(Acest articol a fost publicat pentru prima dată pe Generarea noastră de dateși a contribuit cu drag la R-Bloggers). (Puteți raporta problema despre conținutul de pe această pagină aici)
Doriți să vă împărtășiți conținutul pe R-Bloggers? Faceți clic aici dacă aveți un blog sau aici dacă nu.
Un cercetător m-a abordat recent pentru sfaturi despre un proces-randomizat cu cluster pe care îl dezvoltă. El este interesat să testeze eficacitatea a două intervenții și s -a întrebat dacă un design factorial 2 × 2 ar putea fi cea mai bună abordare.
Pe măsură ce am discutat despre intervenții (le voi numi (O) şi (B )), a devenit clar că (O) a fost obiectivul principal. Intervenţie (B ) ar putea spori eficacitatea (O)dar de unul singur, (B ) nu era de așteptat să aibă prea mult impact. (Este, de asemenea, posibil ca (O) singur nu funcționează, dar o dată (B ) este în vigoare, combinația poate profita de beneficii.) Având în vedere acest lucru, nu părea să merite să randomizeze clinicile sau furnizorii să primească B. Am fost de acord că un proces cu trei brațe randomizate de cluster-cu (1) control, (2) (O) singur și (3) (A + b )– Ar fi un design mai eficient și mai relevant.
Cu ceva timp în urmă, am scris despre o propunere de efectuare a unui studiu cu trei brațe folosind o schemă de randomizare în două etape. Acest design presupune că rezultatele în brațul îmbunătățit ( (A + b )) nu sunt corelate cu cei din brațul autonom (O) în același cluster. Pentru acest proiect, această presupunere nu părea plauzibilă, așa că am recomandat să rămân cu o randomizare standard la nivel de cluster.
Studiul are trei obiective:
- Evaluați eficacitatea (O) versus control
- Comparaţie (A + b ) contra (O) singur
- Dacă (O) singur este ineficient, comparați (A + b ) versus control
Cu alte cuvinte, vrem să facem trei comparații în perechi. Inițial, ne -am preocupat să ne ajustăm testele pentru comparații multiple. Cu toate acestea, am decis să folosim o strategie de menținere a porții care să mențină rata generală de eroare de tip I la 5%, permițând efectuarea fiecărui test la ( alpha = 0.05 ).
Acest post descrie modul în care am creat simulări pentru a evalua cerințele de mărime a eșantionului pentru procesul propus. Rezultatul principal este o măsură de timp la eveniment: timpul de la o vizită a medicului index la o vizită de urmărire, pe care intervenția își propune să o scurteze. Mai întâi am generat date de supraviețuire pe baza estimărilor din literatura de specialitate, apoi am simulat designul studiului în diferite ipoteze de mărime a eșantionului. Pentru fiecare scenariu, am generat mai multe seturi de date și am aplicat cadrul de testare a ipotezelor de menținere a porții pentru a estima puterea statistică.
Preliminarii
Înainte de a începe, iată R Pachete utilizate în această postare. În plus, am stabilit o sămânță de randomizare, astfel încât, dacă încercați să reproduceți abordarea adoptată aici, rezultatele noastre ar trebui să se alinieze.
library(simstudy) library(data.table) library(survival) library(coxme) library(broom) set.seed(8271)
Generarea datelor din timp la eveniment
Atunci când simulați rezultatele timpului de eveniment, una dintre primele decizii este cum ar trebui să arate curbele de supraviețuire care stau la baza. În mod obișnuit, încep prin definirea unei curbe pentru starea de control (de bază) și apoi generez curbe pentru brațele de intervenție în raport cu acea bază.
Obținerea parametrilor care definesc curba de supraviețuire
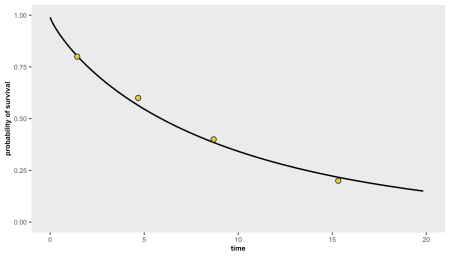
Am identificat un studiu comparabil care a raportat quintile pentru rezultatul timpului la eveniment. Mai exact, 20% dintre participanți au avut o monitorizare în 1,4 luni, 40% pe 4,7 luni, 60% pe 8,7 luni și 80% cu puțin peste 15 luni. Am folosit survGetParams Funcție din simstudy Pachet pentru a estima parametrii de distribuție Weibull – interceptarea în formula Weibull și forma – care caracterizează această curbă de supraviețuire de bază.
