Diferența dintre distribuțiile valorilor a două rastere
Rasterele constau din valori și, astfel, pare posibil să se compare distribuțiile acestor valori. Cu toate acestea, s-ar putea să nu fie simplu, deoarece pot avea lungimi, intervale etc. diferite. Există multe modalități posibile de a crea distribuții din raster, dar aici vă arăt doar una:
- Extrageți valorile care nu lipsesc din rastere.
- Redimensionați valorile în intervalul de la 0 la 1.
- Bin valorile pentru a crea histograme.
- Normalizați numărul histogramelor pentru a obține distribuții de probabilitate.
Este important că abordarea de mai sus implică multe decizii, de exemplu, dacă folosim valorile minime și maxime ale ambelor rastere sau ale fiecăruia separat; câte pubele ar trebui să folosim; etc.
# 1. Extract the non-missing values from the rasters values1 = na.omit(values(ndvi2023_tartu)(, 1)) values2 = na.omit(values(ndvi2023_poznan)(, 1)) # 2. Scale the values to the range of 0 to 1 values1_rescaled = (values1 - min(values1)) / (max(values1) - min(values1)) values2_rescaled = (values2 - min(values2)) / (max(values2) - min(values2)) # 3. Bin the values to create histograms bin_edges = seq(0, 1, length.out = 33) hist1 = hist(values1_rescaled, breaks = bin_edges, plot = FALSE) hist2 = hist(values2_rescaled, breaks = bin_edges, plot = FALSE) # 4. Normalize the histogram counts to get probability distributions prob1 = hist1$counts / sum(hist1$counts) prob2 = hist2$counts / sum(hist2$counts)
Apoi, putem calcula diferența dintre cele două distribuții, de exemplu, folosind divergența Kullback-Leibler implementată în filentropie pachet (HG 2018).1
philentropy::distance(rbind(prob1, prob2), method = "kullback-leibler")
kullback-leibler
0.1033112
Valorile mai mici ale divergenței Kullback-Leibler sugerează că distribuțiile sunt mai asemănătoare.
Abordarea de mai sus poate fi generalizată cu o singură modificare – valorile maxime și minime sunt parametri externi.
get_min_max = function(rast_list){
min_v = min(vapply(rast_list,
FUN = function(r) min(na.omit(values(r)(, 1))),
FUN.VALUE = numeric(1)))
max_v = max(vapply(rast_list,
FUN = function(r) max(na.omit(values(r)(, 1))),
FUN.VALUE = numeric(1)))
return(c(min_v, max_v))
}
prepare_hist = function(r, min_v, max_v){
values_r = na.omit(values(r)(, 1))
values_r_rescaled = (values_r - min_v) / (max_v - min_v)
bin_edges = seq(0, 1, length.out = 33) # 32 bins
hist_r = hist(values_r_rescaled, breaks = bin_edges, plot = FALSE)
prob_r = hist_r$counts / sum(hist_r$counts)
return(prob_r)
}
min_max = get_min_max(list(ndvi2018_tartu, ndvi2023_tartu, ndvi2023_poznan))
tartu2018_hist = prepare_hist(ndvi2018_tartu, min_max(1), min_max(2))
tartu2023_hist = prepare_hist(ndvi2023_tartu, min_max(1), min_max(2))
poznan2023_hist = prepare_hist(ndvi2023_poznan, min_max(1), min_max(2))
philentropy::distance(rbind(tartu2018_hist, tartu2023_hist, poznan2023_hist),
method = "kullback-leibler")
v1 v2 v3 v1 0.000000 2.48398816 2.65464473 v2 2.483988 0.00000000 0.08389761 v3 2.654645 0.08389761 0.00000000
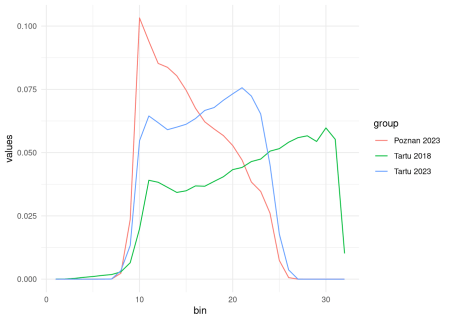
Rezultatele sugerează că distribuțiile valorilor NDVI pentru Tartu și Poznan în 2023 sunt mai asemănătoare între ele decât cu distribuția valorilor NDVI pentru Tartu în 2018.
Ca bonus, putem vizualiza histogramele valorilor NDVI pentru cele trei rastere.
df_hist = data.frame(
values = c(tartu2018_hist, tartu2023_hist, poznan2023_hist),
group = rep(c("Tartu 2018", "Tartu 2023", "Poznan 2023"), each = 32),
bin = rep(1:32, 3))
library(ggplot2)
ggplot(df_hist, aes(x = bin, y = values, color = group)) +
geom_line() +
theme_minimal()