(Acest articol a fost publicat pentru prima dată pe R pe kieranhealy.orgși cu amabilitate a contribuit la R-bloggeri). (Puteți raporta problema legată de conținutul acestei pagini aici)
Doriți să vă distribuiți conținutul pe R-bloggeri? dați clic aici dacă aveți un blog, sau aici dacă nu aveți.
Diagramele circulare sunt proaste, ca orice știre completă. Nu suntem la fel de buni la judecarea diferențelor relative dintre unghiuri și arii precum judecăm diferențele relative de lungimi pe o linie de bază comună. Acest lucru este valabil mai ales atunci când avem mai mult de două lucruri de comparat în același timp. Deci, de regulă, nu ar trebui să le folosiți. Ar trebui să găsiți o altă modalitate de a vă vizualiza datele. Pe de altă parte, tocmai am făcut 424 de diagrame animate, pentru că dacă ai de gând să încalci o regulă, ar trebui să o încalci bine și greu.
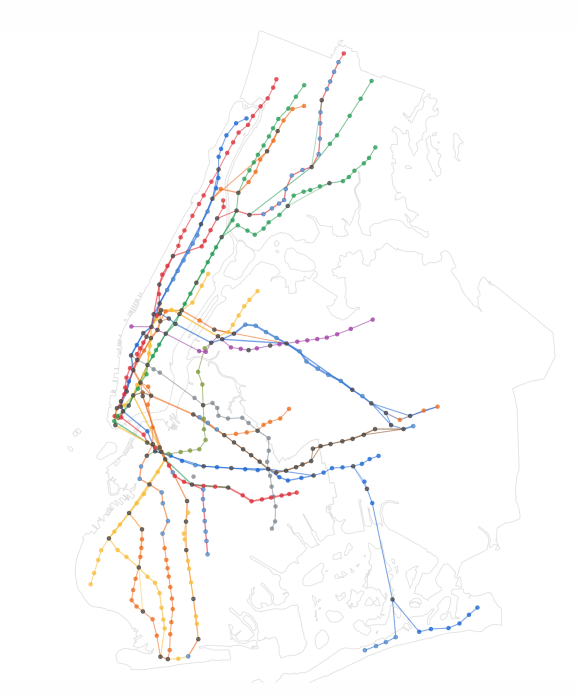
O vedere a sistemului de metrou din New York (excluzând SIR). Vom anima asta în doar un minut.
Sistemul de metrou din New York este foarte mare și transportă un lot de pasageri în fiecare zi. MTA pune la dispoziție destul de multe date despre metrou, inclusiv date despre fluxul orar prin sistem. Acum, MTA nu poate urmări căile individuale pe care le parcurg oamenii prin metrou. Dacă utilizați un card OMNY (sau, înainte de aceasta, un Metrocard) pentru a intra în sistem, acest lucru semnalează începutul unei călătorii de la o anumită stație sau complex de stații. Dar, spre deosebire de unele sisteme, nu trebuie să „ieși” din metrou, ci doar ieși printr-un turnichet. Deci sistemul nu știe de unde ieși din el. În plus, în timp ce multe stații sunt doar pe o singură linie, unele (cum ar fi 34 St/Penn Station sau Fulton Street) sunt complexe de stații care deservesc multe linii și permit transferuri între ele.
Cu toate acestea, MTA publică estimări orar Origine-Destinație pentru toate perechile de stații. Acestea sunt cea mai bună presupunere a lor despre fluxul de trafic de la orice stație anume la oricare alta. Deoarece există atât de multe combinații, vizualizarea acestui tip de date este destul de dificilă. Chiar și atunci, nu obțineți informații despre trasee prin sistem, doar punctele de început și de sfârșit. Analiștii și planificatorii de transport public pot merge mai departe introducând câteva ipoteze suplimentare despre utilizatorii de metrou. De exemplu, am putea presupune că navetiștii iau cea mai eficientă rută între orice pereche dată de stații de intrare și ieșire și construiesc de acolo o imagine a fluxului prin sistem.
Eu fac ceva mai simplu aici. Folosesc estimările orare origine-destinație ale MTA și le agreg stație cu stație pentru a calcula fluxurile de intrare și ieșire în 424 de stații de metrou sau complexe de stații. Aceste cifre specifice sunt calculate în medie pentru toate zilele de luni din 2025. Pentru fiecare oră din stație calculăm volumul total de pasageri și ponderea acelui volum care sunt sosiri și plecări estimate. Apoi desenăm o diagramă circulară pentru fiecare stație, colorându-l cu galben pentru plecări, violet pentru sosiri. Mărimea cercului reflectă volumul total, iar proporțiile feliilor de plăcintă arată echilibrul debitului.
Datele de flux sunt destul de voluminoase. Setul de date original are aproximativ 121 de milioane de rânduri. Dar lucrul cu acesta este destul de simplu, datorită magiei fișierelor de parchet, duckdb și duckplyr. După ce am descărcat cu răbdare datele prin API-ul său, le-am pus într-un fișier de parchet. CSV-ul are aproximativ 17 GB, dar fișierul de parchet îl reduce la 1,5 GB. Apoi am făcut un mic pachet R care a inclus acele date cu câteva funcții comode. Acest lucru îmi permite să folosesc datele fără a le copia într-un singur proiect. Deci pot scrie, de exemplu,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
nycsubwayodr::nyc_subway_odr() #> # A duckplyr data frame: 15 variables #> year month day_of_week hour_of_day timestamp day_of_month origin_station_complex_id #> |
De acolo, interogăm leneș datele și duckdb face treaba de a face calculele. Întregul tabel nu este niciodată încărcat în sesiunea dvs. R, iar duckdb este foarte rapid. De acolo, luăm rezumatele noastre de flux orare, le unim la un tible de date de stație și linie și exportăm rezultatul în unele fișiere JSON pe care D3js le animează pentru noi.
Iată rezultatul. Sunt trei vederi. Inițial, vedeți doar harta schematică a metroului. Dacă faceți clic pe butonul „Hartă” din stânga sus, se va comuta la vizualizarea grafică cu bifare, care pune o plăcintă pe fiecare complex de stații, fiecare bifă fiind o oră din zi. Plăcintele se adună una peste alta în vizualizarea geografică (într-un mod nu complet neinformativ), dar faceți clic din nou pentru a le face să se extindă la o imagine de rețea oarecum mai abstractă, direcționată de forță a sistemului. Apoi faceți clic din nou pentru a reveni la hartă. Puteți trece cu mouse-ul peste sau să atingeți noduri pentru a obține informații despre bitul de date pe care îl afișează în prezent.
Acum, ați putea spune în mod rezonabil, Kieran, acestea sunt o mulțime de date care arată că oamenii merg la muncă dimineața și vin acasă seara. Nu spun că nu există nimic în această critică. Dar există câteva detalii interesante acolo, deoarece datele captează trafic în diferite părți ale orașului. Marile schimburi domină în mod natural priveliștea, dar chiar și aici există lucruri de interes în ceea ce privește echilibrul fluxului, de exemplu, Penn Station are oameni care vin pe New Jersey Transit în timpul orelor de vârf ale dimineții și apoi intră în metrou, ceea ce face mult pentru a-și echilibra fluxul net în timpul orelor de vârf și chiar îl înclină spre plecări nete. Dar, mai important, cine nu vrea să stea pe spate și să contemple mai mult de 400 de diagrame, fiecare pulsand de viață pe măsură ce trece încă o oră?