(Acest articol a fost publicat pentru prima dată pe Chris Bowdonși a contribuit cu drag la R-Bloggers). (Puteți raporta problema despre conținutul de pe această pagină aici)
Doriți să vă împărtășiți conținutul pe R-Bloggers? Faceți clic aici dacă aveți un blog sau aici dacă nu.
E timpul să plasați în sfârșit o gaură în acoperișul scurger al cunoștințelor mele: ce sunt oricum modelele liniare generalizate?
Lucrări de bază: Care sunt modelele liniare oricum?
Modelele liniare generalizate (GLMS) sunt un pas scurt de la modelele liniare, cu condiția să aveți o înțelegere corectă a modelelor liniare. Există, de asemenea, câteva jargon de statistici pentru a obține un mâner. Așa că vom începe cu o explicație intuitivă a modelelor liniare.
Cu un model liniar, avem o anumită cantitate (variabila de răspuns) pe care încercăm să o prezicem din alte cantități (predictorii). Predictorii sunt lucruri cunoscute pe care le puteți măsura cu o precizie bună, cum ar fi vârsta și greutatea. Variabila de răspuns este ceva cu variație naturală și/sau incertitudine de măsurare, cum ar fi înălțimea maximă de salt. Oameni diferiți de aceeași vârstă și greutate vor avea sărituri maxime diferite. Pentru fiecare combinație de vârstă și greutate, ne propunem să prezicem înălțimea medie a săriturilor.
Variația naturală de obicei (dar nu întotdeauna) urmează un normal distribuție pentru predictori date. Adică, ar trebui să ne așteptăm la o curbă de clopot a înălțimilor de sărituri pentru persoanele care au vârsta de 80 de ani și cântăresc 80 kg. Pentru persoanele care au vârsta de 18 ani și în greutate 60 kg, ar trebui să ne așteptăm la o curbă de clopot cu o medie diferită (probabil mai mare), dar aceeași variație. Având variația în înălțimea saltului nu Schimbarea pentru diferite vârste și greutăți este importantă, vom reveni mai târziu la asta.
Ceea ce facem într -un model liniar este să creăm o sumă ponderată a predictorilor noștri (o combinație liniară, în lingo) care prezice cel mai bine media curbei clopotului. Iată forma generală a acesteia:
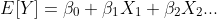
![]()
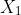 ar putea avea vârstă și
ar putea avea vârstă și ![]()
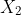 ar putea fi greutate.
ar putea fi greutate. ![]()
 Valorile sunt interceptarea și coeficienții pe care îi învățăm.
Valorile sunt interceptarea și coeficienții pe care îi învățăm.
Aici ![]()
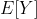 înseamnă așteptare din y, care în acest caz este doar media. Strict vorbind, ar trebui să spunem că prezicem media condiționat de predictori Deoarece nu este media tuturor observațiilor maxime de înălțime de salt, este media înălțimilor de sărituri maxime pentru o anumită vârstă și greutate. Deci ar trebui să scriem
înseamnă așteptare din y, care în acest caz este doar media. Strict vorbind, ar trebui să spunem că prezicem media condiționat de predictori Deoarece nu este media tuturor observațiilor maxime de înălțime de salt, este media înălțimilor de sărituri maxime pentru o anumită vârstă și greutate. Deci ar trebui să scriem ![]()
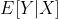 .
.
Pentru a determina acești coeficienți, folosim un algoritm precum pătratele obișnuite (OLS), care funcționează pentru a găsi coeficienții care dau mijloacele cu cele mai mici reziduuri (pătrate), adică o distanță minimă pătrată între observații și media pentru orice predictori date. Nu trebuie să știm prea multe despre cum funcționează astăzi, ci doar că este eficient și util.
Nivelul următor: GLM
Cu asta sub centura noastră, GLM -urile nu sunt atât de înfricoșătoare. Există doar două lucruri de recunoscut.
În primul rând, o distribuție normală nu este întotdeauna adecvată pentru variația naturală. Dacă mai degrabă decât înălțimea de salt, variabila noastră de răspuns a fost ceva discret, cum ar fi numărul de animale de companie? Nu puteți avea un număr de animale de animale de companie non-integral sau negativ. Am dori să schimbăm distribuția normală pentru o distribuție discretă din aceeași familie exponențială, cel mai probabil o distribuție Poisson.
