(Acest articol a fost publicat pentru prima dată pe modToolsși cu amabilitate a contribuit la R-bloggeri). (Puteți raporta problema legată de conținutul acestei pagini aici)
Doriți să vă distribuiți conținutul pe R-bloggeri? dați clic aici dacă aveți un blog, sau aici dacă nu aveți.
În modelarea distribuției speciilor și modelarea nișelor ecologice (SDM & ENM), regiunea de unde sunt alese punctele de fundal sau pseudoabsență este cheia pentru cât de bine iese un model. Această regiune ar trebui să includă suficiente localități pentru ca modelul să evalueze (non-)preferențele speciei, dar ar trebui să fie și la îndemâna speciei ȘI să fie evaluată în mod rezonabil uniform pentru aceasta. Prejudecățile sondajului în fundal sau în regiunea pseudoabsenței pot reduce serios calitatea modelului.
Cu toate acestea, datele de apariție din viața reală (în special la scara largă a distribuțiilor speciilor) sunt adesea puternic părtinitoare și rareori este simplu să definiți o regiune adecvată în jurul punctelor existente. Există criterii foarte bune care funcționează bine în teorie, dar nu în majoritatea scenariilor actuale de părtinire a datelor despre biodiversitate. Până de curând, abordarea mea preferată a fost un tampon în jurul aparițiilor cunoscute, a căror rază era, de exemplu, distanța medie pe perechi dintre ele (ca măsură aproximativă a răspândirii lor spațiale sau a extinderii spațiale a speciei), sau jumătate din lățimea zonei. definite de apariții (de obicei, mai bine pentru distribuții alungite sau sondaje):
# download some example occurrence records:
occs <- geodata::sp_occurrence("Rupicapra", "pyrenaica", args = c("year=2024"))
# map occurrence records:
occs <- terra::vect(occs, geom = c("lon", "lat"), crs = "EPSG:4326")
terra::plot(occs, cex = 0.2, ext = terra::ext(occs) + 4)
cntry <- geodata::world(path = tempdir())
terra::plot(cntry, lwd = 0.2, add = TRUE)
# note you should normally clean these records from errors before moving on!
# compute mean distance and width of occurrence records:
occs_mdist <- mean(terra::distance(occs))
occs_width <- terra::width(terra::aggregate(occs))
# compute buffers around occurrences using both metrics:
occs_buff_d <- terra::aggregate(terra::buffer(occs, width = occs_mdist))
occs_buff_w <- terra::aggregate(terra::buffer(occs, width = occs_width / 2))
# plot both buffers and occurrence records:
par(mfrow = c(1, 2))
terra::plot(occs_buff_d, col = "yellow", border = "orange", lwd = 3, ext = terra::ext(occs) + 4, main = "Mean distance")
terra::plot(cntry, lwd = 0.2, add = TRUE)
terra::plot(occs, cex = 0.2, add = TRUE)
terra::plot(occs_buff_w, col = "yellow", border = "orange", lwd = 3, ext = terra::ext(occs) + 4, main = "Half width")
terra::plot(cntry, lwd = 0.2, add = TRUE)
terra::plot(occs, cex = 0.2, add = TRUE)
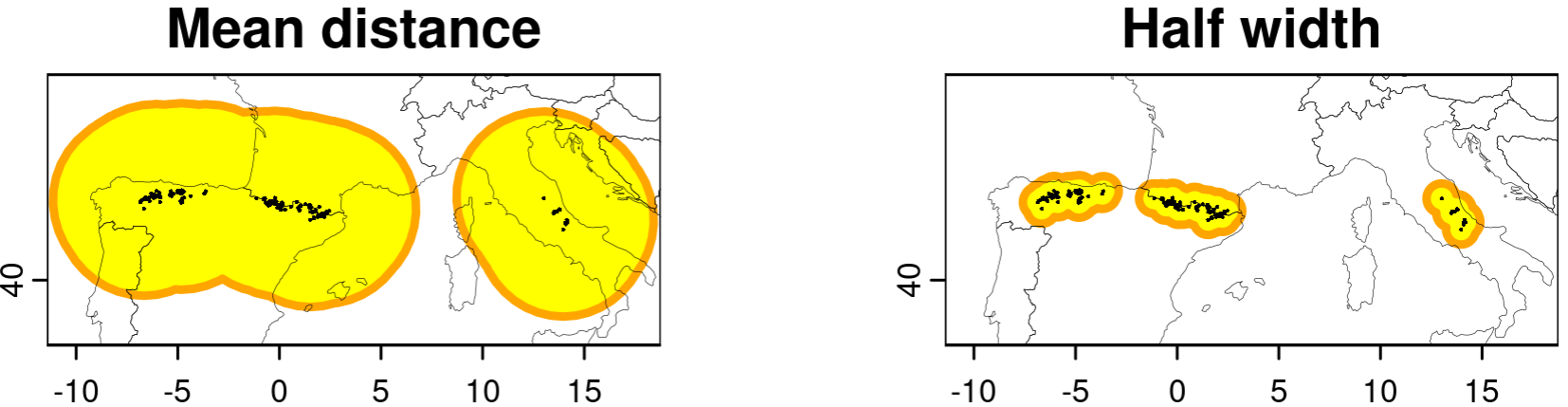
Acest lucru poate funcționa bine pentru speciile sau regiunile studiate relativ uniform, unde putem presupune în mod rezonabil că cea mai mare parte a zonei tamponate a fost (aproximativ uniform) cercetată și că majoritatea locurilor fără prezență sunt probabil absențe. Cu toate acestea, multe specii au înregistrări izolate în zone îndepărtate puțin studiate, efortul de cercetare fiind extrem de dezechilibrat în aria de distribuție. Deci, un tampon cu o rază uniformă nu va funcționa bine:
occs <- geodata::sp_occurrence("Lutra", "lutra", args = c("year=2024"))
