Rezumat: În această postare pentru invitați, Brian A Mikelbank, profesor asociat de studii urbane la Cleveland State University, împărtășește modul în care a folosit R pentru a explora cauzele probabile ale suspendării licenței în Ohio, SUA.
Pachete necesare:
Date:
Fundal
Sunt geograf urban cantitativ, la facultatea de la Cleveland State University, unde mă concentrez pe ‘proces spațial urban‘, care încearcă să înțeleagă modul în care spațiul influențează procesele care produc, întrețin și modifică împrejurimile noastre urbane, cum ar fi locuințe, migrație, economie etc.) . De asemenea, sunt interesat de instrumentele de analiză care ne ajută să identificăm și să înțelegem tiparele spațiale, deoarece înțelegerea acestor tipare ne poate ajuta să înțelegem ce le-a cauzat.
Înainte de a învăța R, lucrasem pe mai multe platforme software pentru a-mi face analizele – în principal Excel, SPSS, GeoDa și ArcGIS. Nu am fost limitat în întrebările de cercetare pe care le puteam pune, dar a fost ineficient să mutam seturi de date înainte și înapoi de la un program la altul. În plus, a fost o povară să țin evidența deciziilor de date pe care le-am luat pe parcursul mai multor platforme, iar replicarea muncii a fost ineficientă și consumatoare de timp.
Căutam o modalitate de a aduna toate sarcinile mele de cercetare sub o singură umbrelă software. Auzisem de R, așa că atunci când universitatea a găzduit sâmbătă dimineața un atelier „Introducere în R pentru vizualizarea datelor”, m-am asigurat că particip. Utilitatea lui R a fost imediat clară: nu numai că ar oferi o oportunitate de a muta întreaga mea conductă de analiză într-o singură bucată de software, dar era clar că limbajul va deschide o gamă aproape nelimitată de oportunități de analiză, înțelegere și vizualizarea datelor.
La scurt timp după aceea, am decis să mă înscriu la un curs de introducere în R pentru analiza politicilor, care a fost anunțat pe Noobz.ro.com.
Suspendari de licență legate de datorii în Ohio, SUA
În 2020, m-am alăturat unui grup de avocați de la Societatea de Asistență Legală din Cleveland care cercetau subiectul suspendării permisului de conducere legat de datorii.
Interesul lor pentru suspendarea permisului a izvorât din faptul că suspendările legate de datorii pot prinde șoferii cu resurse limitate într-un cerc vicios: amenzile și taxele pentru încălcări aparent minore din trafic pot ajunge cu ușurință în datorii de mii de dolari. Șoferii, fiind incapabili să ramburseze aceste datorii, atunci nu pot conduce. Făcându-le și mai dificil să câștige banii necesari pentru achitarea datoriilor.
Dar, care credeți că este principala cauză a suspendării permisului de conducere?
Pun pariu că ai răspuns la ceva precum conducerea periculoasă, excesul de viteză, conducerea în stare de ebrietate sau ceva asemănător. Pentru statul Ohio, ai greși. Majoritatea suspendărilor din Ohio se datorează faptului că șoferul nu poate plăti o amendă sau o taxă. Creanţă. Nu poate avea absolut nimic de-a face cu conducerea periculoasă!
Dacă sunteți interesat de subiect, vă recomand să aruncați o privire pe cartea noastră albă.
Date
Am elaborat o solicitare de înregistrări publice către Biroul Vehiculelor cu Motor din Ohio și, în schimb, am primit aproximativ 40 de fișiere Excel, fiecare cu 5-10 foi de lucru separate (nu îmi pot imagina organizarea, agregarea și analiza acestor date fără R!).
Am avut date din 2016 până în 2020 pentru codurile poștale din Ohio, care includeau informații despre 8 tipuri diferite de suspendări legate de datorii (capturate în variabila „tip”). Pentru fiecare tip, am avut și date despre suma percepută, plătită și suma datorată la sfârșitul anului (capturată în variabila „indicator”).
Ne concentrăm pe 2019, deoarece acesta a fost cel mai recent an „tipic” în care datele erau disponibile atunci când am efectuat cercetarea.
