(Acest articol a fost publicat pentru prima dată pe blogul pharmaverseși cu amabilitate a contribuit la R-bloggeri). (Puteți raporta problema legată de conținutul acestei pagini aici)
Doriți să vă distribuiți conținutul pe R-bloggeri? dați clic aici dacă aveți un blog, sau aici dacă nu aveți.
Disclaimer: Acest blog conține opinii care aparțin exclusiv autorilor și nu reflectă neapărat strategia organizațiilor respective.
De ce contează acest lucru pentru programatorii pharmaverse
Raportarea clinică este construită pe modele repetabile pentru derivări ADaM, TLG și QC, dar găsirea acestor modele este o provocare semnificativă. Codul relevant este adesea împrăștiat, iar căutările tradiționale de cuvinte cheie eșuează pentru logica non-standard, deoarece numele variabilelor subiacente și convențiile structurale diferă de la studiu la studiu. CSA abordează în mod direct această cauză rădăcină utilizând regăsirea semantică pentru a găsi codul bazat pe intenția sa conceptuală, nu doar cuvintele cheie care se potrivesc (de exemplu: interogare în limba engleză simplă, cum ar fi „derivați ABLFL în ADLB folosind o regulă de referință pre-doză și ferestre de analiză-vizită”). Aceasta înseamnă că programatorii pot descoperi, revizui și reutiliza în mod fiabil modelele relevante din toate depozitele, economisind timp substanțial și asigurând o mai mare coerență în munca lor.
Ce am construit?
CSA este un agent concentrat în cadrul asistentului nostru de analiză clinică. Un utilizator pune o întrebare; creăm o încorporare a acelei interogări, aplicăm filtre de metadate opționale, căutăm în baza de date vectorială și returnăm cele mai relevante bucăți de cod alături de originile lor. CSA acceptă atât programele SAS, cât și R.
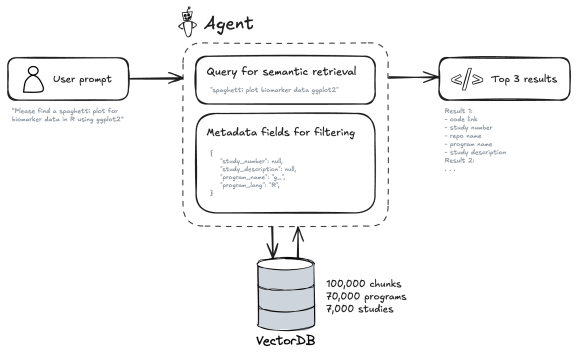
În culise, indexăm codul din depozitele noastre, îl împărțim în bucăți coerente și generăm scurte rezumate care descriu ceea ce face fiecare fragment de cod. Apoi convertim aceste rezumate în reprezentări numerice numite înglobări (sau vectori), care surprind semnificația lor semantică. Acest lucru permite sistemului să găsească codul bazat pe ideea a ceea ce face, nu doar pe potrivirea cuvintelor cheie. Stocăm acești vectori într-o bază de date specializată (bază de date vectoriale) și reținem metadate bogate, cum ar fi limbajul de programare, numele fișierului, depozitul și descrierea studiului. Interfața afișează atât rezultatele, cât și parametrii utilizați, astfel încât recuperarea să rămână transparentă și ușor de auditat.
Iată un exemplu de chunk și metadatele sale stocate în baza de date vectorială.
| Metadate: Numele programului | t_vs_orth.R |
| Metadate: Titlu TLG | Rezumatul modificării ortostatice |
| Metadate: Notă de subsol TLG | Rezultat (Modificare ortostatică) = Semn Vital în picioare – Semn Vital în decubit | Coloana All Placebo include participanții cărora li sa administrat placebo din toate cohortele. |
| Cod (trunchiat) | library(magrittr)library(citril)library(chevron)… adam_db <- read_adam(parquet = arrow::read_parquet, select = c("adsl", "advs"))… adam_db((dataset)) <- adam_db((dataset)) %>%filter(.data$ANL01FL == "Y" & .data$AVISIT != "UNSCHEDULED" & .data$DTYPE == "AVERAGE"...)mutate(AVISIT = str_replace(.data$AVISIT, "BASELINE", "Baseline"), ...)… final_tlg <- citril::decorate_tlg(tlg_output, ...)export_tlg(final_tlg, file = output) |
| Rezumat semantic | Scriptul R t_vs_orth.R analizează modificările ortostatice ale semnelor vitale prin calculul diferenței dintre măsurătorile în picioare și în decubit dorsal. Se foloseste adam_db$adsl şi adam_db$advs seturi de date, filtre pentru înregistrările relevante (ANL01FL == "Y", AVISIT != "UNSCHEDULED", DTYPE == "AVERAGE"), calculează variabila CHG (modificare față de linia de bază), standardizează etichetele vizitelor și creează o categorie de tratament „Toate” grupate… Tabelul de ieșire este exportat în mai multe formate cu titluri și note de subsol decorate. |
| Înglobări (eșantion) | (0.023, -0.145, 0.089, 0.234, -0.067, 0.178, -0.023, 0.145, 0.312, -0.089, 0.156, -0.234, 0.067, 0.298, -0.178, 0.045, ...)(vector 768-dimensional – trunchiat pentru afișare) |
Imaginea VectorDB și a vectorilor.