q20 <- c(1.44, 4.68, 8.69, 15.32) points <- list(c(q20(1), 0.80), c(q20(2), 0.60), c(q20(3), 0.40), c(q20(4), 0.20)) s <- survGetParams(points) s ## (1) -1.868399 1.194869
Putem vizualiza curba de supraviețuire idealizată care va fi generată folosind acești parametri stocați în vector s:
survParamPlot(f = s(1), shape = s(2), points, limits = c(0, 20))
Generarea de date pentru un RCT cu două brațe mai simplu
Înainte de a intra în studiul randomizat cu trei arme, am început cu un studiu controlat randomizat mai simplu, cu două brațe. Singurul covariat la nivel individual este indicatorul de tratament binar (O) care ia valori ale (0 ) (control) și (1 ) (tratament). Rezultatul timp de eveniment este o funcție a parametrilor Weibull pe care tocmai i-am generat pe baza Quintilelor, împreună cu indicatorul de tratament.
def <- defData(varname = "A", formula = "1;1", dist = "trtAssign") defS <- defSurv(varname = "time", formula = "..int + A * ..eff", shape = "..shape") |> defSurv(varname = "censor", formula = -40, scale = 0.5, shape = 0.10)
Am generat un set de date mari pentru a putea recrea curba idealizată de sus. Am presupus un raport de pericol de 2 (care este de fapt parametrizat pe scala de jurnal):
int <- s(1) shape <- s(2) eff <- log(2) dd <- genData(100000, def) dd <- genSurv(dd, defS, timeName = "time", censorName = "censor")
Iată care sunt quintilele (și mediana) de la brațul de control, care sunt destul de apropiate de Quintilele din studiu:
dd(A==0, round(quantile(time, probs = c(0.20, 0.40, 0.50, 0.60, 0.80)), 1)) ## 20% 40% 50% 60% 80% ## 1.6 4.2 6.1 8.5 16.4
Vizualizarea curbei și evaluarea proprietăților sale
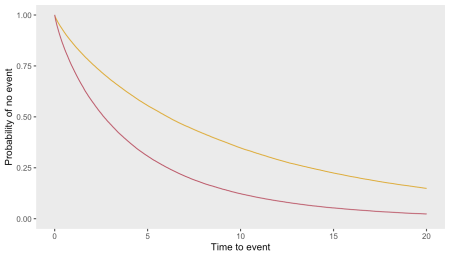
O diagramă a curbelor de supraviețuire din cele două brațe este prezentată mai jos, cu brațul de control în galben și brațul de intervenție în roșu:
![]()
Potrivirea unui model
Mă potrivesc unui model de pericole proporționale Cox doar pentru a mă asigura că pot recupera raportul de pericol pe care l -am folosit pentru a genera datele:
fit <- coxph(Surv(time, event) ~ factor(A), data = dd) tidy(fit, exponentiate = TRUE) ## # A tibble: 1 × 5 ## term estimate std.error statistic p.value #### 1 factor(A)1 1.99 0.00665 103. 0
Simularea datelor de studiu cu trei brațe
În studiul randomizat cu trei brațe propus, există trei niveluri de măsurare: pacient, furnizor și clinică. Randomizarea este realizată la nivelul furnizorului, stratificat de clinică. Pericolul pentru individ (i )tratat de furnizor (j ) în clinică (k )este modelat ca:
(h_ {ijk}
unde:
- (h_0
- ( beta_1 ) este efectul tratamentului (O) singur,
- ( beta_2 ) este efectul combinației (A + b ),
- (b_j sim n (0, sigma^2_b) ) este efectul aleatoriu pentru furnizor (j ),
- (g_k sim n (0, sigma^2_g) ) este efectul aleatoriu pentru clinică (k ),
- (A_ {ijk} = 1 ) Dacă furnizor (j ) este randomizat la tratament (O)și (0 ) altfel,
- (AB_ {ijk} = 1 ) Dacă furnizor (j ) este randomizat la tratament (A + b )și 0 altfel.
Definirea datelor
În timp ce modelul este semi-parametric (adică, nu presupune o distribuție specifică pentru orele de eveniment), procesul de generare a datelor este complet parametric, pe baza distribuției Weibull. În ciuda acestei diferențe, cele două sunt strâns aliniate: dacă totul merge bine, ar trebui să fim capabili să recuperăm parametrii folosiți pentru generarea de date atunci când încadrează modelul semi-parametric, așa cum am făcut-o în cazul RCT mai simplu de mai sus.
Generarea de date are loc în trei pași largi:
- Clinic-nivel: Generați efectul aleatoriu specific clinicii (g ).
