM-urilor pentru a produce analize statistice valide din punct de vedere științific. Versiunea scurtă: LLM-urile vă pot ajuta să faceți statistici mai bune, dar numai dacă întrebați bine. Și „a întreba bine” este o abilitate de învățat.
Lucrarea este scrisă în colaborare cu expertul agentic AI Scott Spillias și s-a dezvoltat din experiențele noastre de predare LLM pentru analiză statistică.
De ce am scris-o
De câțiva ani îi învăț cercetătorilor cum să folosească LLM-urile pentru codificare și statistică. Două lucruri au continuat să apară. În primul rând, majoritatea oamenilor subestimează cât de mult contează promptul – tratează LLM-urile ca pe un motor de căutare și primesc sfaturi de calitate pentru motoarele de căutare. În al doilea rând, unii oameni au încredere în codul și statisticile generate de LLM fără critici, ceea ce este riscant.
Studiile de la sfârșitul anului 2024 au descoperit că LLM-urile au recomandat testul statistic corect în mai puțin de 40% din timp cu solicitări generice. Dar precizia se îmbunătățește substanțial cu indicații mai specifice, care este o abilitate cheie pe care ne concentrăm în articol.
Ce am găsit
Am efectuat evaluări repetabile în R, replicând fiecare prompt de 10 ori în mai multe LLM-uri. Câteva rezultate au ieșit în evidență.
Specificitatea contează enorm pentru selecția testului. Am comparat patru solicitări pentru alegerea unui test statistic pentru un set de date ecologice, variind de la „Cum testez relația dintre două variabile continue?” la un prompt detaliat care specifică tipurile de variabile, dimensiunea eșantionului și designul studiului. Promptul generic nu a sugerat niciodată modele de numărare (familia adecvată pentru datele despre abundența peștilor). Promptul detaliat i-a garantat, indiferent de LLM pe care l-am folosit.
Instrucțiunile detaliate fac codul generat de agent mai consistent. I-am cerut agentului Github Copilot să scrie un întreg flux de lucru de analiză din două solicitări diferite – una scurtă, una detaliată. Apoi am executat ordonarea multivariată pe codul rezultat pentru a măsura cât de asemănătoare au fost cele 10 replicări între ele. Promptul detaliat a produs grupuri mult mai strânse – agentul a continuat să folosească aceleași funcții, nume de variabile și structură. Codul inconsecvent este mai greu de revizuit, ceea ce contează dacă încercați să detectați erori statistice.
A fi specific învinge modelele mai slabe. Când am însărcinat LLM-urilor să scrie cod R pentru a calcula o matrice de distanță, promptul detaliat a primit răspunsul corect 90-100% din timp pentru toate modelele. Promptul scurt a eșuat în mare parte – cu excepția Codexului GPT-5, care a ghicit corect de 9/10 ori. Indicațiile bune au compensat în mod eficient utilizarea unui model mai mic și mai ieftin.
Fluxul de lucru pe care îl recomandăm
Vă sugerăm să împărțiți analiza asistată de LLM în trei etape și să scrieți solicitări separate pentru fiecare. Acest lucru vă ajută să controlați fluxul de lucru și să evitați greșelile LLM.
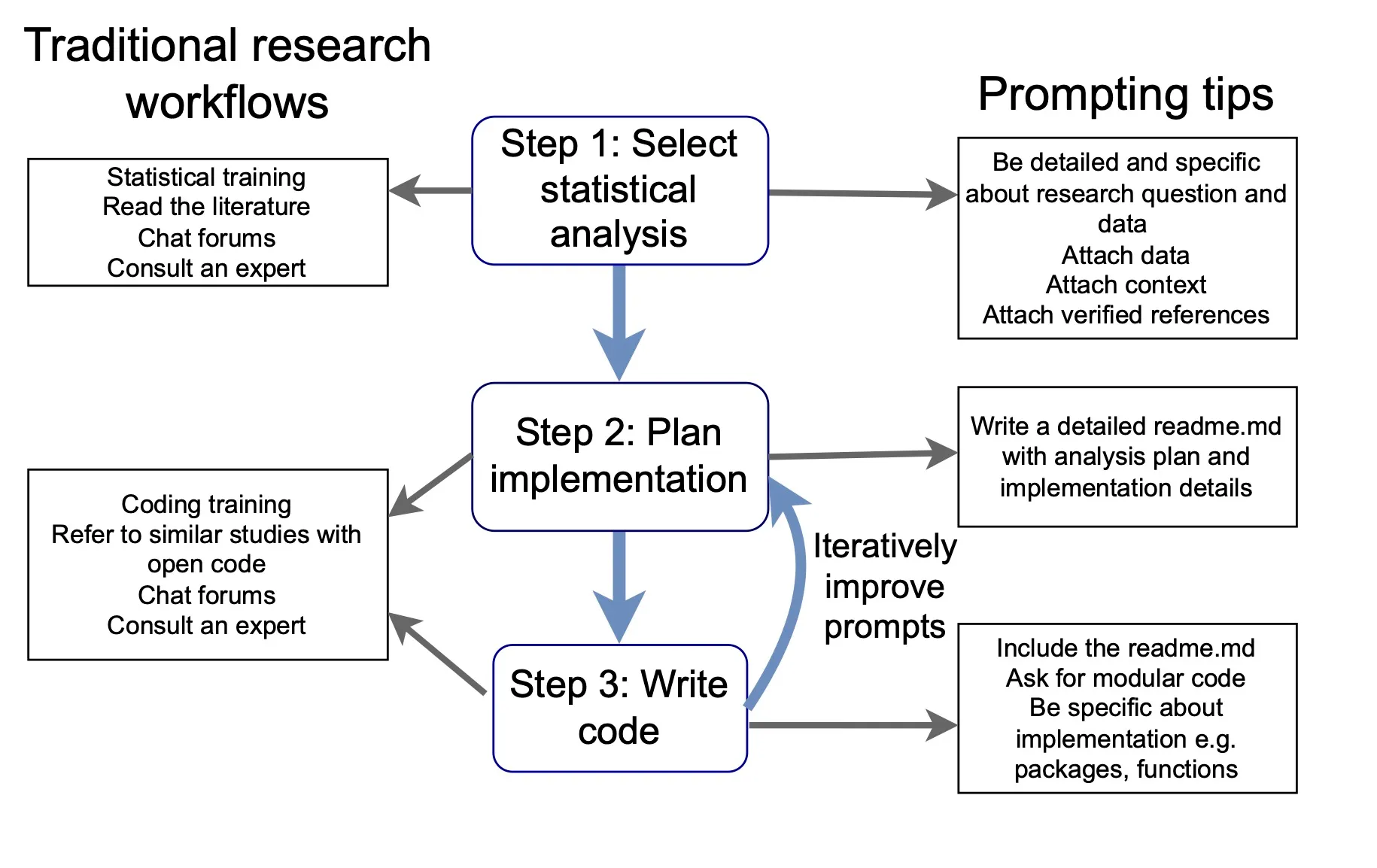
-
