(Acest articol a fost publicat pentru prima dată pe R-posts.comși cu amabilitate a contribuit la R-bloggeri). (Puteți raporta problema legată de conținutul acestei pagini aici)
Doriți să vă distribuiți conținutul pe R-bloggeri? dați clic aici dacă aveți un blog, sau aici dacă nu aveți.
Introducere
Universitățile folosesc din ce în ce mai mult pedagogii de învățare colaborativă, care pot beneficia cursanții printr-o înțelegere mai profundă a conținutului cursului și a abilităților de lucru în echipă. Cu toate acestea, realizarea acestor beneficii căutate depinde de modul în care educatorii repartizează cursanții în grupuri.
Educatorii au formulat diverse modele matematice pentru a îndeplini această sarcină. Unii au dezvoltat modele care au prioritizat maximizarea preferințelor de proiecte ale studenților. Alții au dezvoltat un model care a prioritizat preferințele elevilor, mărimea grupului și componența grupului. Totuși, alte modele abordează probleme conexe, dar distincte, cum ar fi atribuirea studenților la cursuri opționale sau încorporarea volumului de muncă al personalului în misiunile de la student la supervizor de proiect.
Indiferent de abordarea utilizată, este evident că este nevoie de o soluție algoritmică pentru atribuire. Acest lucru ar ușura sarcina instructorului, oferind în același timp o procedură obiectivă pentru sarcina. Contribuția noastră este un pachet R grouper care oferă două strategii flexibile de alocare a grupului.
Modele de optimizare
grouper oferă două modele distincte de optimizare a programării liniare întregi.
library(grouper) library(ompr) library(ompr.roi) library(ROI.plugin.glpk)
Atribuire bazată pe preferințe
Modelul de atribuire bazată pe preferințe (PBA) permite educatorilor să atribuie grupuri de studenți la subiecte pentru a maximiza preferințele generale ale elevilor pentru acele subiecte. Subiectele pot fi vizualizate ca titluri de proiecte. Modelul permite repetări ale fiecărui titlu de proiect. Această formulare permite, de asemenea, fiecărei echipe de proiect să cuprindă mai multe subgrupuri. Acest lucru este util în cazurile în care proiectul necesită echipe cu funcționalități diferite să lucreze împreună, de exemplu, în cazul în care o echipă lucrează pe un front-end, în timp ce cealaltă dezvoltă un model back-end.
Pentru a executa rutina de optimizare, un instructor pregătește:
-
-
- Un tabel de alcătuire a grupului care listează elevii membri din fiecare grup autoformat
- O matrice de preferințe care conține preferința pe care fiecare grup autoformat o are pentru fiecare subiect.
- Un fișier YAML care definește parametrii rămași ai modelului.
-
Exemple
Luați în considerare următorul set de date simplu cu 8 studenți:
pba_gc_ex002 #> id grouping #> 1 1 1 #> 2 2 1 #> 3 3 2 #> 4 4 2 #> 5 5 3 #> 6 6 3 #> 7 7 4 #> 8 8 4
Fiecare elev este într-un grup autoformat de mărimea 2, indicat prin intermediul grouping coloană. Să presupunem că, pentru acest set de studenți, instructorul dorește să repartizeze studenții în două subiecte, fiecare subiect având două subgrupe. Acest lucru necesită ca matricea de preferințe să aibă 4 coloane – una pentru fiecare combinație subiect-subgrup. Amintiți-vă că ordinea subiectelor/subtemelor în matricea preferințelor ar trebui să fie:
Subiect1-Subtopic1, Topic2-Subtopic1, Subiect1-Subtopic2, Subiect2-Subtopic2
Astfel, ar trebui să existe 4 rânduri în matricea de preferințe – câte unul pentru fiecare grup autoformat.
pba_prefmat_ex002 #> col1 col2 col3 col4 #> (1,) 4 3 2 1 #> (2,) 3 4 2 1 #> (3,) 1 2 4 3 #> (4,) 1 2 3 4
Fișierul YAML pentru acest model conține următorii parametri:
n_topics: 2 B: 2 R: 1 nmin: 2 nmax: 2 rmin: 1 rmax: 1
B corespunde numărului de subteme pe subiect, în timp ce rmin și rmax indicați numărul minim și maxim de repetări ale fiecărui subiect. nmin și nmax indicați numărul minim și maxim de membri din fiecare subgrup de subiecte.
