(Acest articol a fost publicat pentru prima dată pe DateAgeeekși a contribuit cu drag la R-Bloggers). (Puteți raporta problema despre conținutul de pe această pagină aici)
Doriți să vă împărtășiți conținutul pe R-Bloggers? Faceți clic aici dacă aveți un blog sau aici dacă nu.
China își propune să -și crească influența pe piața globală a lingourilor, direcționând țările prietenoase să -și păstreze rezervele de aur în granițele sale. Această mișcare face parte din eforturile Beijingului de a -și reduce dependența de dolar și de a promova utilizarea globală a yuanului.
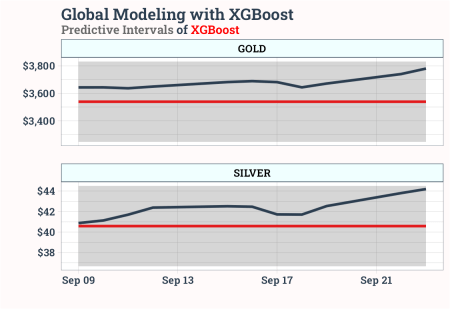
Goldman Sachs prezice că, dacă doar 1% din obligațiunile corporative se schimbă la aur, prețurile ar putea crește la 5.000 de dolari. Cu toate acestea, potrivit Xgboost Model, atât aur, cât și argint în apropierea benzilor superioare sugerează că nu este un moment bun pentru a cumpăra la aceste niveluri.
Cod sursă:
library(tidymodels)
library(tidyverse)
library(tidyquant)
library(timetk)
library(modeltime)
#Gold Futures (GC=F)
df_gold <-
tq_get("GC=F") %>%
select(date, gold = close)
#Silver Futures (SI=F)
df_silver <-
tq_get("SI=F") %>%
select(date, silver = close)
#Creating the survey data
df_survey <-
df_gold %>%
left_join(df_silver) %>%
pivot_longer(-date,
names_to = "id",
values_to = "value") %>%
mutate(id = toupper(id)) %>%
filter(date >= last(date) - months(36)) %>%
drop_na()
#Train/Test Splitting
splits <-
df_survey %>%
time_series_split(assess = "15 days",
cumulative = TRUE)
#Recipe
#The step_normalize() function is breaking the decision splits.
#Reducing the model's accuracy led to its removal.
rec_spec <-
recipe(value ~ ., training(splits)) %>%
step_string2factor("id") %>%
step_mutate_at(id, fn = droplevels) %>%
step_timeseries_signature(date) %>%
step_rm(date) %>%
step_dummy(all_nominal_predictors(), one_hot = TRUE) %>%
step_zv(all_predictors()) %>%
step_corr(all_predictors())
#Preprocessed data variables
rec_spec %>%
prep() %>%
bake(new_data = NULL) %>%
glimpse()
#Workflow fit
wflw_fit <-
workflow() %>%
add_model(
boost_tree("regression") %>%
set_engine("xgboost")
) %>%
add_recipe(rec_spec) %>%
fit(training(splits))
#Create a Modeltime Table
model_tbl <-
modeltime_table(wflw_fit)
#Calibrating by ID
calib_tbl <-
model_tbl %>%
modeltime_calibrate(
new_data = testing(splits),
id = "id"
)
#Measuring Test Accuracy
#Global Accuracy
calib_tbl %>%
modeltime_accuracy(acc_by_id = FALSE) %>%
table_modeltime_accuracy(.interactive = FALSE)
#Local Accuracy
calib_tbl %>%
modeltime_accuracy(acc_by_id = TRUE) %>%
table_modeltime_accuracy(.interactive = TRUE)
#Prediction intervals were used similarly to the Relative Strength Index (RSI).
calib_tbl %>%
modeltime_forecast(
new_data = testing(splits),
actual_data = testing(splits),
conf_by_id = TRUE) %>%
group_by(id) %>%
plot_modeltime_forecast(
.facet_ncol = 1,
.interactive = FALSE,
.line_size = 1.5
) +
labs(title = "Global Modeling with XGBoost",
subtitle = "Predictive Intervals of XGBoost",
y = "", x = "") +
scale_y_continuous(labels = scales::label_currency()) +
scale_x_date(labels = scales::label_date("%b %d"),
date_breaks = "4 days") +
theme_tq(base_family = "Roboto Slab", base_size = 16) +
theme(plot.subtitle = ggtext::element_markdown(face = "bold"),
plot.title = element_text(face = "bold"),
plot.background = element_rect(fill = "snow"),
strip.text = element_text(face = "bold", color = "black"),
strip.background = element_rect(fill = "azure"),
axis.text= element_text(face = "bold"),
legend.position = "none")