(Acest articol a fost publicat pentru prima dată pe Rstats – cuantificatși cu amabilitate a contribuit la R-bloggeri). (Puteți raporta problema legată de conținutul acestei pagini aici)
Doriți să vă distribuiți conținutul pe R-bloggeri? dați clic aici dacă aveți un blog, sau aici dacă nu aveți.
Cum își ritmează maratonianul obișnuit cursa? În această postare, vom folosi R pentru a arunca o privire asupra unui set mare de date de timpi de maraton pentru a încerca să răspundem la această întrebare.
Strategia ideală ar fi „chiar împărțirea” cursei. Aici alergi continuu în același ritm de la kilometrul 0 până la sosire. Să uităm de „diviziunea negativă”. Aici accelerezi cursa, de obicei alergând într-un ritm constant în prima jumătate sau trei sferturi și apoi crescând ritmul. Diviziunile negative sunt pentru profesioniști, nu simpli muritori! Dificultatea cu împărțirea egală a cursei este că este foarte greu să știi ce ritm poți menține. Maratonul devine greu pentru toată lumea după 30 de km, așa că o încetinire este aproape inevitabilă. Cu siguranță, dacă ai început prea repede, o vei face se estompează. Această situație este cunoscută sub denumirea de „divizare pozitivă”.
De ce este atât de greu să știi ce ritm poți menține? Ei bine, puteți prezice un ritm pe baza curselor existente, de exemplu semi-maraton, și există diferite moduri de a face acest lucru, dar este dificil de spus dacă puteți menține acel ritm pentru maraton. Este un eveniment atât de brutal încât antrenamentul pentru a alerga necesită timp și, în egală măsură, este nevoie de ceva timp pentru a se recupera, deci experimentarea este limitată. A alerga un maraton complet (în ritm) la antrenament, nu este recomandată. Deci, determinarea unui ritm ideal implică destul de multe presupuneri.
Să aruncăm o privire la un set mare de date despre timpii maratonului – vom folosi Maratonul din New York City din 2025 – pentru a vedea dacă putem înțelege cum să ritmem un maraton. Există un set de date disponibil de timpi de cip (înseamnă că nu trebuie să ne facem griji cu privire la datele GPS suspecte) și cursul are profiluri similare în prima și a doua jumătate, permițându-ne să folosim acești timpi pentru a înțelege împărțirea negativă/uniformă/pozitivă. Să ne scufundăm.
Puteți sări peste cod pentru a juca împreună sau pur și simplu să vedeți analiza aici.
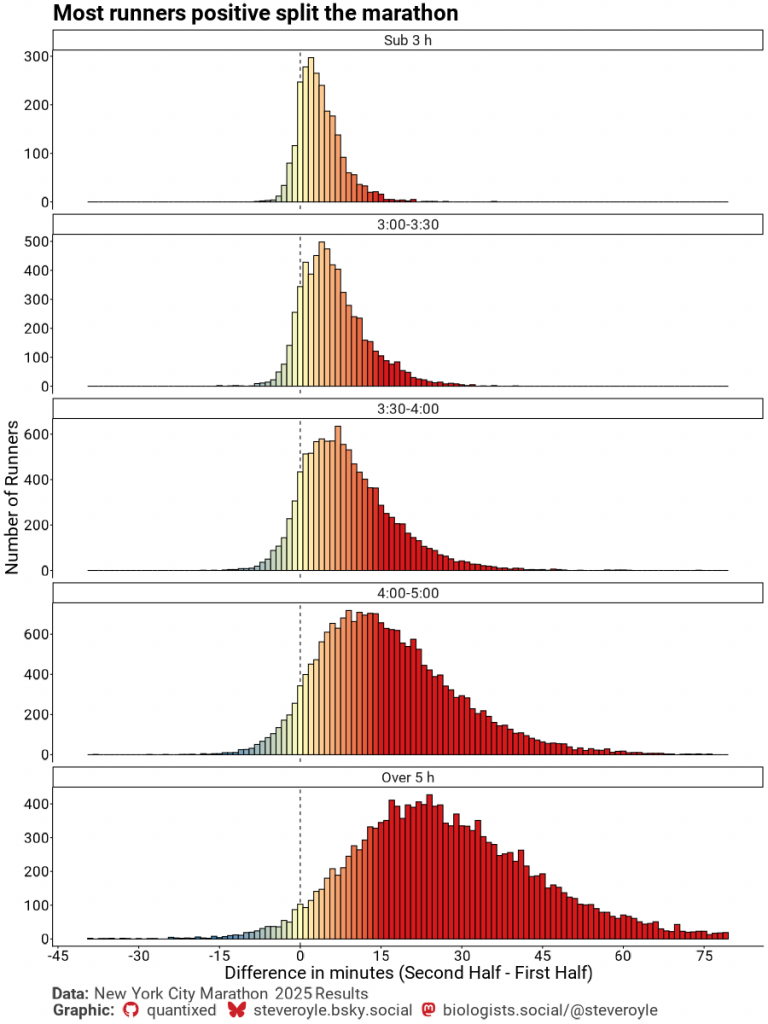
Mai întâi putem vedea folosind histograme diferența dintre a doua jumătate și prima jumătate a maratonului, că majoritatea alergătorilor au împărțit maratonul. Sunt foarte puțini alergători care rulează un negativ-split (barele albastre, la stânga liniei întrerupte). Mai mulți alergători s-au împărțit egal (galben), dar majoritatea parcurg timpi parțiali pozitivi (roșu).