Mai întâi, să citim datele și să examinăm structura datelor (conținute în drs_2019.RDS) și să producem statistici rezumative pentru setul de date:
library(tidyverse)
drs_2019 <- readRDS("drs.RDS")
acs <- readRDS("acs.RDS")
str(drs_2019)
Se pare că setul de date conține cinci variabile cu puțin peste 300.000 de observații.
## tibble (300,516 x 5) (S3: tbl_df/tbl/data.frame) ## $ zip : num (1:300516) 43001 43002 43003 43004 43005 ... ## $ year : num (1:300516) 2016 2016 2016 2016 2016 ... ## $ type : Factor w/ 8 levels "child support",..: 3 3 3 3 3 3 3 3 3 3 ... ## $ indicator: Factor w/ 5 levels "charged","owed",..: 5 5 5 5 5 5 5 5 5 5 ... ## $ value : num (1:300516) 7 2 23 202 1 4 59 4 1 34 ...
Statisticile rezumate ne oferă, de asemenea, o idee bună a informațiilor conținute în setul de date. În special, rețineți că variabila „indicator” face posibilă înțelegerea numărului de suspendări, șoferi suspendați și a sumei percepute, datorate și plătite în timp (folosind variabila an).
summary(drs)
Min. : 4410 Min. :2019 non-compliance :10628 charged : 7104
1st Qu.:43735 1st Qu.:2019 warrant block : 9365 owed : 9020
Median :44440 Median :2019 license forfeiture: 9132 paid : 5745
Mean :44464 Mean :2019 child support : 7596 suspended drivers:19432
3rd Qu.:45241 3rd Qu.:2019 random selection : 7433 suspensions :19432
Max. :45969 Max. :2019 judgement : 6542
NA's :25 (Other) :10037
value
Min. : 0
1st Qu.: 7
Median : 56
Mean : 19020
3rd Qu.: 700
Max. :6484764
Înțelegerea suspensiilor după tip
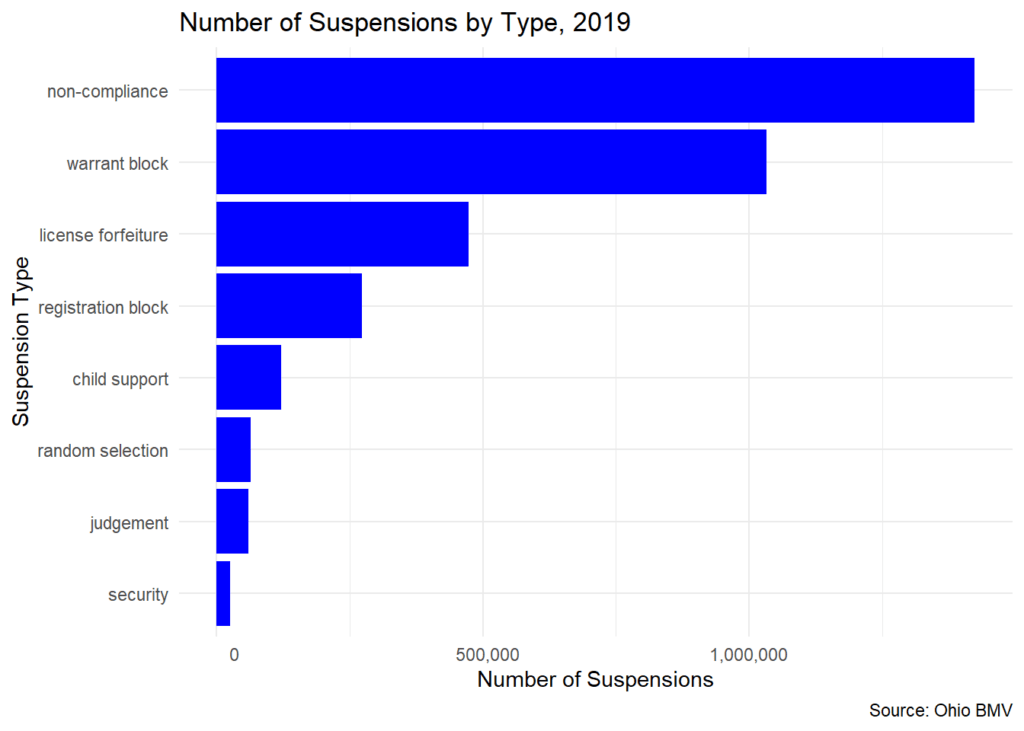
Privind graficul de mai jos, puteți vedea cele opt tipuri de suspendări ale permisului de conducere legate de datorii. Observați că suspendările de „neconformitate” sunt cele mai frecvente, care apare atunci când un șofer nu prezintă dovada asigurării auto.
