Puzzle-uri nr. 574–578

Puzzle-uri
Autor: ExcelBI
Toate fișierele (xlsx cu puzzle și R cu soluție) pentru fiecare puzzle sunt disponibile pe Github-ul meu. Bucurați-vă.
Puzzle #574
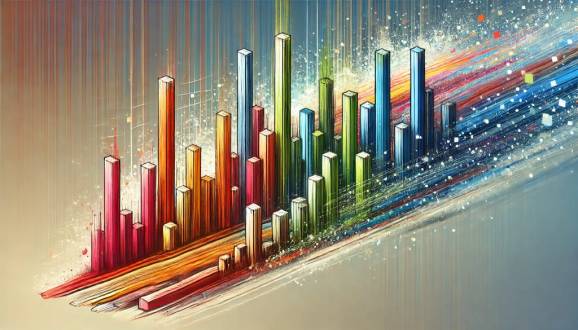

Avem un exercițiu militar ciudat pe numere astăzi. Ca un seargent care strigă „Fie prima dată, pas înainte” și apoi trebuie să le sortăm în ordinea înălțimii. Dar o facem pe șiruri formate din cifre. Cifrele din poziția impară trebuie sortate separat de cele pare. Este posibil? Desigur.
Se încarcă biblioteci și date
library(tidyverse) library(readxl) path = "Excel/574 Sort Numbers in Odd Positions Only.xlsx" input = read_excel(path, range = "A1:A10") test = read_excel(path, range = "B1:B10")
Transformare
process_numbers = function(number) {
number = strsplit(as.character(number), "")((1))
odd = seq(1, length(number), by = 2)
number(odd) = sort(as.numeric(number(odd)))
paste(number, collapse = "")
}
result = input %>%
mutate(`Answer Expected` = map_chr(Numbers, process_numbers))
Validare
all.equal(result$`Answer Expected`, test$`Answer Expected`) #> (1) TRUE
Puzzle #575


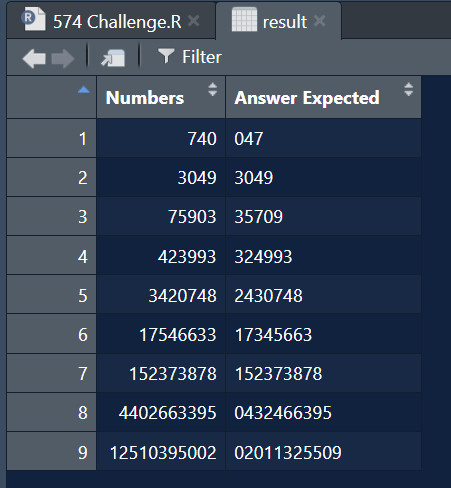
Astăzi avem de ales cine câștigă sub sau peste media departamentului. Din păcate, managerii de departamente ne oferă date despre niște bucăți de hârtie, ca un șir lung de nume și sume. Așa că trebuie să-l separăm de date granulare înainte de a putea face calcule.
Se încarcă biblioteci și date
library(tidyverse) library(readxl) path = "Excel/575 List Above and Below Average Salary.xlsx" input = read_excel(path, range = "A2:B9") test = read_excel(path, range = "D2:E13")
Transformare
result = input %>%
separate_rows(Names, sep = ", ") %>%
separate(Names, into = c("Name", "Salary"), sep = "-") %>%
mutate(AvgSalary = mean(as.numeric(Salary), na.rm = T),
AboveAvg = ifelse(Salary >= AvgSalary, ">= Average", "< Average")) %>%
mutate(nr = row_number(), .by = AboveAvg,
Names = paste0(Dept,"-",Name)) %>%
select(Names, AboveAvg, nr) %>%
pivot_wider(names_from = AboveAvg, values_from = Names) %>%
select(`< Average`, `>= Average`)
Validare
all.equal(result, test, check.attributes = F) #> (1) TRUE
Puzzle #576


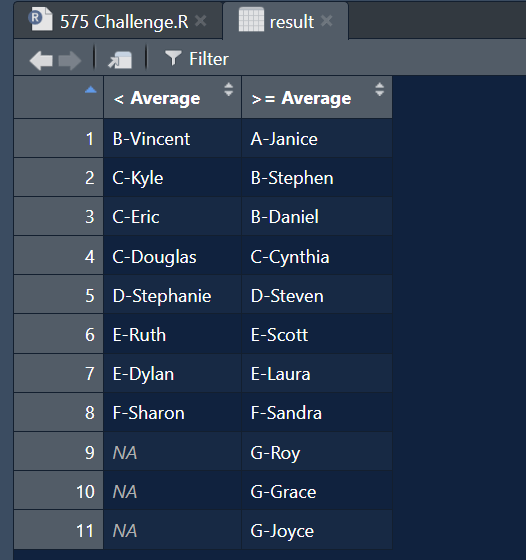
Acum avem un lucru similar ca în prima provocare, dar despre litere, nu cifre. În propozițiile următoare trebuie să obținem numai consoane și să le sortăm alfabetic. Vocalele și spațiile albe ar trebui să rămână în aceleași locuri. Și probabil puteți ghici că o vom face în mod similar ca înainte.
Se încarcă biblioteci și date
library(tidyverse) library(readxl) path = "Excel/576 Sort only Consonants.xlsx" input = read_excel(path, range = "A1:A10") test = read_excel(path, range = "B1:B10")
Transformare
process_column <- function(word) {
col <- strsplit(word, "")((1))
consonant_pos <- grep("(b-df-hj-np-tv-z)", col)
sorted_consonants <- sort(col(consonant_pos))
col(consonant_pos) <- sorted_consonants
paste(col, collapse = "")
}
result = input %>%
mutate(result = map_chr(Sentences, process_column))
Validare
all.equal(result$result, test$`Answer Expected`, check.attributes = FALSE) # (1) TRUE
Puzzle #577