Pentru maratoniștii cu finisare în timpi mai mici de 3 ore, repartiția modală este de doar +2 minute. Peste 21,1 km aceasta este doar o pierdere de 6 s pe km. Pentru maratoniştii cu finisaje de peste trei ore, această pierdere devine mai gravă. Cei care termină în afara celor 5 ore, expediază 20 de minute sau mai mult în a doua jumătate.
La prima vedere, acest lucru pare a fi o gestionare mai bună a ritmului de către alergătorii mai rapizi, dar aceste împărțiri pozitive ar putea fi proporționale cu ritmurile alergate. Cu alte cuvinte, un alergător mai lent ar trebui să trimită mai mult timp în a doua jumătate, pentru că aleargă mai încet.
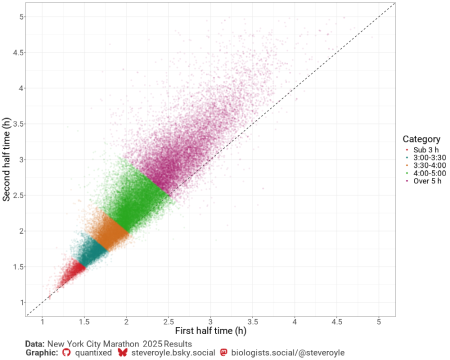
Putem privi aceste date într-un mod diferit și putem compara direct prima și a doua jumătate de timp pentru fiecare alergător. Din nou, acest lucru evidențiază cât de puțini alergători au negativ sau chiar au împărțit maratonul. Majoritatea sunt împărțiri pozitive și se află în jumătatea din stânga sus a parcelei. Putem vedea, de asemenea, că datele se îndepărtează de diviziunea uniformă ideală (linia întreruptă) cu ritmurile mai lente. Această virare pare liniară (linie dreaptă).
Putem potrivi o linie la aceste date și să o constrângem să treacă prin (1,1), adică un maratonist de 2 ore, împărțind cursa. Pentru a face acest lucru în R putem folosi lm(formula = I(y - 60) ~ I(x - 60) + 0, data = fitting) iar aceasta dă coeficientul pentru I(x – 60) ca 1.24. Acesta este în esență coeficient de estompare pentru alergătorul mediu în ediția din 2025 a acestei curse.
Ce înseamnă asta? Ei bine, pentru un alergător care realizează o primă repriză de 90 de minute, a doua repriză ar fi cel mai probabil: 60 + 1.239 * (90 – 60) = 97.17 minute, deci acesta ar fi un timp de final de 3:07:10.
Pentru oricine dorește să alerge un maraton de la New York de 3 ore, alergătorul mediu ar trebui, prin urmare, să alerge 60 / 2,239 + 60 = 86,8 minute pentru prima repriză pentru a anticipa estomparea. Deci 1:26:48 pentru prima repriză și apoi 1:33:12 pentru a doua repriză.
Un calcul mai simplu este să luăm media raportului dintre cele două jumătăți de timp pentru toată lumea din setul de date. Acest lucru dă un coeficient de estompare de 1.13. Diferența dintre acești doi coeficienți de estompare se datorează lipsei de constrângere utilizată în potrivire. Raportul prezice o împărțire pozitivă inevitabilă pentru cei mai rapizi alergători, ceea ce probabil nu este adevărat. Oricum, acest lucru pune prima repriză la 88 de minute pentru cei care doresc să alerge 3 ore. Acești coeficienți de estompare sunt buni predictori pentru o serie de timpi și bănuiesc că ar fi similari la alte evenimente maraton cu un profil similar. Le puteți folosi pentru a calcula ritmul ideal pentru un timp țintă de final.