# make the plot
ggplot(data=drs_type, aes(x=total, y = reorder(type, total)))+
geom_col(fill = "blue")+
labs(
title = "Number of Suspensions by Type, 2019",
caption = "Source: Ohio BMV",
y = "Suspension Type",
x = "Number of Suspensions"
)+
scale_x_continuous(labels = function(x) format(x, big.mark = ",",
scientific = FALSE))+
theme_minimal()
Acum puteți vedea cele 8 tipuri de suspendări ale permisului de conducere legate de datorii și că suspendările de neconformitate sunt cele mai frecvente. O suspendare de neconformitate are loc atunci când un șofer nu prezintă dovada asigurării auto.
Analiza financiară a suspendărilor
În continuare, să explorăm aspectele financiare ale acestor suspendări. Suspendarile implică de obicei penalități financiare în plus față de datoria neplătită care se află în centrul suspendării în primul rând. Pentru un anumit an, cunoaștem noua sumă percepută, suma care a fost plătită în acel an și suma care era încă datorată la sfârșitul anului.
# Charged, paid, and owed by type
# these are the financial variables:
cpo <- c("charged", "paid", "owed")
cpo_type <- drs_2019 %>%
filter(indicator %in% cpo)%>%
mutate(indicator = factor(indicator, levels = c("paid", "charged", "owed"))) |>
group_by(type, indicator)%>%
summarize(total=sum(value))
# make the plot (in millions)
ggplot(data=cpo_type, aes(x=total/1000000, y = reorder(type, total), fill = indicator))+
geom_col(position = "dodge")+
labs(
title = "Amounts Owed, Charged, and Paid by Suspension Type, 2019",
caption = "Source: Ohio BMV",
fill = "Financial Variables",
y = "Suspension Type",
x = "Dollars, in Millions"
)+
theme_minimal()
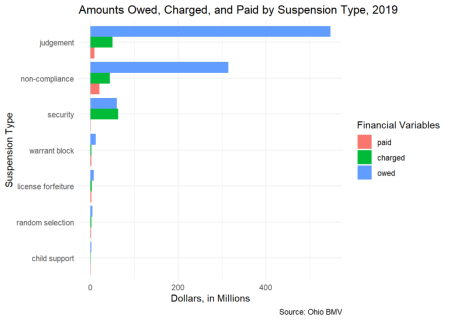
Trei tipuri de suspendare domină domeniul financiar. Suspendarile de judecată apar atunci când există o judecată împotriva unui șofer ca urmare a unui proces. Suspendarile de neconformitate au fost menționate mai sus, iar suspendările de securitate au loc
atunci când o cerere de daune materiale sau vătămări corporale mai mare de 400 USD este depusă la BMV din Ohio.
Diferențele dintre barele albastre, verzi și roz merită remarcate. Deoarece suma plătită într-un an obișnuit (roz) este mai mică decât suma percepută (verde), suma datorată (albastru) se acumulează în timp. Aceste sarcini financiare suplimentare sunt
dificil de depășit de către gospodării.
Suspensii legate de datorii, sărăcie și rasă
Eram curioși să știm cum distribuția DRS corespundea sărăciei și rasei. Deoarece aveam detalii la nivel de cod poștal din Ohio BMV, am adunat date demografice la nivel de cod poștal din Sondajul comunității americane al Biroului de recensământ din SUA (acs.rds).
