
Un mare ![]()
 poate face ca un model de regresie să pară impresionant de precis – dar acest număr poate fi înșelător. Dacă vrei să înțelegi de ce un mare
poate face ca un model de regresie să pară impresionant de precis – dar acest număr poate fi înșelător. Dacă vrei să înțelegi de ce un mare ![]() nu este întotdeauna un semn al unui model bun, citiți mai departe!
nu este întotdeauna un semn al unui model bun, citiți mai departe!
În postarea, Learning Data Science: Modeling Basics, am construit un model simplu pentru a estima veniturile în funcție de vârstă. R a tipărit un rezumat al modelului care conține ceva numit R-squareddar nu am discutat încă ce înseamnă de fapt acea valoare.
La prima vedere, un mare ![]() pare extrem de liniştitor. În exemplul nostru, modelul liniar a realizat un
pare extrem de liniştitor. În exemplul nostru, modelul liniar a realizat un ![]() aproape de 90%. Sună impresionant.
aproape de 90%. Sună impresionant.
Cu toate acestea, la fel de înaltă precizie de clasificare poate fi înșelătoare – așa cum se discută în ZeroR: The Simplest Possible Clasifier sau de ce înaltă acuratețe poate fi înșelătoare – un nivel ridicat ![]() poate crea, de asemenea, un fals sentiment de încredere.
poate crea, de asemenea, un fals sentiment de încredere.
Pentru a înțelege de ce, vă ajută să examinați formula în sine și apoi să revizuiți cele trei modele din postarea anterioară: the model mediucel model liniarși model polinom.
Sensul lui 
Coeficientul de determinare este definit ca:

La prima vedere, formula pare intimidantă, dar ideea sa de bază este relativ simplă.
Numitorul

măsoară variația totală a variabilei țintă. Cuantifică cât de puternic diferă valorile observate de media lor.
Numărătorul

măsoară eroare neexplicată rămasă după montarea modelului.
Astfel, ![]() măsoară proporția de variație explicată de model.
măsoară proporția de variație explicată de model.
Un ![]() de:
de:
- 0 înseamnă că modelul nu explică nicio variație,
- 1 înseamnă că modelul explică perfect toate variațiile.
Acest lucru sună destul de simplu. Dificultatea este că explicarea perfectă a datelor observate nu este neapărat același lucru cu construirea unui model predictiv util.
Modelul mediu
Să începem cu cel mai simplu model de regresie posibil.
Să presupunem că ignorăm complet vârsta și pur și simplu prezicem venitul mediu pentru fiecare individ:

Acesta este efectiv echivalentul de regresie al lui ZeroR. Modelul nu învață deloc nicio relație.
În acest caz:

Prin urmare, suma reziduală a pătratelor devine identică cu suma totală a pătratelor:

Înlocuind aceasta în formulă, rezultă:

Modelul nu explică nicio variație a datelor.
Aceasta corespunde cu submontare cazul discutat anterior: modelul este prea simplu pentru a surprinde structura de bază.
Modelul polinom
Acum luați în considerare extrema opusă.
În loc să potrivim o linie dreaptă, să presupunem că potrivim un polinom de grad suficient de mare. De fapt, dacă avem ![]()
 observatii cu valori distincte de varsta, un polinom de grad pana la
observatii cu valori distincte de varsta, un polinom de grad pana la ![]()
 poate trece exact prin toate punctele de date observate:
poate trece exact prin toate punctele de date observate:

In acest caz:

pentru toate observațiile, implicând:

si prin urmare:

Modelul realizează o potrivire perfectă.
La prima vedere, acest lucru pare ideal. În practică, totuși, un astfel de model are adesea performanțe slabe pe datele nevăzute, deoarece s-a adaptat nu numai la relația de bază, ci și la fluctuațiile aleatoare și la zgomotul din datele de antrenament.
Acesta este clasicul supraadaptare problemă.
Un perfect ![]() prin urmare, poate indica nu un model deosebit de bun, ci un model care a devenit prea flexibil.
prin urmare, poate indica nu un model deosebit de bun, ci un model care a devenit prea flexibil.
Modelul liniar
Modelul liniar din postul precedent se află între aceste două extreme.
Este suficient de simplu pentru a evita memorarea oricărei fluctuații aleatorii, dar suficient de flexibil pentru a capta o tendință semnificativă în date.
Acest echilibru între simplitate și flexibilitate este una dintre temele centrale în învățarea statistică.
Ideea a fost rezumată în postarea anterioară cu următorul complot:
![]()
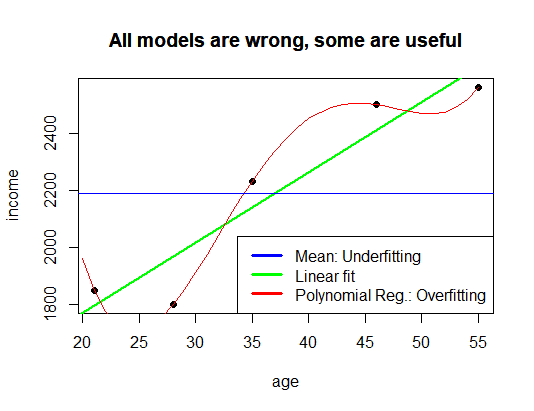
și prin celebra observație atribuită lui George Box:
„Toate modelele sunt greșite, dar unele sunt utile.”
Prin urmare, obiectivul modelării nu este de a maximiza complexitatea sau de a maximiza ![]() ci pentru a găsi un model care să generalizeze cu mult dincolo de eșantionul observat.
ci pentru a găsi un model care să generalizeze cu mult dincolo de eșantionul observat.
De ce Singur este insuficient
Limitarea cheie a ![]() este că evaluează potrivirea numai pe datele observate.
este că evaluează potrivirea numai pe datele observate.
Nu măsoară direct:
- performanță predictivă pe date nevăzute,
- robusteţe,
- validitate cauzală sau
- capacitatea de generalizare.
Pe măsură ce complexitatea modelului crește, ![]() aproape întotdeauna crește și el. Un model suficient de flexibil poate atinge adesea valori foarte apropiate de 1 chiar și atunci când previziunile sale asupra datelor noi sunt slabe.
aproape întotdeauna crește și el. Un model suficient de flexibil poate atinge adesea valori foarte apropiate de 1 chiar și atunci când previziunile sale asupra datelor noi sunt slabe.
Din acest motiv, știința practică a datelor se bazează pe metode suplimentare de evaluare, cum ar fi:
- secțiuni de tren-test,
- validare încrucișată,
- regularizare,
- ajustat și
- testarea în afara eșantionului.
Scopul nu este de a reproduce perfect observațiile istorice, ci de a construi modele care să rămână utile atunci când sunt confruntați cu date noi.
Un mare ![]() Prin urmare, poate însemna două lucruri foarte diferite:
Prin urmare, poate însemna două lucruri foarte diferite:
- modelul a identificat o structură autentică,
- sau modelul sa adaptat prea mult la datele de antrenament.
Distingerea acestor posibilități este una dintre provocările centrale ale învățării automate și ale modelării statistice.