Doriți să vă distribuiți conținutul pe R-bloggeri? dați clic aici dacă aveți un blog, sau aici dacă nu aveți.
Christian și cu mine am făcut niște magie de cod: parcele extrem de eficiente care ajută la construirea și inspectarea oricărui model:
- Piton: https://github.com/lorentzenchr/model-diagnostics
pip install model-diagnostics - R: https://github.com/mayer79/effectplots
install.packages("effectplots")
Funcționalitatea este cel mai bine descrisă de rezultatul său:
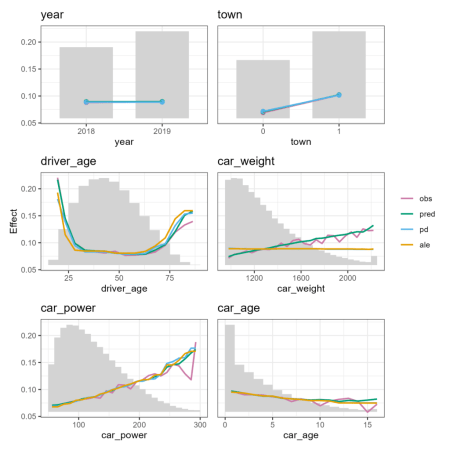
Graficele arată diferite tipuri de efecte caracteristice relevante în modelare:
- Media observată: Efect descriptiv (interesant și fără model).
- Medie estimată: efect combinat al tuturor caracteristicilor. Numit și „M Plot” (Apley 2020).
- Dependență parțială: efectul unei caracteristici, menținând constante alte valori ale caracteristicilor (Friedman 2001).
- Numărul de observații sau suma ponderilor cazurilor: Distribuția valorii caracteristicilor.
- Numai R: efecte locale acumulate, o alternativă la dependența parțială (Apley 2020).
Ambele implementari…
- sunt extrem de eficiente datorită {Polars} în Python și {colaps} în R și lucrează la seturi de date cu milioane de observații,
- sprijin greutăți ale carcasei cu toate statisticile lor, ideale în aplicații de asigurare,
- calculați reziduurile medii (nu sunt afișate în diagramele de mai sus),
- furnizați abateri standard/erori ale mediei observate și părtinire,
- permite trecerea la Complot pentru parcele interactive și
- sunt foarte personalizabil (pachetul R, de exemplu, permite restrângerea nivelurilor rare după calcularea statisticilor prin intermediul programului
update()metoda sau de a sorta caracteristicile în funcție de importanța efectului principal).
În spiritul seriei noastre „Lost In Translation”, oferim atât cod Python, cât și cod R de înaltă calitate. Vom folosi aceleași date și modele ca în una dintre cele mai recente postări ale noastre despre cum să construim GLM-uri puternice prin ML + XAI.
Exemplu
Să construim un model Poisson LightGBM pentru a explica frecvența revendicărilor, având în vedere șase caracteristici tradiționale dintr-un set de date de prețuri pentru cererile de răspundere civilă auto. 80% din rândurile de 1 Mio sunt folosite pentru antrenament, celelalte 20% pentru evaluare. Hiper-parametrii au fost ușor ajustați (nu sunt afișați).