Sărăcie
Care este relația dintre numărul de suspiciuni și rata sărăciei din codurile poștale din Ohio?
Am împărțit cele aproape 1200 de coduri poștale din Ohio în 10 grupuri egale (decile) în funcție de rata sărăciei lor. Acestea sunt afișate pe axa X. Înălțimea barelor roșii reprezintă numărul de DRS din fiecare grup de cod poștal.
# Get the suspensions by zip code
tmp_plt_data <- drs_2019 |>
filter(indicator == "suspensions") |>
group_by(zip) |>
summarize(
suspensions = sum(value)
)
# Get the ACS data and create quintiles
tmp_dta_acs_q <- acs |>
mutate(
p_pov_q = ntile(p_pov, 10),
p_poc_q = ntile(p_poc, 10)
)
# Join the two data sets together
plt_drs_pov_poc_dta <- left_join(tmp_plt_data, tmp_dta_acs_q, by = join_by("zip" =="zip")) |>
na.omit()
# Make the plot
plt_drs_pov_poc_dta |>
ggplot(aes(x=p_pov_q, y=suspensions)) +
geom_bar(stat="identity", fill="firebrick") +
scale_x_continuous(breaks = 1:10,
labels=c("Lowest PovertynZIPs"," "," "," "," "," "," ", " ", " ", "Highest PovertynZIPs"))+
scale_y_continuous(labels = scales::comma)+
labs(
x = "ZIP Codes Grouped by Poverty Rate",
y = "Number of Suspensions",
title = "Number of Suspensions by Poverty Rate, 2019",
caption = "Data sources: Ohio BMV, 2015-2019 ACS (B17001) and author calculations"
)+
theme_minimal()
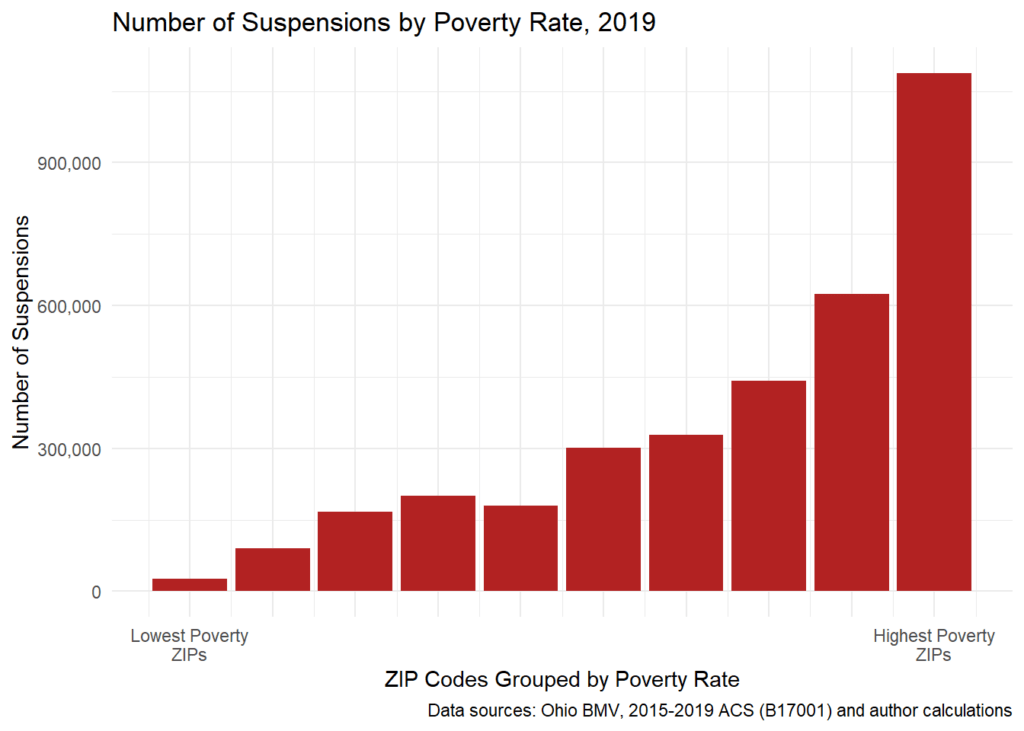
Modelul este destul de izbitor – aproape fără excepție, cu cât rata sărăciei este mai mare, cu atât mai multe suspendări legate de datorii. În codurile poștale cu cea mai mare sărăcie, peste un milion de DRS – în codurile poștale cu cea mai scăzută sărăcie, mai puțin de 27.000!
