(Acest articol a fost publicat pentru prima dată pe R pe kieranhealy.orgși cu amabilitate a contribuit la R-bloggeri). (Puteți raporta problema legată de conținutul acestei pagini aici)
Doriți să vă distribuiți conținutul pe R-bloggeri? dați clic aici dacă aveți un blog, sau aici dacă nu aveți.
Săptămâna aceasta, în Modern Plain Text Computing, am reunit câteva dintre lucrurile pe care le-am învățat despre curățarea și ordonarea datelor. Iată un exemplu oarecum îngrijorător folosind date din Sistemul de raportare a analizei mortalității, care este modul în care NTSA urmărește informațiile despre accidentele rutiere din Statele Unite. Fișierul nostru de date arată numărul de pietoni cu vârsta <16 uciși în accidente rutiere în fiecare zi a lunii în Statele Unite, din 2008 până în 2022.
Datele ajung, așa cum se întâmplă foarte des, într-o foaie de calcul care nu este ordonată. Arata cam asa:
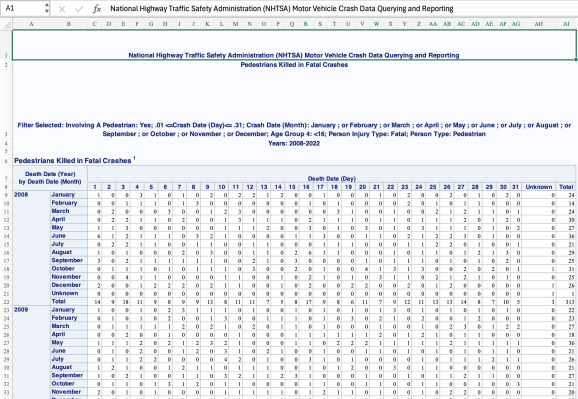
Foaia de calcul Excel pe care o obținem din interogarea datelor FARS cu instrumentul său online de generare de rapoarte.
Să încercăm să-l citim cât de curat putem, sărind peste câteva rânduri de metadate din partea de sus. Acestea sunt bine să ne reamintească exact ce interogare am executat, dar nu fac parte din setul de date în sine.
r
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
library(tidyverse)
library(here)
library(socviz)
fars_raw <- readxl::read_xlsx(here("files", "examples", "fars_crash_report.xlsx"),
skip = 7)
#> New names:
#> • `` -> `...1`
#> • `` -> `...2`
fars_raw |>
print(n=35)
#> # A tibble: 221 × 35
#> ...1 ...2 `1` `2` `3` `4` `5` `6` `7` `8` `9` `10` `11` `12` `13` `14` `15` `16` `17` `18` `19` `20` `21` `22`
#>
|
Trebuie să facem ordine. Primele două coloane nu au nume proprii. Este în format larg și lunile nu sunt completate în coloane. Avem și un Total valoarea din coloana zilei. Știm numele coloanelor, așa că le putem furniza manual.
r
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
colnames(fars_raw) <- c("year", "month", 1:31, "unknown", "total")
fars <- fars_raw |>
# Drop 'Unknown' and 'Total' rows
select(!all_of(c("unknown", "total"))) |>
# Make sure there's no leading or trailing whitespace
mutate(year = str_squish(year),
month = str_squish(month)) |>
# Remove 'Unknown' and 'Total' rows
filter(month %nin% c("Unknown", "Total")) |>
# Remove 'Redacted', 'Unknown' and 'Total' rows from `year`
# (This partially overlaps with the 'Unknown' and 'Total' in `month`
filter(year %nin% c("Redacted", "Unknown", "Total")) |>
# Remove any lines that are all NAs
filter(!if_all(everything(), (x) is.na(x))) |>
# Fill in the year values downwards
fill(year) |>
# Lengthen
pivot_longer(cols = `1`:`31`, names_to = "day",
values_to = "n")
fars
#> # A tibble: 5,921 × 4
#> year month day n
#>
|
Vom realiza un grafic al modelelor medii pe lună și zi pe toți anii disponibili. Deci, mai întâi, cumulăm datele pe lună și zi și luăm media pe ani.
r
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
fars_daily_means <- fars |>
summarize(mean_n = mean(n, na.rm = TRUE),
.by = c(month, day))
fars_daily_means
#> # A tibble: 372 × 3
#> month day mean_n
#>
|
În scopul a ceea ce vom desena, va avea mai mult sens să tratăm anii și lunile ca variabile categorice, adică ca factori, mai degrabă decât date adevărate.
r
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
dates <- unique(paste(fars$month, fars$day))
dates(1:10)
#> (1) "January 1" "January 2" "January 3" "January 4" "January 5" "January 6" "January 7" "January 8" "January 9" "January 10"
fars_daily_means <- fars_daily_means |>
mutate(
# Ordered categorical var of months
month_fac = factor(month,
levels = unique(fars$month),
ordered = TRUE),
# Convert from character to integer
day = as.integer(day),
# Ordered factor of month-days
day_fac = factor(paste(month, day),
levels = dates,
ordered = TRUE),
# Dummy variable: is it Halloween today?
flag = ifelse(month == "October" & day == 31, TRUE, FALSE),
# Shortcut .by again
.by = c(month, day)) |>
# Order for convenience
arrange(day_fac)
fars_daily_means
#> # A tibble: 372 × 6
#> month day mean_n month_fac day_fac flag
#>
|
Acum putem desena o diagramă. Acesta este generat din codul de aici, dar există și o setare a temei, care nu este afișată, care face fonturile puțin mai frumoase.