În cele din urmă, pentru cel mai precis răspuns despre ritmul sub 3 ore, putem să ne uităm direct la alergătorii care termină între 02:50:00 și 03:00:00 și să vedem ce au alergat de fapt. Timpul median al primei reprize a fost de 86,3 min (IQR = 84,4 – 87,87), iar a doua jumătate a fost de 89,62 (88,07 – 91,12). Acest lucru oferă un timp mediu de terminare de 2:56:00. Așadar, rularea unei prime reprize de 1:26:18 ar oferi cuiva cea mai bună șansă de a termina în mai puțin de 3 ore, permițând inevitabilul estompare.
Mesajul de la pachet este: pentru a termina într-un timp obiectiv, nu presupuneți nici măcar împărțiri. Adică, dacă vrei să alergi 3 ore și 30 de minute și să folosești 90 de minute pe jumătate (4:59/km), cel mai probabil nu vei reuși să atingi ținta. Construiți un tampon de timp pentru a permite decolorarea inevitabilă. Un ritm de 4:45/km este un ritm țintă mai bun (vezi mai jos).
Noroc!
| Timpul de terminare | Chiar și ritmul divizat | Ritmul țintă |
| 03:00:00 | 00:04:16 | 00:04:07 |
| 03:30:00 | 00:04:59 | 00:04:45 |
| 04:00:00 | 00:05:41 | 00:05:23 |
| 04:30:00 | 00:06:24 | 00:06:01 |
| 05:00:00 | 00:07:07 | 00:06:39 |
| 06:00:00 | 00:08:32 | 00:07:55 |
Codul
Această analiză a fost posibilă datorită încărctorului pentru a pune la dispoziție datele despre timpul cipului. De asemenea, un mulțumire lui Nicola Rennie pentru că ne-a împărtășit cum să modelați mânerele din rețelele sociale {ggplot2} grafică. Această parte a codului meu necesită {qBrand} bibliotecă și ar trebui sărită dacă executați singur codul (eliminați fișierul caption = cap argument în apelurile ggplot).
library(ggplot2)
library(ggtext)
sysfonts::font_add_google("Roboto", "roboto")
showtext::showtext_auto()
## data wrangling ----
# load csv file from url
url <- paste0("https://huggingface.co/datasets/donaldye8812/",
"nyc-2025-marathon-splits/resolve/main/",
"nyrr_marathon_2025_summary_56480_runners_WITH_SPLITS.csv")
df <- read.csv(url)
# the data frame is a long table
# we need to grab the time values where splitCode is "HALF" or "MAR"
df <- df(df$splitCode %in% c("HALF", "MAR"), c("RunnerID", "splitCode", "time"))
# reshape to wide format, values are in time
df <- reshape(df, idvar = "RunnerID", timevar = "splitCode", direction = "wide")
# calculate the split times in minutes
df$split_HALF <- as.numeric(
as.difftime(df$time.HALF, format = "%H:%M:%S", units = "mins"))
df$split_MAR <- as.numeric(
as.difftime(df$time.MAR, format = "%H:%M:%S", units = "mins"))
# calculate the second half time
df$split_SECOND_HALF <- df$split_MAR - df$split_HALF
# remove rows with NA values
df <- df(!is.na(df$split_SECOND_HALF), )
# calculate the difference
df$Difference <- df$split_SECOND_HALF - df$split_HALF
# difference as a fraction of first half
df$Difference_Fraction <- df$Difference / df$split_HALF * 100
# classify into sub 3 hr, sub 4 hr, sub 5 hr, sub 6 hr, over 6 hr
df$Category <- cut(df$split_MAR,
breaks = c(0, 180, 210, 240, 300, Inf),
labels = c("Sub 3 h", "3:00-3:30", "3:30-4:00",
"4:00-5:00", "Over 5 h"))
## plot styling ----
social <- qBrand::qSocial()
cap <- paste0(
"**Data:** New York City Marathon 2025 Results
**Graphic:** ",social
)
my_palette <- c("Sub 3 h" = "#cb2029",
"3:00-3:30" = "#147f77",
"3:30-4:00" = "#cf6d21",
"4:00-5:00" = "#28a91b",
"Over 5 h" = "#a31a6d")
## make the plots ----
ggplot(df, aes(x = Difference, fill = after_stat(x))) +
# vertical line at x = 0
geom_vline(xintercept = 0, linetype = "dashed", color = "black") +
geom_histogram(breaks = seq(
from = -59.5, to = 81.5, by = 1), color = "black") +
scale_colour_gradient2(
low = "#2b83ba",
mid = "#ffffbf",
high = "#d7191c",
midpoint = 0,
limits = c(-15,15),
na.value = "#ffffffff",
guide = "colourbar",
