(Acest articol a fost publicat pentru prima dată pe generarea noastră de dateși cu amabilitate a contribuit la R-bloggeri). (Puteți raporta problema legată de conținutul acestei pagini aici)
Doriți să vă distribuiți conținutul pe R-bloggeri? dați clic aici dacă aveți un blog, sau aici dacă nu aveți.
În postarea anterioară, mi-am făcut drum prin câteva elemente cheie ale teoriei TMLE în timp ce încerc să înțeleg cum funcționează totul. În esență, TMLE se concentrează pe a face ca funcția de influență eficientă (EIF) să se comporte corect. Când se întâmplă acest lucru, estimatorul parametrului țintă se comportă ca și cum s-ar fi bazat pe un eșantion aleatoriu din distribuția adevărată generatoare de date.
Estimarea rezultatului și modelelor de tratament (sau de expunere) este o parte importantă a construirii EIF, dar acestea sunt tratate ca componente neplăcute și nu trebuie să fie perfect specificate. Etapa de țintire se poate ajusta pentru erori în aceste estimări neplăcute, recuperând adesea comportamentul empiric dorit al EIF și îmbunătățind estimarea rezultată a parametrului țintă, chiar și atunci când unul dintre modelele de neplăcere este specificat greșit.
În acea postare anterioară, am descris modul în care TMLE nu încearcă pur și simplu să îmbunătățească modelele neplăcute, ci în schimb efectuează o ajustare țintită, astfel încât media empirică a funcției de influență eficientă estimată să fie readusă la zero. În această postare, folosesc simularea pentru a vedea direct ce se schimbă direcționarea. În special, compar doi estimatori ai efectului mediu de tratament (ATE) — estimatorul plug-in și TMLE — cu scopul de a înțelege ce face mecanic pasul de direcționare și cum afectează estimarea finală.
Mă concentrez pe două întrebări. În primul rând, cât de departe este media empirică a funcției de influență estimată de zero înainte și după țintire? În al doilea rând, cum se comportă estimările plug-in-ului și TMLE ale ATE în diferite scenarii de model neplăcut?
O recapitulare rapidă a țintei
Pentru un tratament binar (O)covariate (X)și rezultatul (Y)definiți regresia rezultatului condiționat și scorul de înclinație ca
( Q_a(X)=E(Y∣A=a,X), g(X)=P(A=1∣X). )
Ținta noastră este efectul mediu al tratamentului (reprezentat ca (psi)):
( psi_0 = Ebig(Y(1)−Y(0)big). )
În ipotezele obișnuite de identificare, aceasta poate fi scrisă ca
( psi(P)=E_P(Q_1(X)−Q_0(X)). )
Funcția de influență eficientă pentru ATE este
( phi_P(Z) = big(Q_1(X)−Q_0(X)−psi(P)big ) + frac{A}{g(X)}big(Y − Q_1(X)) − frac{1−A}{1−g(X)}big(Y−Q_0(X)big). )
Dacă am cunoaște adevăratele funcții neplăcute, această cantitate ar fi centrată sub distribuția adevărată, iar media ei empirică ar fluctua în jurul zero din cauza variabilității eșantionării. În practică, desigur, noi conectați funcțiile neplăcute estimate și atunci media empirică nu trebuie să fie aproape de zero deloc. TMLE actualizează regresia rezultatului inițial suficient pentru a elimina acel dezechilibru empiric.
Simularea de mai jos este concepută pentru a face vizibil acel pas.
Proces de generare a datelor
Pentru a menține povestea aliniată cu postarea anterioară de simulare, folosesc același proces de generare a datelor. Covariatele influențează atât alocarea tratamentului, cât și rezultatul, deci există o confuzie reală. ATE adevărată este constantă și egală cu (tau).
