(Acest articol a fost publicat pentru prima dată pe R – datawookieși cu amabilitate a contribuit la R-bloggeri). (Puteți raporta problema legată de conținutul acestei pagini aici)
Doriți să vă distribuiți conținutul pe R-bloggeri? dați clic aici dacă aveți un blog, sau aici dacă nu aveți.
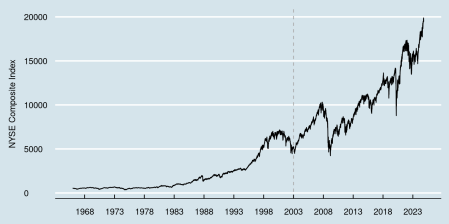
Pentru un proiect secundar, trebuia să răzuiesc datele pentru indicele compus NYSE, care se întorc cât mai mult posibil.
Cea mai convenabilă sursă de date este pe Yahoo! Finanţa.
Ce este indicele compus NYSE?
Indicele NYSE Composite este un indice care include toate acțiunile ordinare listate la Bursa de Valori din New York. Contribuția fiecărei acțiuni la indice (ponderea acestuia) este determinată de capitalizarea de piață a acestuia (valoarea acțiunilor disponibile pentru tranzacționare publică).
Răzuire
M-am gândit să fac răzuirea fie cu R, fie cu Python. După ce am analizat structura site-ului și datele tabulate, am decis să merg cu R.
Biblioteci
Începeți prin a încărca câteva biblioteci indispensabile.
library(httr2) library(rvest) library(dplyr) library(readr) library(janitor)
Ce scop servesc acestea?
httr2— solicitări HTTP (recuperează conținutul HTML al paginii web);rvest— analiza HTML (extragerea conținutului din HTML);dplyr— manipularea datelor;readr— pentruparse_number()funcționalitate și scriere CSV simplă; şijanitor— curățarea numelor de coloane.
Parametrii de interogare
Există doi parametri de interogare, period1 şi period2 care determină durata datelor returnate. Acestea ar trebui să fie setate la valori integrale, în special numărul de secunde de la epoca UNIX. Le-am putea codifica pe acestea, dar prefer să le generez dinamic.
Iată cum facem asta pentru data de începere (31 decembrie 1965):
as.integer(as.POSIXct("1965-12-31"))
(1) -126316800
_ Valoarea este negativă deoarece data respectivă este înainte epoca UNIX (1 ianuarie 1970).
Creați o listă cu valorile parametrilor corespunzătoare.
params <- list(
period1 = as.integer(as.POSIXct("1965-12-31")),
period2 = as.integer(Sys.time())
)
Este necesar un singur antet obligatoriu, care este șirul User Agent.
headers <- list( "User-Agent" = "Mozilla/5.0 (X11; Linux x86_64)" )
Există, de asemenea, o serie de cookie-uri, dintre care doar unul pare a fi important. Conținutul acelui cookie pare să evolueze în timp, așa că va necesita reîmprospătare.
Cerere
Acum avem toate premisele la locul lor. Voi stoca adresa URL într-o variabilă, mai degrabă decât codificarea tare în cerere.
URL <- "https://finance.yahoo.com/quote/^NYA/history/"
Acum construiți cererea folosind {httr2}. Abordarea modulară a acestui lucru este foarte bună. Despachetați listele ca parametri ai funcției folosind !!! (bang-bang-bang), care, în beneficiul Pythonistilor, este echivalentă cu utilizarea ** pe un dicționar.
response <- request(URL) |> req_url_query(!!!params) |> req_cookies_set(!!!cookies) |> req_headers(!!!headers) |> req_perform()
Parse & Wrangle
Apoi luăm obiectul răspuns și extragem corpul HTML. Apoi un pic de răzuire rapidă pe web (folosind html_element() şi html_table() pentru a localiza