aesthetics = "fill",
oob = scales::squish
) +
scale_x_continuous(breaks = seq(-45,90,15), limits = c(-40, 80)) +
facet_wrap(~ Category, ncol = 1, scales = "free_y") +
labs(caption = cap) +
labs(title = "Most runners positive split the marathon",
x = "Difference in minutes (Second Half - First Half)",
y = "Number of Runners",
caption = cap) +
theme_classic() +
# hide legend
theme(legend.position = "none") +
theme(
plot.caption = element_textbox_simple(
colour = "grey25",
hjust = 0,
halign = 0,
margin = margin(b = 0, t = 5),
size = rel(0.9)
),
text = element_text(family = "roboto", size = 16),
plot.title = element_text(size = rel(1.2),
face = "bold")
)
ggsave("Output/Plots/nyc_marathon_2025_split_difference_histogram.png",
width = 900, height = 1200, dpi = 72, units = "px", bg = "white")
ggplot() +
geom_abline(slope = 1, linetype = "dashed", color = "black") +
geom_point(data = df,
aes(x = split_HALF, y = split_SECOND_HALF, colour = Category),
shape = 16, size = 1.5, alpha = 0.1) +
scale_x_continuous(breaks = seq(from = 0, to = 12 * 30, by = 30),
labels = seq(from = 0, to = 6, by = 0.5),
limits = c(1 * 60, 5 * 60)) +
scale_y_continuous(breaks = seq(from = 0, to = 12 * 30, by = 30),
labels = seq(from = 0, to = 6, by = 0.5),
limits = c(1 * 60, 5 * 60)) +
scale_colour_manual(values = my_palette) +
labs(x = "First half time (h)",
y = "Second half time (h)",
caption = cap) +
theme_bw() +
theme(
plot.caption = element_textbox_simple(
colour = "grey25",
hjust = 0,
halign = 0,
margin = margin(b = 0, t = 10),
size = rel(0.9)
),
text = element_text(family = "roboto", size = 16)
) +
guides(colour = guide_legend(override.aes = list(alpha = 1)))
ggsave("Output/Plots/nyc_marathon_2025_split_difference_scatter.png",
width = 1000, height = 800, dpi = 72, units = "px", bg = "white")
Din aceste date putem face și câteva calcule pentru a înțelege…
## fitting ----
# to fit, we'll constrain the line to go through (60,60), i.e. a
# 2 h marathoner who runs even splits
fitting <- data.frame(x = df$split_HALF,y = df$split_SECOND_HALF)
lm( I(y-60) ~ I(x-60) + 0, data = fitting)
# Call:
# lm(formula = I(y - 60) ~ I(x - 60) + 0, data = fitting)
#
# Coefficients:
# I(x - 60)
# 1.239
# so for a 90 minute first half, second half would be:
# 60 + 1.239 * (90 - 60) = 97.17 minutes, a finish time of 3:07:10
# to run a 3 h New York Marathon, the average runner needs to run
# 60 / 2.239 + 60 = 86.8 minutes for the first half
# so 1:26:48 for the first half, and 1:33:12 for the second half
# a more simple approach is to calculate the mean of the ratios
mean_ratio <- mean(df$split_SECOND_HALF / df$split_HALF)
mean_ratio
# (1) 1.127581
# filter the df for finish times between 170 and 180 minutes
target <- df(df$split_MAR > 170 & df$split_MAR < 180,)
summary(target)
RunnerID time.HALF time.MAR split_HALF split_MAR split_SECOND_HALF Difference
Min. :48819892 Length:1289 Length:1289 Min. :70.25 Min. :170.0 Min. : 82.70 Min. :-7.6833
1st Qu.:48834548 Class :character Class :character 1st Qu.:84.42 1st Qu.:173.6 1st Qu.: 88.07 1st Qu.: 0.7167
Median :48849752 Mode :character Mode :character Median :86.30 Median :176.0 Median : 89.62 Median : 3.0500
Mean :48849498 Mean :85.98 Mean :175.7 Mean : 89.73 Mean : 3.7585
3rd Qu.:48864551 3rd Qu.:87.87 3rd Qu.:178.2 3rd Qu.: 91.12 3rd Qu.: 5.9000
Max. :48878979 Max. :92.87 Max. :180.0 Max. :106.02 Max. :35.7667
Difference_Fraction Category
Min. :-8.5008 Sub 3 h :1289
1st Qu.: 0.8051 3:00-3:30: 0
Median : 3.5390 3:30-4:00: 0
Mean : 4.5178 4:00-5:00: 0
3rd Qu.: 7.0055 Over 5 h : 0
Max. :50.9134
—
Titlul postării provine din „Marathon Man” de Ian Brown de pe albumul său „My Way”. Poartă un trening pe copertă, dar aceasta nu este o ținută optimă pentru alergarea unui maraton.