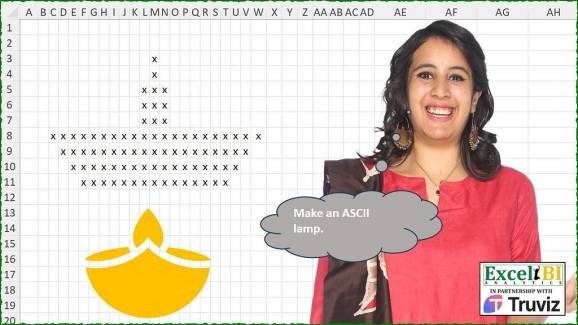
Astăzi este din nou ziua desenului. Și avem de desenat o lumânare. M-am gândit că va fi o idee bună să o ilustrez cu două tipuri de lumânări care luminează acele zile în întreaga lume. Cultura indiană sărbătorește Divali, Festivalul Luminii, iar în țările occidentale există o perioadă de Ziua Tuturor Sfinților, când oamenii lasă lumânări pe morminte pentru a-și comemora descendenții. Să ne facem lumânarea.
Se încarcă biblioteci și date
library(tidyverse) library(readxl) path = "Excel/577 Make ASCII Lamp.xlsx" test = read_excel(path, range = "B2:X11", col_names = F) %>% as.matrix() test(is.na(test)) <- ""
Transformare
centered = function(matrix, row, how_many) {
pad <- (ncol(matrix) - how_many) %/% 2
matrix(row, ) <- c(rep("", pad), rep("x", how_many), rep("", ncol(matrix) - how_many - pad))
matrix
}
M = matrix("", nrow = 10, ncol = 23)
M <- reduce(2:3, ~centered(.x, .y, 1), .init = M)
M <- reduce(4:6, ~centered(.x, .y, 3), .init = M)
M <- reduce(7:10, ~centered(.x, .y, 21 - (.y - 7) * 2), .init = M)
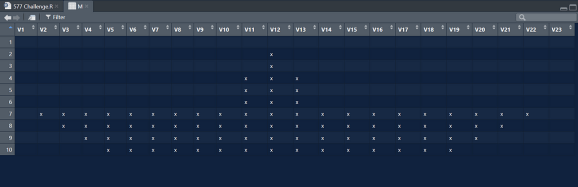
Validare
all.equal(M, test, check.attributes = F) #> (1) TRUE
Puzzle #578

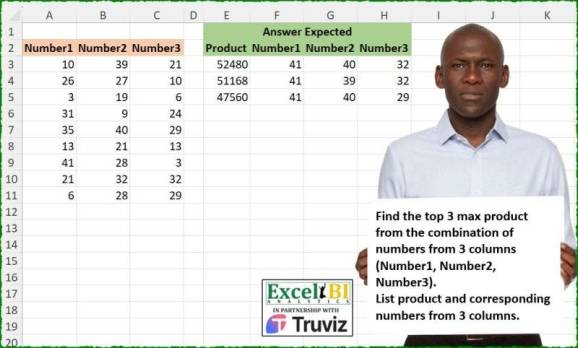
Obținem 3 seturi de numere și trebuie să facem ceva combinatoric astăzi. Trebuie să găsim care combinație (un număr din fiecare coloană) ne oferă cel mai mare număr, sau mai degrabă primele 3 dintre ele ca produs. Folosind funcția expand.grid nu este foarte mare lucru. Verificați.
Se încarcă biblioteci și date
library(tidyverse) library(readxl) path = "Excel/578 Find Maximum Product.xlsx" input = read_excel(path, range = "A2:C11") test = read_excel(path, range = "E2:H5")
Transformare
result = expand.grid(Number1 = input$Number1, Number2 = input$Number2, Number3 = input$Number3) %>% mutate(Product = Number1 * Number2 * Number3) %>% arrange(desc(Product)) %>% slice(1:3) %>% select(Product, everything())
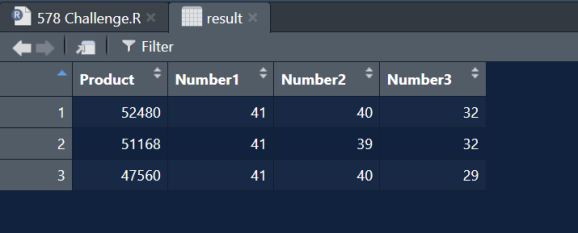
Validare
all.equal(result, test, check.attributes = FALSE) # (1) TRUE
Simțiți-vă liber să comentați, să distribuiți și să mă contactați cu sfaturi, întrebări și ideile dvs. despre cum să îmbunătățiți orice. Contactați-mă și pe Linkedin dacă doriți.
Pe depozitul meu Github există și soluții pentru aceleași puzzle-uri în Python. Verifică!
![]()
![]()
R Solution for Excel Puzzles a fost publicat inițial în Numbers around us on Medium, unde oamenii continuă conversația evidențiind și răspunzând la această poveste.