Cum funcționează
Înțelege întrebarea
Transformăm întrebarea utilizatorului într-o interogare de căutare semantică + filtre de metadate folosind kitul de dezvoltare software pentru agenți OpenAI.
Recuperare cu context
Efectuăm o căutare semantică peste baza de date vectorială și aplicăm potrivirea subșirurilor pe baza filtrelor de metadate. Rezumatele ajută la potrivirea intenției („derive AVALC de la PARAMCD”), chiar dacă fragmentul folosește nume de variabile diferite. Filtrele de metadate ajută la restrângerea rezultatelor la cele mai relevante fragmente (de exemplu: adsl în numele programului sau faza III în descrierea studiului). Codul de pe ramura „dezvoltare” a fost, în general, verificat în configurația noastră, ceea ce este o caracteristică bună pentru reutilizarea codului.
Întoarcerea cu proveniența
Rezultatele arată textul fragmentului, calea fișierului, depozitul și orice metadate de studiu disponibile. Puteți sări la sursă pentru revizuire și reutilizare.
Principiul de proiectare: recuperarea trebuie să fie rapidă, explicabilă și reproductibilă. Ar trebui să fie posibilă urmărirea codului până la sursa originală.
Exemplu
![]()
Ce pot face programatorii astăzi
Cu CSA, programatorii pot căuta scripturi ADaM și TLG prin intenție, cum ar fi „cererea unui semnal de bază ADSL cu fereastră de vizită” sau „un AVALC cartografiere care tratează în mod explicit valorile lipsă”. Ei pot găsi programe TLG descrise în limba engleză simplă. De exemplu, un tabel care împarte coloanele în funcție de brațul de tratament și rezumă AVAL cu medie și abatere standard și apoi adaptează un aspect dovedit. De asemenea, ei pot compara implementări similare în depozite pentru a converge către o abordare standard, păstrând în același timp încrederea prin proveniența clară înapoi la sursă.
Valori și utilizare
În fereastra de observare (15 septembrie 2025 – 19 octombrie 2025), Code Search Assistant (CSA) a gestionat 791 de întrebări de la 45 de utilizatori unici, cu o medie de 42 ± 14 conversații săptămânale și 92 ± 43 de întrebări săptămânale. Semnalele de satisfacție au fost pozitive: Asistentul de analiză clinică (CAA) mai larg a obținut un scor de 3,39/5 pentru utilitate (n = 174), în timp ce CSA a fost evaluat în mod specific la ~4/5, indicând o tracțiune precoce puternică în rândul utilizatorilor activi.
Limitări și ce urmează
Astăzi, CSA se concentrează pe descoperirea rapidă și de încredere. Lucrăm la o integrare mai strânsă a IDE prin MCP (Model Context Protocol – introdus de Anthropic), astfel încât să puteți căuta direct din editorul de cod (VSCode, RStudio etc.). De asemenea, dorim să permitem o mai bună cunoaștere a studiului, astfel încât rezultatele să fie filtrate automat în contextul studiului dvs. și al codului de programare clinică. În cele din urmă, rafinăm conducta de date pentru a indexa continuu modificările fără niciun efort manual și adăugăm și programe SDTM. Acești pași urmăresc să facă recuperarea nu numai mai inteligentă, ci și să fie integrată mai perfect în programarea de zi cu zi.
Ultima actualizare
2026-03-20 18:34:22.238493
Detalii
Reutilizați
Citare
citare BibTeX:
@online{cayssol2026,
author = {Cayssol, Mathieu},
title = {Beyond {Keywords:} {How} {Semantic} {Search} Is {Unlocking}
{Clinical} {Code} {Reuse}},
date = {2026-03-20},
url = {https://pharmaverse.github.io/blog/posts/2026-03-20_beyond_key_words/beyond__keywords.html},
langid = {en}
}
Pentru atribuire, vă rugăm să citați această lucrare ca:
Cayssol, Mathieu. 2026. „Dincolo de cuvintele cheie: modul în care căutarea semantică deblochează reutilizarea codului clinic.” 20 martie 2026. https://pharmaverse.github.io/blog/posts/2026-03-20_beyond_key_words/beyond__keywords.html.