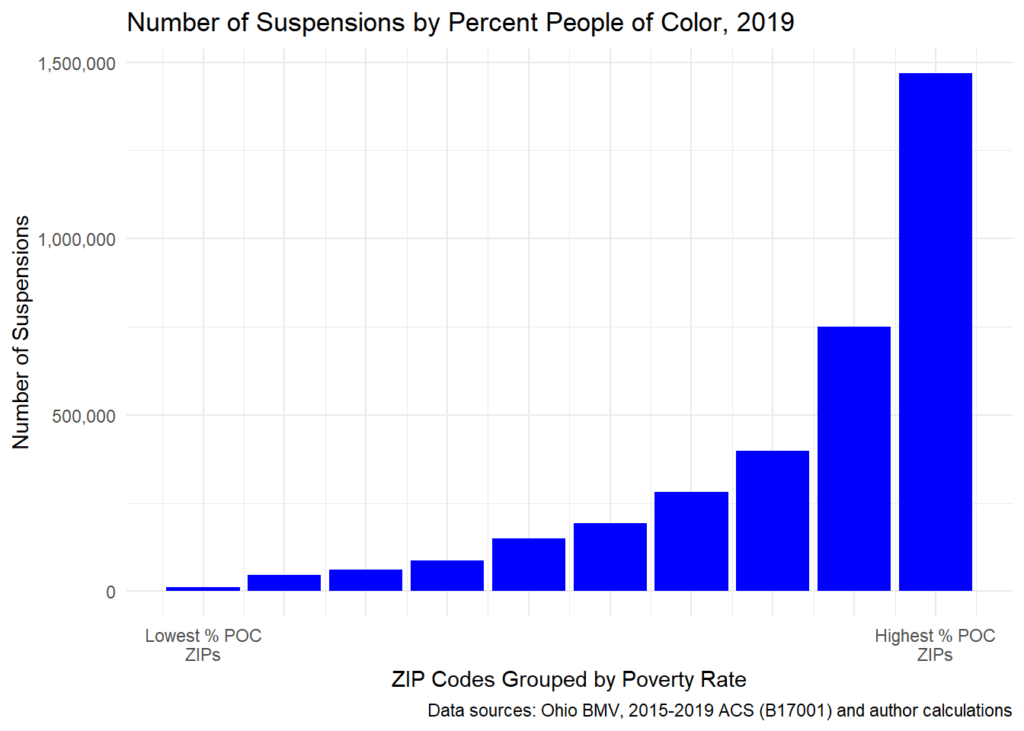
Rasă
Am replicat analiza de mai sus, dar de data aceasta pe baza procentului People of Color. Rezultatele sunt izbitor de similare: fără excepție, cu cât este mai divers codul poștal, cu atât este mai mare numărul de suspendări legate de datorii. În codurile poștale cu cel mai mare procent de persoane de culoare, au existat 1,46 milioane de suspendări. În cel mai mic procent din codurile poștale People of Color din stat, au existat mai puțin de 11.000 de suspendări.
plt_drs_pov_poc_dta |>
ggplot(aes(x=p_poc_q, y=suspensions)) +
geom_bar(stat="identity", fill="blue") +
scale_x_continuous(breaks = 1:10,
labels=c("Lowest % POCnZIPs"," "," "," "," "," "," ", " ", " ", "Highest % POCnZIPs"))+
scale_y_continuous(labels = scales::comma)+
labs(
x = "ZIP Codes Grouped by Poverty Rate",
y = "Number of Suspensions",
title = "Number of Suspensions by Percent People of Color, 2019",
caption = "Data sources: Ohio BMV, 2015-2019 ACS (B17001) and author calculations"
)+
theme_minimal()
Sărăcie şi Rasă
În cele din urmă, pentru a analiza suspendările legate de datorii, sărăcia și rasa în același timp, voi folosi un diagramă cu case grupate. Da, unele detalii ale datelor se pierd în formarea grupurilor (adică, reducerea indicatorilor noștri demografici la datele ordinale), dar (1) ne-am uitat și la corelațiile de rang parțial (nu sunt detaliate aici) și (2) am creat o mulțime de comunitate prezentări în care a fost o idee mai bună să ne împărtășim descoperirile în grafice în loc de tabele și valorile p.
