(Acest articol a fost publicat pentru prima dată pe R – TOMAZTSQLși a contribuit cu drag la R-Bloggers). (Puteți raporta problema despre conținutul de pe această pagină aici)
Doriți să vă împărtășiți conținutul pe R-Bloggers? Faceți clic aici dacă aveți un blog sau aici dacă nu.
Acesta este numit, da, ați ghicit, după lanțurile Markov.  Babblerul este acolo pentru a conecta simplitatea funcției R inutile.
Babblerul este acolo pentru a conecta simplitatea funcției R inutile.
Este o simplă calcul a probabilității de a înlătura și de a desena de mai multe ori apărute cuvinte înlănțuite amintește de lanțul Markov (deși nu este asta!).
Gistul este tokenizarea cuvintelor, numărarea aparițiilor și calcularea probabilităților.
markov_babbler <- function(text, order = 2, n = 50, by_word = TRUE) {
tokens <- if (by_word) str_split(text, "\s+")((1)) else unlist(str_split(text, ""))
tokens <- tokens(tokens != "")
#add the removal of full stops,....
token <- c('I', 'I am', 'to', 'all', 'Oh')
df <- data.frame(
from = sapply(seq_len(length(tokens) - order), function(i) paste(tokens(i:(i + order - 1)), collapse = " ")),
to = tokens((order + 1):length(tokens)),
stringsAsFactors = FALSE
)
probs <- df %>%
group_by(from, to) %>%
summarise(freq = n(), .groups = "drop") %>%
group_by(from) %>%
mutate(prob = freq / sum(freq))
current <- sample(unique(probs$from), 1)
output <- unlist(str_split(current, " "))
for (i in seq_len(n)) {
next_word <- probs %>% filter(from == current)
if (nrow(next_word) == 0) break
next_token <- sample(next_word$to, 1, prob = next_word$prob)
output <- c(output, next_token)
current <- paste(tail(output, order), collapse = " ")
}
Având în vedere acest lucru, am luat Roșu Ridding Hood (fratele Grimm) și am conectat povestea în funcție. Atât în limbile engleze, cât și în cele slovene.
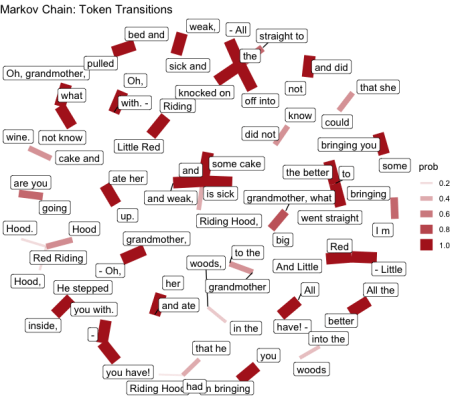
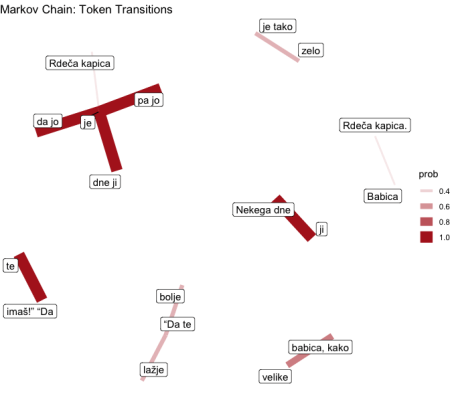
…
A juca cu statistici inutile este distractiv. Distracție inutilă ![]()
Și nicio funcție nu este completă cu puțin GGPLOT pentru desenarea rețelei de cuvinte.
g <- graph_from_data_frame(probs %>% filter(freq > 1), directed = TRUE)
plot <- ggraph(g, layout = "fr") +
geom_edge_link(aes(edge_alpha = prob, edge_width = prob), color = "firebrick") +
geom_node_label(aes(label = name), size = 4, repel = TRUE) +
theme_void() +
labs(title = "Markov Chain: Token Transitions")
Fericit R-codificare și rămâneți sănătos!