knitr::opts_chunk$set(
eval = FALSE
)
library(simstudy)
library(data.table)
library(ggplot2)
gen_dgp <- function(n, tau = 5) {
def <-
defData(varname = "x1", formula = 0.5, dist = "binary") |>
defData(varname = "x2", formula = 0, variance = 1, dist = "normal") |>
defData(
varname = "a",
formula = "-0.2 + 0.8 * x1 + 0.6 * x2",
dist = "binary",
link = "logit"
) |>
defData(
varname = "y",
formula = "..tau * a + 1.0 * x1 + 1.0 * x2 + 1.5 * x1 * x2",
variance = 1,
dist = "normal"
)
genData(n, def)()
}
Scenarii de tip neplăcut
Pentru a vedea cum se comportă estimatorii în baza diferitelor ipoteze de modelare, iau în considerare patru scenarii:
- ambele modele neplăcute specificate corect
- modelul de rezultat specificat greșit, modelul de înclinație corect
- model de înclinație specificat greșit, modelul rezultat corect
- ambele modele neplăcute specificate greșit
Funcțiile de montare neplăcută variază în funcție de fiecare scenariu:
fit_nuisance <- function(dt, scenario) {
if (scenario %in% c("both_correct", "g_wrong")) {
Q_fit <- lm(y ~ a + x1 + x2 + x1:x2, data = dt)
} else {
Q_fit <- lm(y ~ a + x1, data = dt)
}
if (scenario %in% c("both_correct", "Q_wrong")) {
g_fit <- glm(a ~ x1 + x2, family = binomial(), data = dt)
} else {
g_fit <- glm(a ~ x1, family = binomial(), data = dt)
}
list(Q_fit = Q_fit, g_fit = g_fit)
}
Funcțiile de ajutor pentru predicție sunt simple:
predict_Q <- function(Q_fit, dt, a_val) {
nd <- copy(dt)
nd(, a := a_val)
as.numeric(predict(Q_fit, newdata = nd))
}
predict_g <- function(g_fit, dt) {
p <- as.numeric(predict(g_fit, newdata = dt, type = "response"))
pmin(pmax(p, 0.01), 0.99)
}
Estimatoare
Iată o scurtă recapitulare a estimatorilor. Cel mai simplu estimator conectează regresia rezultatului inițial direct în funcționalitatea de identificare:
( hat{psi}^0 =frac{1}{n}sum_{i=1}^n big( hat{Q}_1^0(X_i) − hat{Q}_0^0(X_i) big). )
Acest estimator depinde în mare măsură de calitatea modelului de rezultat.
TMLE începe de la aceleași potriviri neplăcute inițiale, dar apoi actualizează regresia rezultatului de-a lungul unui model de fluctuație unidimensională. Pentru un rezultat continuu, actualizarea este
( hat{Q}^{epsilon}(A,X) = hat{Q}^0(A,X) + epsilon H_{hat{g}}(A,X), )
unde este covariata inteligentă
( H_{hat{g}}(A,X) = frac{A}{hat{g}(X)} − frac{1−A}{1−hat{g}(X)}. )
Coeficientul (epsilon) este ales astfel încât media empirică a reziduului ponderat să fie zero. După actualizarea regresiei, estimarea TMLE este estimatorul plug-in bazat pe regresia vizată:
( hat{psi}^* = frac{1}{n} sum_{i=1}^n big( hat{Q}_1^∗(X_i) − hat{Q}_0^∗(X_i)big). )
Construirea funcţiei de influenţă eficientă
Această funcție de ajutor construiește funcția de influență eficientă odată ce sunt disponibile cantitățile neplăcute și estimarea parametrilor:
phi_ate <- function(dt, Q1, Q0, g, psi) {
A <- dt$a
Y <- dt$y
(Q1 - Q0 - psi) + A / g * (Y - Q1) - (1 - A) / (1 - g) * (Y - Q0)
}
Pasul de direcționare
Pentru rezultatul gaussian folosit aici, pasul de fluctuație poate fi ajustat prin cele mai mici pătrate obișnuite cu un offset. Aceasta ne oferă atât regresia actualizată, cât și media empirică a funcției de influență vizate.
tmle_update_gaussian <- function(dx, Q_fit, g_fit) {
dt <- copy(dx)
dt(, QAW := predict_Q(Q_fit, dt, dt$a))
dt(, Q1 := predict_Q(Q_fit, dt, 1))
dt(, Q0 := predict_Q(Q_fit, dt, 0))
dt(, g := predict_g(g_fit, dt))
dt(, H := a / g - (1 - a) / (1 - g))
# Estimate fluctuation parameter on this data set unless supplied
fluc_fit <- lm(y ~ -1 + offset(QAW) + H, data = dt)
eps <- coef(fluc_fit)(("H"))
# Targeted updates
dt(, QAW_star := QAW + eps * H)
dt(, Q1_star := Q1 + eps / g)