În primul rând, creăm noi variabile chintile pentru variabilele rata sărăciei și procentul Oameni de culoare. Apoi, filtrăm pentru suspensii în datele noastre DRS și apoi unim aceste date împreună pentru a crea ceea ce avem nevoie pentru diagrama de casete.
# Create quintiles
acs_q <- acs |>
mutate(
p_pov_q = factor(ntile(p_pov, 5), labels = c("Low", "", "Medium", " ", "High")),
p_poc_q = factor(ntile(p_poc, 5), labels = c("Low", "", "Medium", " ", "High")),
)
# Filter for suspensions and aggregate by ZIP Code
tmp_plt_data <- drs_2019 |>
filter(indicator == "suspensions") |>
group_by(zip) |>
summarize(
suspensions = sum(value)
)
# Join the data together
plt_box_dta <- left_join(tmp_plt_data, acs_q, by = join_by("zip")) |>
na.omit()
# create the plot
ggplot(data = plt_box_dta, aes(x=factor(p_pov_q), y = suspensions, fill = factor(p_poc_q)))+
geom_boxplot()+
labs(
title = "Poverty and Race Boxplots, 2019",
x = "Poverty Rate",
y = "Number of Suspensions",
fill = "% People of Color"
)+
theme_minimal()
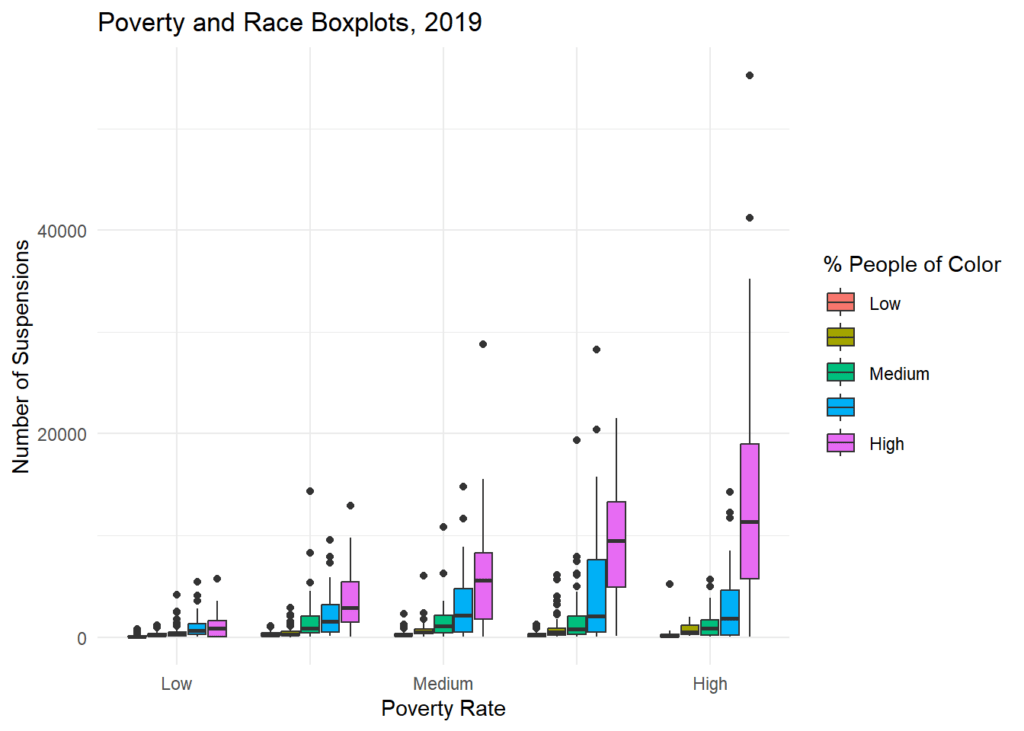
Există două modele de notă în boxplot:
- În primul rând, urmăriți un procent de casetă Oameni de culoare pe cele cinci niveluri de sărăcie. Acest lucru menține în esență rasa constantă în timp ce se analizează efectul sărăciei. Dacă sărăcia nu ar avea nicio influență asupra DRS, cele cinci casete purpurie înalte de oameni de culoare, de exemplu, ar arăta la fel în diferitele grupuri de sărăcie. Nu este cazul aici. Numărul de suspendări crește în mod constant între grupurile de sărăcie, de la scăzut la ridicat.
