TLDR: Pentru a testa dacă pot face diferența dintre cafelele decofeinizate, am efectuat un test extrem de științific (supus constrângerilor de finanțare).
Unul dintre obiectivele mele pentru 2025 a fost să-mi reduc aportul de cofeină după ce am avut prea multe nopți nedormite. Problema a fost că toată cafeaua decofeinizată pe care am încercat-o era groaznică.
Sau a fost?
La urma urmei, odată m-am numit un audiofil până când o serie de teste A/B au sugerat că nu pot face diferența dintre melodiile codificate la rate de biți diferite. Deci, era cu totul posibil să fi fost spălat de creier cafea mare a crede că cafeaua decofeinată era inferioară.
Dar cum am putea testa asta mai exact?
Cea mai evidentă soluție a fost de a desfășura un experiment randomizat dublu-orb. În acest fel, nu mi-aș baza automat resentimentele pe starea de cafea cu cofeină şi concentrați-vă pe evaluarea mea subiectivă a calității fiecărei cafele.
Care este cam ceea ce am făcut:
Pasul 1: Selectarea eșantionului
Primul pas a fost selectarea unui eșantion suficient de mare de boabe de cafea pentru a face studiul cât mai științific posibil. Împingând soția mea pentru a ajuta, am achiziționat cât mai multe soiuri decofeinizate pe care le-am putut pune mâna.
Pasul 2: orbirea probei
După ce am selectat o mostră mare reprezentativă de cafele (n=6), am împachetat câte o probă din fiecare în recipientul său (în imagine). Pentru a ascunde identitatea fiecărei cafele, le-am atribuit un număr de la 1 la 6. Pentru a îmbunătăți și mai mult știința, am cerut soției mele să atribuie numere noi, astfel încât niciunul dintre noi nu știa originea fiecărei mostre.

Pasul 3: Testare
Înainte de a începe testul am curățat și detartrat aparatul de cafea. Boabele din fiecare recipient au fost proaspăt măcinate la temperatura camerei și folosite pentru a face șase espresso-uri separate. Fotografiile au fost desenate pe o bază cvasialeatorie, în funcție de ceea ce mi-a înmânat soția mea. Am luat apoi o înghițitură din fiecare cafea și ne-am clasat preferințele de la unu la șase.

Pasul 4: Rezultate
Deși mi-ar fi plăcut să-mi preînregistrez cercetarea, niciuna dintre cele mai importante reviste econometrice pe care le-am contactat nu și-a exprimat interesul. Cu toate acestea, presupunerea mea generală a fost că preferințele noastre pentru o cafea au fost în principal psihologice și au puțin de-a face cu conținutul ei de cofeină.
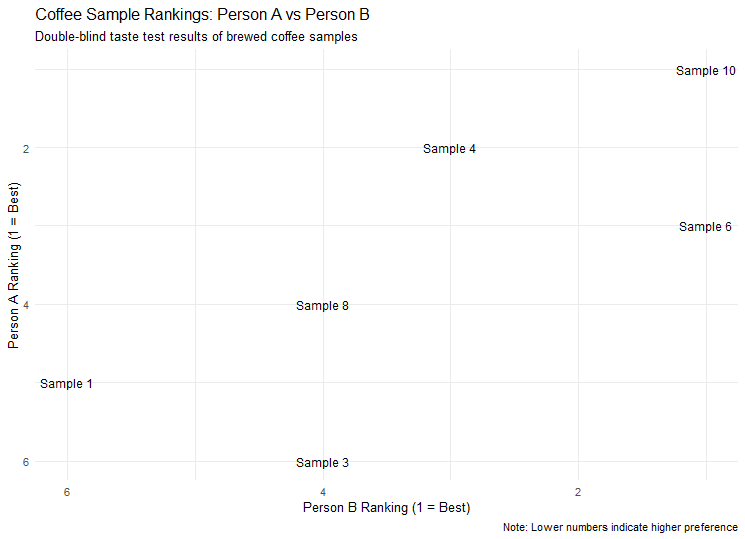
Dacă acest lucru ar fi adevărat, m-aș aștepta să nu văd nicio relație între clasamentele noastre. Dar, spre surprinderea mea, nu părea să fie cazul. În schimb, amândoi am clasat boabele într-o ordine similară:
Fragment de cod:
#load libraries and import data
library(tidyverse)
dta_coffee_science<-read_csv("./Data/250216 blind coffee ratings.csv")
# Show linear association between samples by assigned label
#reverse axis so lower rankings are higher on the axis scale
plt_rankings_by_coffee_no <- ggplot(data = dta_coffee_science,
aes(y = ranking_person_b, x = ranking_person_a)) +
geom_text(aes(label = blind_label_round_2), size = 3.5) +
scale_y_reverse(name = "Person A Ranking (1 = Best)") +
scale_x_reverse(name = "Person B Ranking (1 = Best)") +
labs(title = "Coffee Sample Rankings: Person A vs Person B",
subtitle = "Double-blind taste test results of brewed coffee samples",
caption = "Note: Lower numbers indicate higher preference") +
theme_classic()
plt_rankings_by_coffee_no
Desigur, facem ceva știință adevărată aici, așa că pentru a verifica, să aplicăm Tau-ul de ranguri al lui Kendall și testul de corelație Spearman pentru o ipoteză nulă conform căreia nu există o asociere statistică între clasamentele noastre.
Fragment de cod:
#kendall
cor.test(data=dta_coffee_science,
~ ranking_person_a + ranking_person_b, method = "kendall")
#spearman
cor.test(data=dta_coffee_science,
~ ranking_person_a + ranking_person_b, method = "spearman")
Cu valori p de la șase la opt procente, aceasta nu este o susținere a rezultatelor, dar, după ce am scris deja blogul, sunt bucuros să-mi ajustez definiția semnificativă pentru a concluziona că preferințele noastre erau similare una cu cealaltă.