dt(, Q0_star := Q0 - eps / (1 - g))
list(
eps = eps,
Q1 = dt$Q1,
Q0 = dt$Q0,
g = dt$g,
Q1_star = dt$Q1_star,
Q0_star = dt$Q0_star
)
}
Iterații de simulare
Pentru fiecare set de date simulate și fiecare scenariu de modelare neplăcută, țin evidența:
- media empirică absolută a EIF estimat pentru potrivirea plug-in
- media empirică absolută a EIF estimat după țintire
- eroarea absolută a estimării plug-in-ului ATE
- eroarea absolută a estimării TMLE a ATE
Iată funcția care face acest lucru utilizând cross-fitting dublu:
s_estimate <- function(dx, scenario, tau, n, nfolds = 2) {
dt <- copy(dx)
dt(, fold := sample(rep(1:nfolds, length.out = .N)))
# Storage for fold-specific population diagnostics
eps_vec <- numeric(nfolds)
for (k in 1:nfolds) {
train <- dt(fold != k)
test <- copy(dt(fold == k))
fits <- fit_nuisance(train, scenario)
# Sample: fit on train, target/evaluate on held-out test fold
tmle_k <- tmle_update_gaussian(test, fits$Q_fit, fits$g_fit)
eps_vec(k) <- tmle_k$eps
# Write held-out predictions back into main sample object
dt(fold == k, `:=`(
Q1 = tmle_k$Q1,
Q0 = tmle_k$Q0,
g = tmle_k$g,
Q1_star = tmle_k$Q1_star,
Q0_star = tmle_k$Q0_star
))
}
# Cross-fitted sample estimators
psi_plugin <- mean(dt$Q1 - dt$Q0)
psi_tmle <- mean(dt$Q1_star - dt$Q0_star)
pn_phi_plugin <- mean(
phi_ate(
dt,
Q1 = dt$Q1,
Q0 = dt$Q0,
g = dt$g,
psi = psi_plugin
)
)
pn_phi_tmle <- mean(
phi_ate(
dt,
Q1 = dt$Q1_star,
Q0 = dt$Q0_star,
g = dt$g,
psi = psi_tmle
)
)
data.table(
tau = tau,
n = n,
scenario = scenario,
psi_true = tau,
psi_plugin = psi_plugin,
psi_tmle = psi_tmle,
abs_pn_phi_plugin = abs(pn_phi_plugin),
abs_pn_phi_tmle = abs(pn_phi_tmle),
abs_err_plugin = abs(psi_plugin - tau),
abs_err_tmle = abs(psi_tmle - tau),
eps = mean(eps_vec)
)
}
Pentru fiecare set de date generat (pe baza unei dimensiuni specifice de eșantion), am încadrat patru modele, câte unul pentru fiecare set de scenarii de specificare a modelului neplăcut:
s_simulate <- function(n, tau, scenarios) {
dd <- gen_dgp(n, tau)
rbindlist(lapply(scenarios, function(s) s_estimate(dd, s, tau, n)))
}
Executarea simulărilor
Creez 1000 de seturi de date pentru fiecare dimensiune posibilă a eșantionului, variind de la 100 la 2000:
set.seed(2026)
tau <- 5
ns = rep(c(100, 250, 750, 1000, 2000), each = 1000)
scenarios <- c("both_correct", "Q_wrong", "g_wrong", "both_wrong")
res <- rbindlist(
lapply(ns, function(x) s_simulate(x, tau, scenarios))
)
Medie empirică EIF înainte și după direcționare
Mai jos este un grafic care arată distribuția mediei empirice absolute a EIF pentru fiecare dintre scenariile definite de dimensiunea eșantionului și de estimarea parametrilor de neplăcere atât înainte, cât și după țintire. Au fost generate 1000 de seturi de date pentru fiecare scenariu:
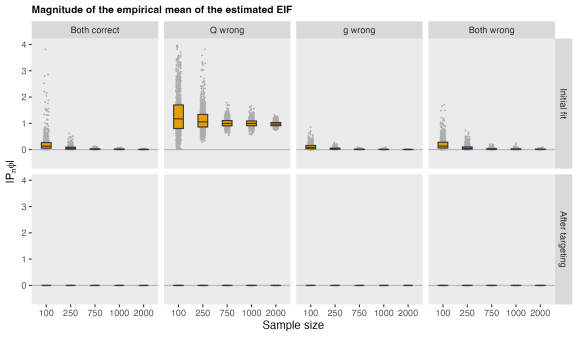
Înainte de țintire, media empirică a EIF estimat este adesea vizibil departe de zero, în special în eșantioane mai mici și sub specificație greșită, în special atunci când modelul de rezultat este specificat greșit. După țintire, acel dezechilibru se prăbușește practic la zero în fiecare scenariu, deoarece pasul de fluctuație este construit pentru a face acest lucru să se întâmple.
Cu toate acestea, acest echilibru este aplicat în eșantion, nu neapărat în populație. În simulări suplimentare (nu sunt afișate aici), am descoperit că, chiar și după țintire, media populației a EIF estimat poate rămâne diferită de zero atunci când modelele neplăcute sunt specificate greșit. Când se întâmplă acest lucru, estimatorul rămâne părtinitor (a se vedea mai jos), în concordanță cu faptul că eroarea de estimare este determinată de media populației a EIF.