Este posibil să se atribuie fiecărui grup autoformat alegerea optimă a combinației subiect-subtemă. În soluția noastră, ar trebui să vedem că grupul 1 este alocat subsubiectului 1 al subiectului 1, grupul 2 este alocat subsubiectului 1 al subiectului 2 și așa mai departe.
df_ex002_list <- extract_student_info(pba_gc_ex002, "preference",
self_formed_groups = 2,
pref_mat = pba_prefmat_ex002)
yaml_ex002_list <- extract_params_yaml(system.file("extdata",
"pba_params_ex002.yml",
package = "grouper"),
"preference")
m2 <- prepare_model(df_ex002_list, yaml_ex002_list, "preference")
result2 <- solve_model(m2, with_ROI(solver="glpk"))
assign_groups(result2, assignment = "preference",
dframe=pba_gc_ex002, yaml_ex002_list,
group_names="grouping")
#> topic2 subtopic rep group size
#> 1 1 1 1 1 2
#> 2 2 1 1 2 2
#> 3 1 2 1 3 2
#> 4 2 2 1 4 2
Misiunea bazată pe diversitate
Modelul Diversity-Based Assignment (DBA) le permite educatorilor să repartizeze elevii pe grupuri și subiecte cu obiectivele duble, dar ponderate, de a maximiza diversitatea (pe baza atributelor elevilor) în cadrul grupurilor și de a echilibra nivelurile specifice de abilități din diferite grupuri.
Pentru a executa rutina de optimizare DBA, instructorul pregătește:
-
-
- Un tabel de compoziție de grup care conține:
- elevii membri din cadrul fiecărui grup autoformat,
- datele demografice care vor fi utilizate pentru a calcula diferențele pe perechi între elevi și
- o măsură numerică a aptitudinilor fiecărui elev.
- Un fișier YAML care definește parametrii rămași ai modelului.
- Un tabel de compoziție de grup care conține:
-
Exemple
Luați în considerare următorul set de date, care vine cu pachet. Sunt 4 elevi în total.
dba_gc_ex001 #> id major skill groups #> 1 1 A 1 1 #> 2 2 A 1 2 #> 3 3 B 3 3 #> 4 4 B 3 4
Este intuitiv ca o temă în două grupe de mărimea doi, bazată numai pe diversitatea specializărilor, ar trebui să repartizeze studenții 1 și 2 în primul grup și ceilalți doi studenți într-un alt grup.
YAML corespunzătoare dba_gc_ex001.yml fișierul pentru acest exercițiu este format din următoarele rânduri:
n_topics: 2 R: 1 nmin: 2 nmax: 2 rmin: 1 rmax: 1
Pentru a rula misiunea, putem folosi următoarele comenzi. Putem folosi fie solutorul gurobi, fie solutorul glpk pentru acest exemplu. Ambele sunt la fel de rapide.
# Indicate appropriate columns using integer ids.
df_ex001_list <- extract_student_info(dba_gc_ex001, "diversity",
demographic_cols = 2,
skills = 3,
self_formed_groups = 4)
yaml_ex001_list <- extract_params_yaml(system.file("extdata",
"dba_params_ex001.yml",
package = "grouper"),
"diversity")
m1 <- prepare_model(df_ex001_list, yaml_ex001_list,
assignment="diversity",w1=0.5, w2=0.5)
result3 <- solve_model(m1, with_ROI(solver="glpk"))
assign_groups(result3, assignment = "diversity",
dframe=dba_gc_ex001,
group_names="groups")
#> topic rep group id major skill
#> 1 1 1 2 2 A 1
#> 2 1 1 3 3 B 3
#> 3 2 1 1 1 A 1
#> 4 2 1 4 4 B 3
Putem observa că elevii 2 și 3 au fost repartizați la tema 1, repetarea 1. Elevii 1 și 4 au fost repartizați la subiectul 2, repetarea 1. w1 și w2 ambele au ponderi de 0,5, ceea ce înseamnă că competențele și inputurile demografice au o pondere egală în optimizare.