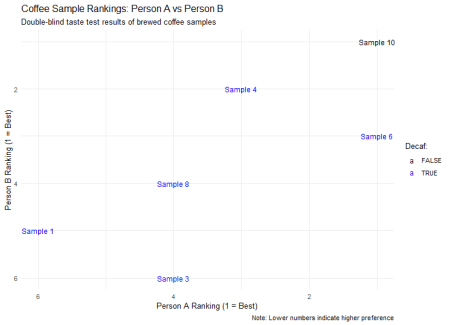
Desigur, dorința mea de a juca rapid și de a pierde cu statisticile provine și din cunoașterea unui rezultat cheie: amândoi am clasat cel mai bine boabele cu cofeină cumpărate din magazin.
Fragment de cod:
# Show linear association between samples by assigned label and caffeination status
plt_rankings_by_caffeine <-ggplot(data=dta_coffee_science,
aes(y=ranking_person_b, x=ranking_person_a,col=decaf))+
geom_text(aes(label = blind_label_round_2), size = 3.5) +
scale_y_reverse(limits = c(7.5, 0.5)) +
scale_x_reverse(limits = c(7.5, 0.5)) +
coord_cartesian(clip = "off") +
labs(title = "Coffee Sample Rankings: Person A vs Person B",
subtitle = "Double-blind taste test results of brewed coffee samples",
caption = "Note: Lower numbers indicate higher preference",
x="Person A Ranking (1 = Best)",
y="Person B Ranking (1 = Best)") +
theme_classic()+
scale_color_manual(values = c("black", "blue"), name = "Decaf:")
plt_rankings_by_caffeine
De asemenea, mi s-a părut surprinzător faptul că boabele de la un furnizor specializat de decofeină nu au fost neapărat clasate mai sus, doar una dintre boabele lor fiind clasată în primele trei:
Fragment de cod:
# Show linear association between samples by assigned label and caffeination status with original labels
plt_rankings_by_caffeine_named <- ggplot(data = dta_coffee_science,
aes(y = ranking_person_b, x = ranking_person_a, col = decaf)) +
geom_text(aes(label = str_wrap(paste0(coffee_brand, ": ", coffee_name), width = 15)),
size = 3.5, lineheight = 0.8) +
scale_y_reverse(limits = c(7.5, 0.5)) +
scale_x_reverse(limits = c(7.5, 0.5)) +
coord_cartesian(clip = "off") + # stop clipping text at panel border
labs(title = "Coffee Sample Rankings: Person A vs Person B",
subtitle = "Double-blind taste test results of brewed coffee samples",
caption = "Note: Lower numbers indicate higher preference",
x = "Person A Ranking (1 = Best)",
y = "Person B Ranking (1 = Best)") +
theme_classic() +
theme(plot.margin = margin(10, 60, 10, 60)) +
scale_color_manual(values = c("black", "blue"), name = "Decaffeinated")
plt_rankings_by_caffeine_named
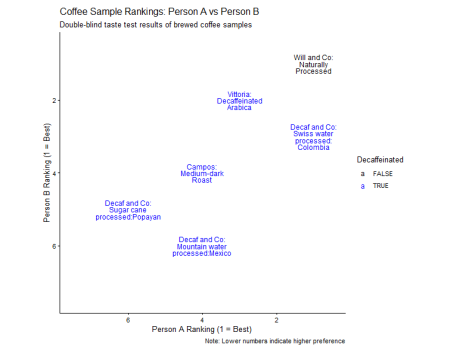
Și în timp ce acești tocilari de cafea ar putea să nu fie de acord, rezultatele sugerează că putem face diferența dintre cafele și ambii preferă alternativa cu cofeină.
Când i-am povestit rezultatul unui chimist alimentar, acesta mi-a spus că probabil că acesta are ceva de-a face cu cafeaua decofeinizată, lipsită de amărăciunea cofeinei.
Când i-am povestit rezultatele soției mele, ea mi-a spus să nu-și mai pierd niciodată timpul așa. Probabil o voi face.
În spiritul științei deschise, puteți descărca setul de date aici.
Postarea Folosind știința pentru a găsi cel mai bun decofeină a apărut mai întâi pe Giles.