Acesta corespunde celui de-al doilea termen descris în postarea anterioară: atunci când modelele de neplăcere sunt specificate greșit, funcția de influență vizată diferă de cea adevărată din populație, iar discrepanța respectivă apare ca părtinire în estimator. În acest sens, țintirea și dubla robustețe joacă roluri complementare: garanții de țintire balanța probei (adică, (P_n phi_{hat{P}^*} = 0)), în timp ce dubla robustețe ajută la asigurare echilibrul populației (adică, (P_0 phi_{hat{P}^*} aproximativ 0)) când cel puțin un model de pacoste este corect specificat.
Performanța estimatorului
Scopul, desigur, nu este doar de a face o ecuație de estimare să pară ordonată. Întrebarea reală este dacă acest lucru schimbă comportamentul estimării parametrilor în sine.
![]()
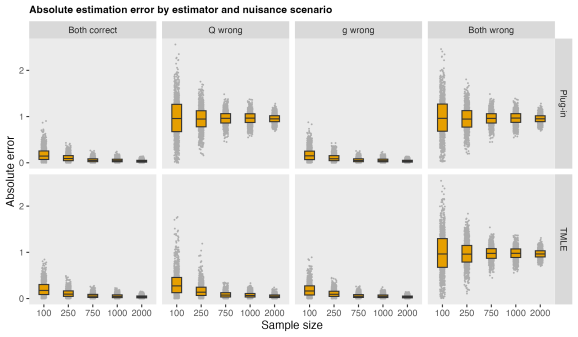
Când ambele modele neplăcute sunt specificate corect, ambii estimatori se comportă bine. Cu toate acestea, atunci când modelul de rezultat este greșit, dar modelul de înclinație este corect, estimatorul plug-in se luptă deoarece depinde direct de regresia rezultatului specificat greșit. În contrast, estimatorul TMLE rămâne mult mai stabil deoarece folosește corecția reziduală bazată pe propensiune. Aceasta este dublă robustețe în acțiune. Atunci când modelul de înclinație este greșit, dar modelul rezultat este corect, estimatorul plug-in încă funcționează bine și TMLE rămâne, de asemenea, consecvent. Atunci când ambele modele de neplăcere sunt greșite, niciunul dintre estimatori nu se comportă bine, evidențiind faptul că TMLE nu este un panaceu.
Gânduri finale
Postarea anterioară a susținut că TMLE funcționează prin ajustarea ușoară a potrivirii neplăcute până când ecuația empirică influență-funcție este readusă în echilibru. Această simulare face această afirmație vizibilă. Înainte de direcționare, EIF estimat poate fi vizibil decentrat. După direcționare, este efectiv zero prin construcție.
Dar acest echilibru este aplicat în eșantion, nu neapărat în populație. Atunci când modelele de neplăcere sunt specificate greșit, funcția de influență vizată poate diferi de cea adevărată, iar media populației sale poate rămâne diferită de zero. În aceste cazuri, estimatorul rămâne părtinitor, chiar dacă ecuația empirică EIF este perfect satisfăcută.
Acest lucru evidențiază rolul central al funcției de influență: țintirea asigură că estimatorul se comportă ca expansiunea ideală de ordinul întâi în datele observate, dar performanța sa finală depinde încă de cât de bine reflectă funcția de influență estimată adevăratul proces de generare a datelor.
Funcția de influență eficientă joacă, de asemenea, un rol central în inferență, deoarece varianța sa empirică este de obicei utilizată pentru a estima eroarea standard a TMLE. Nu m-am concentrat aici pe acest aspect, deoarece scopul acestor simulări a fost de a înțelege modul în care țintirea afectează părtinirea și stabilitatea. Când FEI se comportă bine, nu numai că se centrează în mod corespunzător, ci oferă și o modalitate naturală de cuantificare a incertitudinii. Sper să revin la această idee în setari mai aplicate pe viitor.
Referinţă
Van der Laan, Mark J. și Sherri Rose. Învățare direcționată: inferență cauzală pentru date observaționale și experimentale. Vol. 4. New York: Springer, 2011.
Sprijin
Această activitate a fost susținută de Institutul Național pentru Îmbătrânire (NIA) al National Institutes of Health sub Numărul de atribuire U54AG063546, care finanțează NIA IMbedded Pragmatic Alzheimer Disease and AD-Related Dementias Clinical Trials Collaboratory (NIA IMPACT Collaboratory). Autorul, membru al Design and Statistics Core, a fost singurul scriitor al acestei postări pe blog și nu are conflicte. Conținutul este responsabilitatea exclusivă a autorului și nu reprezintă neapărat opiniile oficiale ale National Institutes of Health.