- Nivel de furnizor: Generați efectul aleatoriu specific furnizorului (b ) și atribuiți tratament.
- Nivel de pacient: Generați rezultate individuale de timp la eveniment.
Acești pași sunt implementați folosind următoarele definiții:
defC <- defData(varname = "g", formula = 0, variance = "..s2_clinic") defP <- defDataAdd(varname = "b", formula = 0, variance = "..s2_prov") |> defDataAdd(varname = "A", formula = "1;1;1", variance = "clinic", dist = "trtAssign") defS <- defSurv( varname = "eventTime", formula = "..int + b + g + (A==2)*..eff_A + (A==3)*..eff_AB", shape = "..shape")
Generarea de date
Pentru această simulare, am asumat 16 clinici, fiecare cu 6 furnizori și 48 de pacienți pe furnizor. Un element cheie al studiului este că recrutarea are loc pe parcursul a 12 luni, iar pacienții sunt urmați până la 6 luni de la încheierea perioadei de recrutare. Astfel, durata de urmărire variază în funcție de momentul în care un pacient intră în studiu: pacienții recrutați mai devreme au o monitorizare potențială mai lungă, în timp ce cei recrutați ulterior sunt mai susceptibili să fie cenzurați.
Această monitorizare eșalonată este implementată în ultimul pas al generarii de date:
nC <- 16 # number of clinics (clusters) nP <- 6 # number of providers per clinic nI <- 48 # number of patients per provider s2_clinic <- 0.10 # variation across clinics (g) s2_prov <- 0.25 # variation across providers (b) eff_A <- log(c(1.4)) # log HR of intervention A (compared to control) eff_AB <- log(c(1.6)) # log HR of combined A+B (compared to control) ds <- genData(nC, defC, id = "clinic") dp <- genCluster(ds, "clinic", nP, "provider") dp <- addColumns(defP, dp) dd <- genCluster(dp, "provider", nI, "id") dd <- genSurv(dd, defS) # assign a patient to a particular month - 4 per month dd <- trtAssign(dd, nTrt = 12, strata = "provider", grpName = "month") dd(, event := as.integer(eventTime <= 18 - month)) dd(, obsTime := pmin(eventTime, 18 - month))
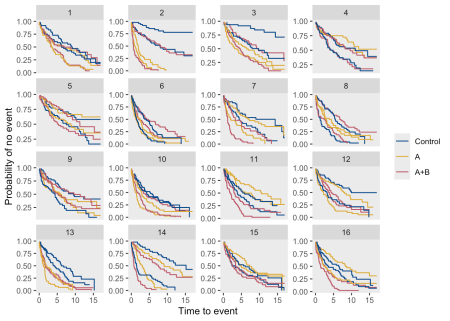
Mai jos este un complot Kaplan-Meier care prezintă curbe de supraviețuire pentru fiecare furnizor din fiecare clinică, codată de culoare de brațul de studiu:
![]()
Modelul Cox cu efecte mixte recuperează componentele de varianță și coeficienții folosiți în generarea de date:
me.fit <- coxme( Surv(eventTime, event) ~ factor(A) + (1|provider) + (1|clinic), data = dd ) summary(me.fit) ## Mixed effects coxme model ## Formula: Surv(eventTime, event) ~ factor(A) + (1 | provider) + (1 | clinic) ## Data: dd ## ## events, n = 3411, 4608 ## ## Random effects: ## group variable sd variance ## 1 provider Intercept 0.5437050 0.29561511 ## 2 clinic Intercept 0.3051615 0.09312354 ## Chisq df p AIC BIC ## Integrated loglik 919.4 4.00 0 911.4 886.9 ## Penalized loglik 1251.0 86.81 0 1077.3 544.8 ## ## Fixed effects: ## coef exp(coef) se(coef) z p ## factor(A)2 0.3207 1.3781 0.1493 2.15 0.03173 ## factor(A)3 0.4650 1.5921 0.1472 3.16 0.00158
De obicei, aș folosi această generare de date și cod de montare a modelului pentru a estima cerințele de putere sau de mărime a eșantionului. În timp ce am făcut acești pași, i -am lăsat aici, astfel încât să le puteți încerca singuri (deși sunt fericit să -mi împărtășesc codul dacă sunteți interesat). Dincolo de estimarea mărimii eșantionului, studii de simulare de acest fel pot fi utilizate și pentru a evalua ratele de eroare de tip I ale cadrului de testare a ipotezelor de menținere a porții.
Referințe:
Proschan, Ma și Brittain, EH, 2020. Un primer asupra controlului puternic vs slab al ratei de eroare în familie. Statistici în medicină, 39 (9), pp.1407-1413.