- În al doilea rând, concentrați-vă pe un singur panou privind rata sărăciei – sărăcia medie, de exemplu. Acest lucru menține, în esență, sărăcia constantă. Dacă rasa nu ar avea nicio influență asupra DRS, fiecare dintre cele cinci bare din cadrul panoului de sărăcie medie ar arăta la fel. Nici acesta nu este cazul — spensiile cresc în mod constant în categoriile Oameni de culoare de la scăzut la mare.
Deși, această postare este menită doar să ofere un instantaneu al analizei noastre (a se vedea cartea noastră albă pentru mai multe), datele au arătat destul de clar că a existat un număr mai mare de suspendări legate de datorii în codurile poștale unde a existat un procent mai mare de oameni. de culoare și/sau o rată a sărăciei mai mare. Să fie clar că politicile care urmăresc să abordeze numărul mare de suspendări legate de datorii ar trebui să ia în considerare cu atenție rasa și sărăcia.
Dacă sunteți interesat să aflați mai multe, puteți arunca o privire pe cartea albă: Drumul spre Nicăieri: Suspendari ale permisului de conducere legate de datorii în Ohiode la Legal Aid Society of Cleveland.
R Resurse
R s-a dovedit a fi un instrument de neprețuit în analiza acestor date privind suspendările legate de datorii – de la integrarea a zeci de fișiere și fișe de lucru din solicitarea noastră inițială de înregistrări publice, până la analiza distribuției în timp și spațiu a suspendărilor în sine, precum și a acestora. implicatii financiare.
În timp ce încă îmi continui călătoria R, pentru cei dintre voi care tocmai pornesc în călătoria voastră, iată câteva resurse pe care le-am descoperit că sunt în special de ajutor:
- Stack Overflow este un site extraordinar. Nu am pus niciodată o întrebare acolo, dar de mai multe ori atunci când întreb Google a
întrebare despre R, Stack Overflow se află în partea de sus a rezultatelor, iar întrebarea a fost deja adresată și răspunsul acolo. - Pentru o abordare mai sistematică a învățării R, a doua ediție a R for Data Science este o sursă excelentă.
- Primul atelier R de sâmbătă dimineață a fost predat de Rob Kabacoff. Tot ce scrie despre R este de ajutor. Consultați site-ul și cărțile lui Quick-R – R în Acțiune 3e și Vizualizarea datelor în R.
- În cele din urmă, seria de seminare „programare pentru politici” la care am participat a fost de fapt precursorul cursului online oferit la Policy Analysis Lab (formal program4policy.com), pe care l-am considerat a fi de mare ajutor. Când am urmat cursul, acesta a fost oferit online la 22:00 duminică seara – nu este momentul ideal pentru a învăța! Dar chiar și la acea oră târzie, cursul a fost foarte bun. Fiecare săptămână avea un scenariu de politică diferit, date asociate și un fișier de script R de pornire pe care ar trebui să îl modificăm și să îl adăugăm. Între sesiuni a existat ajutor disponibil (aveam nevoie de el!). Pe măsură ce săptămânile (și abilitățile noastre) au progresat, am fost responsabili pentru tot mai mult din propriul nostru cod R. Cursul a fost o bază excelentă pentru învățarea R.