library(OpenML) library(lightgbm) dim(df <- getOMLDataSet(data.id = 45106L)$data) # 1000000 7 head(df) # year town driver_age car_weight car_power car_age claim_nb # 0 2018 1 51 1760 173 3 0 # 1 2019 1 41 1760 248 2 0 # 2 2018 1 25 1240 111 2 0 # 3 2019 0 40 1010 83 9 0 # 4 2018 0 43 2180 169 5 0 # 5 2018 1 45 1170 149 1 1 yvar <- "claim_nb" xvars <- setdiff(colnames(df), yvar) ix <- 1:800000 train <- df(ix, ) test <- df(-ix, ) X_train <- data.matrix(train(xvars)) X_test <- data.matrix(test(xvars)) # Training, using slightly optimized parameters found via cross-validation params <- list( learning_rate = 0.05, objective = "poisson", num_leaves = 7, min_data_in_leaf = 50, min_sum_hessian_in_leaf = 0.001, colsample_bynode = 0.8, bagging_fraction = 0.8, lambda_l1 = 3, lambda_l2 = 5, num_threads = 7 ) set.seed(1) fit <- lgb.train( params = params, data = lgb.Dataset(X_train, label = train$claim_nb), nrounds = 300 )
import matplotlib.pyplot as plt
from lightgbm import LGBMRegressor
from sklearn.datasets import fetch_openml
df = fetch_openml(data_id=45106, parser="pandas").frame
df.head()
# year town driver_age car_weight car_power car_age claim_nb
# 0 2018 1 51 1760 173 3 0
# 1 2019 1 41 1760 248 2 0
# 2 2018 1 25 1240 111 2 0
# 3 2019 0 40 1010 83 9 0
# 4 2018 0 43 2180 169 5 0
# 5 2018 1 45 1170 149 1 1
# Train model on 80% of the data
y = df.pop("claim_nb")
n_train = 800_000
X_train, y_train = df.iloc(:n_train), y.iloc(:n_train)
X_test, y_test = df.iloc(n_train:), y.iloc(n_train:)
params = {
"learning_rate": 0.05,
"objective": "poisson",
"num_leaves": 7,
"min_child_samples": 50,
"min_child_weight": 0.001,
"colsample_bynode": 0.8,
"subsample": 0.8,
"reg_alpha": 3,
"reg_lambda": 5,
"verbose": -1,
}
model = LGBMRegressor(n_estimators=300, **params, random_state=1)
model.fit(X_train, y_train)
Să inspectăm (efectele principale) modelului asupra datelor de testare.
library(effectplots) # 0.3 s feature_effects(fit, v = xvars, data = X_test, y = test$claim_nb) |> plot(share_y = "all")
from model_diagnostics.calibration import plot_marginal
fig, axes = plt.subplots(3, 2, figsize=(8, 8), sharey=True, layout="tight")
# 2.3 s
for i, (feat, ax) in enumerate(zip(X_test.columns, axes.flatten())):
plot_marginal(
y_obs=y_test,
y_pred=model.predict(X_test),
X=X_test,
feature_name=feat,
predict_function=model.predict,
ax=ax,
)
ax.set_title(feat)
if i != 1:
ax.legend().remove()
Rezultatul poate fi văzut la începutul acestei postări pe blog.
Iată câteva informații despre model:
- Predicțiile medii se potrivesc îndeaproape cu frecvențele observate. Nu este vizibilă nicio părtinire clară.
- Dependența parțială arată că anul și greutatea mașinii aproape că nu au niciun impact (în ceea ce privește principalele lor efecte), în timp ce
driver_ageşicar_powerefectele par cele mai puternice. Axele y comune ajută la evaluarea acestora. - În afară de
car_weightcurba dependenței parțiale urmează îndeaproape predicțiile medii. Aceasta înseamnă că efectul modelului pare să provină cu adevărat de la caracteristica de pe axa x și nu de la o altă caracteristică corelată (cum ar fi, de exemplu, cucar_weightcare este de fapt puternic corelat cucar_power).
Cuvinte finale
- Inspectarea modelelor a devenit mult mai relaxată cu funcțiile de mai sus.
- Pachetele folosite oferă mult mai multe funcționalități. Încercați-le! Sau le vom arăta în postările ulterioare ;).
Referințe
- Apley, Daniel W. și Jingyu Zhu. 2020. Vizualizarea efectelor variabilelor predictoare în modelele de învățare supravegheată cutie neagră. Journal of the Royal Statistical Society Series B: Statistical Methodology, 82 (4): 1059–1086. doi:10.1111/rssb.12377.
- Friedman, Jerome H. 2001. Greedy Function Aproximation: A Gradient Boosting Machine. Analele statisticii 29 (5): 1189–1232. doi:10.1214/aos/1013203451.
Script R, blocnotes Python
Noobz.ro.com oferă actualizări zilnice prin e-mail despre R știri și tutoriale despre învățarea R și multe alte subiecte. Faceți clic aici dacă doriți să publicați sau să găsiți un job R/data-science.
Doriți să vă distribuiți conținutul pe R-bloggeri? dați clic aici dacă aveți un blog, sau aici dacă nu aveți.
Continuați să citiți: Grafice de efect în Python și R