r
1 2 3 4 5 6 7 8 9 10 11 12 |
fars_daily_means |>
ggplot( mapping = aes(x = day, y = mean_n, fill = flag)) +
geom_col() +
scale_fill_manual(values = c("gray30", "darkorange2")) +
scale_x_continuous(breaks = c(1, 10, 20, 30)) +
guides(fill = "none") +
facet_wrap(~ month_fac, ncol = 1) +
labs(x = "Day of the Month",
y = "Mean Number of Child Pedestrians Killed",
title = "Pedestrians aged <16 years killednin Fatal Motor Vehicle Crashes",
subtitle = "Daily Average, 2008-22",
caption = "Kieran Healy @kjhealy / Source: NHTSA Fatality Analysis Reporting System")
|

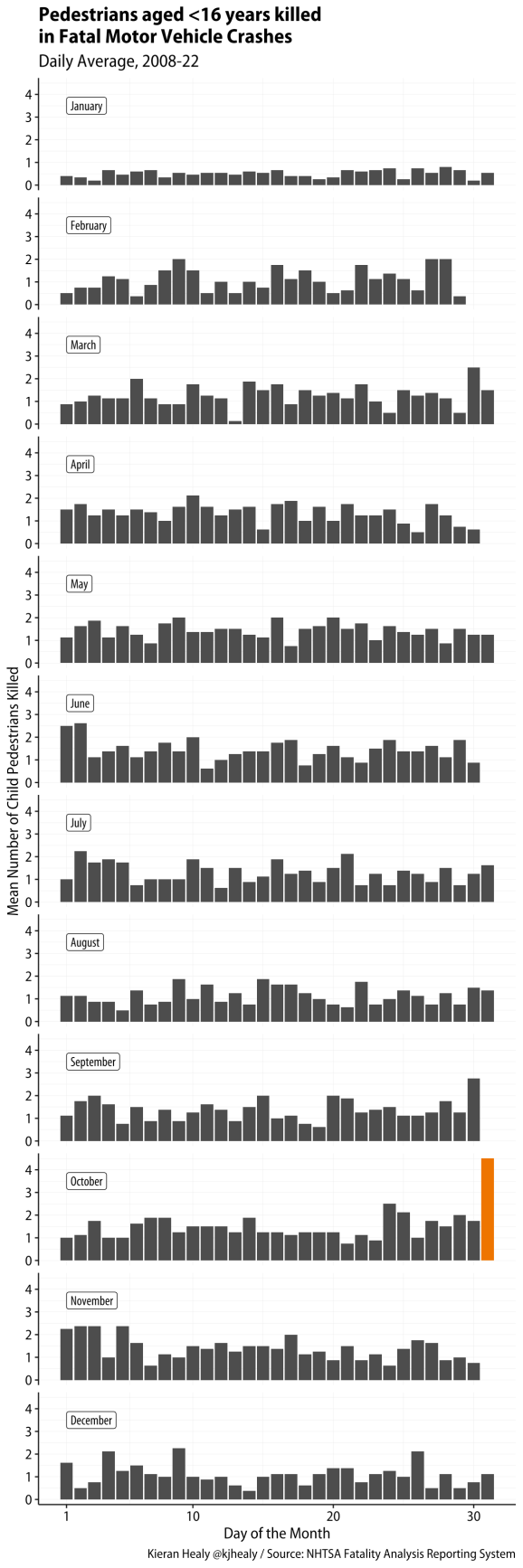
Graficul nostru.
Puteți vedea destul de clar creșterea numărului de decese ale copiilor pietonilor de Halloween în date. Există și o altă structură aici, de exemplu diferențe sezoniere puternice și, de asemenea, creșteri în alte sărbători din SUA. Unele modele din datele inițiale sunt ascunse atunci când facem o medie în funcție de dată-zi și nu de ziua săptămânii, cum ar fi diferența dintre weekend și alte zile. Poate cel mai important, aici există și o problemă interesantă de expunere la risc. Pe de o parte, vedem mai multe decese de copii la Halloween. Dar, pe de altă parte, putem fi destul de încrezători că expunerea este, de asemenea, mult mai mare: sunt mult mai mulți copii care se plimbă pe stradă la Halloween decât ar fi în mod normal. Deci, se poate ca rata în raport cu acel numitor să fie aceeași sau mai mică decât zilele „tipice”. Dar nu este cu adevărat posibil să avem acel numitor în astfel de date. În orice caz, dacă ieși cu copiii tăi și te plimbi în acest Halloween, fii în siguranță. Și mai pertinent, dacă ești la volan, fii atent.