Alegeți abordarea statistică — descrieți în detaliu variabilele, dimensiunea eșantionului și designul studiului. Atașați datele sau un rezumat. Indicați LLM către material de referință în care aveți încredere.
-
Planificați implementarea — înainte de a scrie orice cod, obțineți LLM pentru a vă ajuta să structurați directorul de proiect și scripturile. Folosim a
readme.mdcare include contextul cercetării, pașii de analiză, preferințele pachetului și aspectul directorului. Acest fișier este apoi atașat la fiecare solicitare ulterioară, oferind LLM-ului o memorie consecventă între sesiuni. -
Scrie codul — cu un readme detaliat și instrucțiuni explicite, agenții pot finaliza analizele cu o supraveghere minimă. Fără această structură, chiar și modelele puternice produc cod greu de revizuit și inconsecvent între rulări.
Sfaturi generale pentru sugestii
Acestea se aplică indiferent de stadiul analizei în care vă aflați:
- Declarați un rol în avans — începeți cu „Sunteți un expert în statistică ecologică și R.” Acest lucru orientează LLM și îl îndeamnă către metode adecvate disciplinei.
- Evitați conversația în mai multe rânduri acolo unde este posibil — fiecare tură adaugă context care nu poate fi eliminat. Dacă conversația merge prost, începeți din nou cu un prompt mai bun decât să încercați să corectați cursul.
- Utilizați bootstrapping prompt — întrebați LLM de ce informații ar avea nevoie pentru a răspunde mai bine la întrebarea dvs., apoi începeți o nouă sesiune cu acel prompt îmbunătățit.
- Atașați propriile referințe — în loc să-l lăsați pe LLM să caute pe web, îndreptați-l către tutoriale și vignete pe care le-ați verificat deja. Tu controlezi calitatea contextului.
- Împărțiți problemele în pași — nu cere totul deodată. Separați alegerea unei metode, planificarea structurii codului și scrierea codului în prompturi distincte.
Rolul important pentru om de știință
Expertiza statistică este încă necesară. Trebuie să știți suficient pentru a evalua dacă sugestiile LLM sunt adecvate, pentru a verifica dacă codul este valid din punct de vedere științific (nu doar corect din punct de vedere sintactic) și pentru a înțelege ce înseamnă rezultatele. Începătorii cărora le lipsește acest fundal au mai multe șanse să scrie sugestii proaste și mai puțin probabil să primească sfaturi proaste.
Credem că alfabetizarea LLM ar trebui să facă parte din programele de formare statistică, alături de elementele fundamentale. În propriul nostru antrenament, începem începătorii cu principiile fundamentale și statisticile R, fără alte AI decât remedieri de erori sau cerând explicații pentru codul necunoscut. Odată ce înțeleg conceptele de bază, trecem apoi la forme mai avansate de integrare AI. Acest lucru trebuie introdus în pas.
De asemenea, abia începem să înțelegem părtinirile LLM pentru datele ecologice. Dependențele spațiale, modelele imbricate și datele de numărare zero-umflate sunt comune în ecologie, dar probabil subreprezentate în datele de formare LLM. Mai este multă muncă de evaluare de făcut.
Lucrarea și tot codul pentru evaluări sunt la Zenodo. Dacă doriți întregul flux de lucru în practică, există și un curs de o zi și o carte online.