În prezent, rutinele folosesc funcția daisy din pachetul cluster pentru a calcula o matrice de disimilaritate pe perechi între studenți. Cu toate acestea, este, de asemenea, posibil să vă furnizați propria matrice personalizată de diferențe. Luați în considerare următorul set de date de 4 studenți:
dba_gc_ex003 #> year major self_groups id #> 1 1 math 1 1 #> 2 2 history 2 2 #> 3 3 dsds 3 3 #> 4 4 elts 4 4
Acum luați în considerare o situație în care dorim să considerăm anii 1 și 2 diferiți de anii 3 și 4 și math şi dsds (specializări STEM) să fie diferit de elts şi history (specializări non-STEM). Pentru fiecare diferență, atribuim un scor de 1. Aceasta înseamnă că elevii 1 și 2 ar avea un scor de diferență de 1 din cauza diferenței lor în specializări. Elevii 1 și 3 ar avea, de asemenea, un punctaj de 1, dar datorită diferenței lor de ani. Elevii 1 și 4 ar avea un punctaj de 2, datorită diferențelor lor în specializări și în ani. Matricea generală de diferențe ar fi:
d_mat <- matrix(c(0, 1, 1, 2,
1, 0, 2, 1,
1, 2, 0, 1,
2, 1, 1, 0), nrow=4, byrow = TRUE)
Pentru a rula optimizarea pentru acest model, putem executa următorul cod:
df_ex003_list <- extract_student_info(dba_gc_ex003, "diversity",
skills = NULL,
self_formed_groups = 3,
d_mat=d_mat)
yaml_ex003_list <- extract_params_yaml(system.file("extdata",
"dba_params_ex003.yml",
package = "grouper"),
"diversity")
m3 <- prepare_model(df_ex003_list, yaml_ex003_list, w1=1.0, w2=0.0)
result <- solve_model(m3, with_ROI(solver="glpk")
assign_groups(result, "diversity", dba_gc_ex003,
group_names="self_groups")
#> topic rep group year major id
#> 1 1 1 1 1 math 1
#> 2 1 1 4 4 elts 4
#> 3 2 1 2 2 history 2
#> 4 2 1 3 3 dsds 3
După cum puteți vedea, membrii celor două grupuri au diferență maximă între ei – diferă în ceea ce privește anul lor, şi în ceea ce priveşte majora lor. Observați că am specificat
skills = NULL
şi
w2 = 0.0
Acest lucru asigură că nicio coloană de competențe nu a fost luată în considerare în această optimizare.
Gurobi Optimizer
În timp ce rutinele de mai sus folosesc optimizatorul glpk, vă recomandăm să utilizați optimizatorul Gurobi. Acesta din urmă este un software comercial care rulează până la finalizare mult mai rapid decât glpk. Pentru mai multe informații, vă rugăm să consultați acest site web. Rețineți că licențele academice sunt disponibile de la Gurobi.
Aplicații strălucitoare
Pachetul oferă numeroase opțiuni pentru fiecare dintre cele două modele de optimizare. Cu toate acestea, sunt incluse și două aplicații strălucitoare în pachet. Ele pot fi utile dacă aveți nevoie doar de o sarcină de grup simplă.
Pentru a rula aplicația DBA strălucitoare, următorul cod va fi suficient:
library(shiny)
runApp(appDir=system.file("shiny", "dbaWebApp", package="grouper"))
# Analogous code for PBA app:
# runApp(appDir=system.file("shiny", "pbaWebApp", package="grouper"))
Iată o captură de ecran a aplicației strălucitoare bazate pe diversitate.
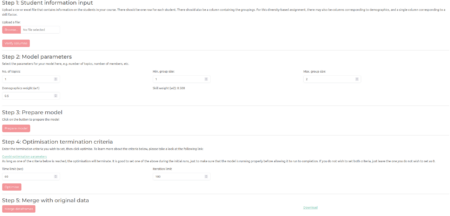
Dosarele de sistem cu aplicațiile strălucitoare conțin și exemple de fișiere csv pentru a fi utilizate cu aplicațiile.
Mai multe detalii
Cele două modele de optimizare sunt parametrizate în mod flexibil. Iată câteva dintre caracteristici:
-
- Definiți numărul de repetări pentru fiecare subiect.
- Definiți valoarea maximă. și min. numărul de membri ai grupului pentru fiecare subiect.
Vignetele conțin și formularea matematică precisă a modelelor de optimizare. Pentru detalii complete, vă rugăm să consultați aceste link-uri:
grouper: un pachet R pentru atribuirea optimă a grupului a fost postat pentru prima dată pe 29 aprilie 2026, la ora 6:18.