# everything else same code as above...
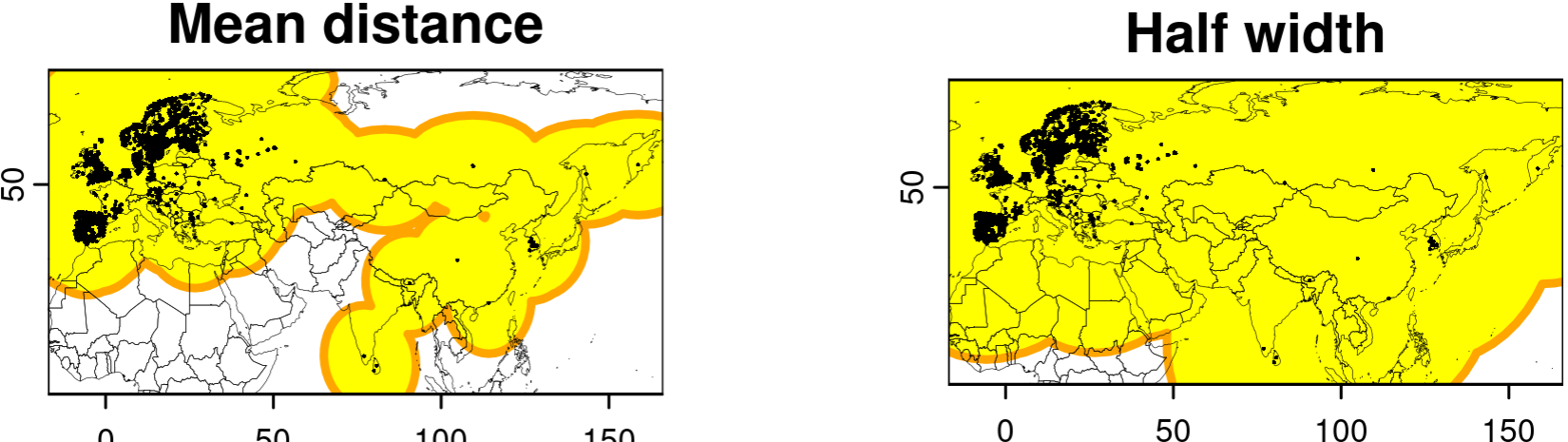
Puteți utiliza multiplicatori mai mici pentru distanță și lățime, dar aceste zone tampon cu rază uniformă vor include întotdeauna regiuni mari cu doar înregistrări de apariție rare și izolate, unde nu se poate presupune că absența înregistrărilor reflectă în mare parte absența speciei. În mod normal, aș face-o terra::erase() din tampon regiunile care par insuficient cercetate, dar care implică eliminarea datelor de apariție potențial valoroase.
Deci, cea mai recentă abordare a mea constă în găsirea unor grupuri de puncte de apariție care sunt într-o anumită distanță unul de celălalt; și apoi definirea unei raze variabile a tamponului, de exemplu, lățimea sau distanța medie pe perechi între puncte în fiecare clusterponderat în jos de distanța față de alte puncte sau clustere (ca indicator al observațiilor izolate în zonele sub-supravegheate). În acest fel, fundalul de modelare va evita zonele care cel mai probabil nu au fost sondate, dar fără a elimina înregistrările de apariție din acele zone. Am implementat mai multe variante ale acestei abordări și ale abordărilor conexe în noua getRegion() funcția pachetului R fuzzySim (versiunea 4.26):
# try regions with two different methods: reg1 <- fuzzySim::getRegion(occs, type = "inv_dist") terra::plot(cntry, lwd = 0.2, add = TRUE) terra::plot(reg1, lwd = 4, border = "orange", add = TRUE) reg2 <- fuzzySim::getRegion(occs, type = "clust_width", width_mult = 0.5) terra::plot(cntry, lwd = 0.2, add = TRUE) terra::plot(reg2, lwd = 4, border = "orange", add = TRUE)
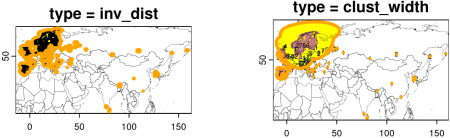
Citiți fișierul de ajutor al funcției pentru toate opțiunile diferite disponibile și încercați-le pentru a vedea ce vi se pare cel mai bine pentru sistemul dvs. de studiu. Feedback și rapoarte de erori sunt binevenite!