Acest lucru duce direct la cel de -al doilea lucru: media unei distribuții Poisson trebuie să fie pozitivă, așa că trebuie să transformăm rezultatul acelei sume ponderate într -un fel care să o mapeze în gama valabilă a mijloacelor Poisson. Această transformare se numește Funcția de legătură. Forma acestui lucru ar fi:
![]()
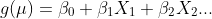
unde ![]()
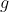 este funcția de legătură și
este funcția de legătură și ![]()
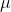 este media distribuției țintă. Dacă am avea o distribuție normală și nu este nevoie să transformăm rezultatul sumei ponderate,
este media distribuției țintă. Dacă am avea o distribuție normală și nu este nevoie să transformăm rezultatul sumei ponderate, ![]() ar fi pur și simplu funcția de identitate. Pentru o distribuție Poisson, alegerea obișnuită este
ar fi pur și simplu funcția de identitate. Pentru o distribuție Poisson, alegerea obișnuită este ![]()
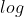 pentru că este inversul unei funcții
pentru că este inversul unei funcții ![]()
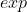 Acest lucru mapează orice număr până la un număr pozitiv.
Acest lucru mapează orice număr până la un număr pozitiv.
Pentru diferite tipuri de date, ați alege un alt tip de distribuție:
- Poisson pentru număr
- Binomial pentru probabilități binare
- Gamma pentru date continue pozitive
- Normal pentru datele distribuite în mod normal
Fiecare dintre acestea are o funcție de legătură „canonică” (standard):
- Poisson: log
- Binomial: logit
- Gamma: invers
- Normal: identitate
Puteți alege o altă funcție de legătură, dar să lăsăm asta pentru o altă zi.
Vă amintiți că modelul liniar a presupus că variația a fost constantă? GLM -urile nu au nevoie de acest lucru, deoarece pentru distribuții, altele decât distribuția normală, variația este o funcție a mediei. Termenul tehnic pentru această proprietate este heteroscedasticitatea (în timp ce o medie constantă este homoscedasticitatea).
O consecință mai importantă: din cauza funcției de legătură, nu avem neapărat o medie a variabilei de răspuns care variază liniar cu predictorii. Cu alte cuvinte, putem modela relații neliniare, ceea ce este desigur puternic.
Timp de joc
E timpul să înveți jucând. Putem folosi un set de date ciudat compilat de statisticianul rus Ladislaus von Bortkiewicz la sfârșitul anilor 1800: Decesele de la lovitura de cai pe an pentru regimentele din armata prusiană. În februarie 2025, Antony Unwin și Bill Venables au actualizat setul de date cu date suplimentare și au realizat visul original al lui Von Bortkiewicz de a -l publica pe Cran.
library(tidyverse)
library(knitr)
library(Horsekicks)
hk.tidy <- hkdeaths |>
pivot_longer(
c(kick, drown, fall),
names_to = "death.type",
values_to = "death.count"
)
hk.tidy |> head() |> kable()
Tabelul 1: Eșantionul datelor de lovitură de cai (ordonat).
| 1875 | G | 8 | 0 | 0 | lovi cu piciorul | 0 |
| 1875 | G | 8 | 0 | 0 | îneca | 3 |
| 1875 | G | 8 | 0 | 0 | cădere | 0 |
| 1875 | I | 6 | 0 | 0 | lovi cu piciorul | 0 |
| 1875 | I | 6 | 0 | 0 | îneca | 5 |
| 1875 | I | 6 | 0 | 0 | cădere | 0 |
Unwin și Venables au adăugat decese prin înec, iar decesele prin căderea unui cal, printre alte îmbunătățiri. Datele acoperă 14 corpuri, fiecare cu un număr fix de regimente, peste 33 de ani. Un regiment este de aproximativ 500 de soldați, din câte îmi dau seama. Nu am idee unde a fost Prusia sau unde a dispărut.
Să explorăm datele vizual. Plotarea morților de -a lungul timpului arată că neplăcerile ecvestre par destul de stabile, dar decesele înecate au redus. Vom potrivi un GLM la aceste serii de timp.
prussian.colours <- c("#333333", "#F9BE11", "#BE0007")
hk.year <- hk.tidy |>
group_by(year, death.type) |>
summarise(death.count = sum(death.count))
ggplot(hk.year) +
aes(x = year, y = death.count, group = death.type, colour = death.type) +
geom_line() +
scale_colour_manual(values = prussian.colours, name = "Death type") +
labs(x = "Year", y = "Number of deaths") +
theme_minimal()
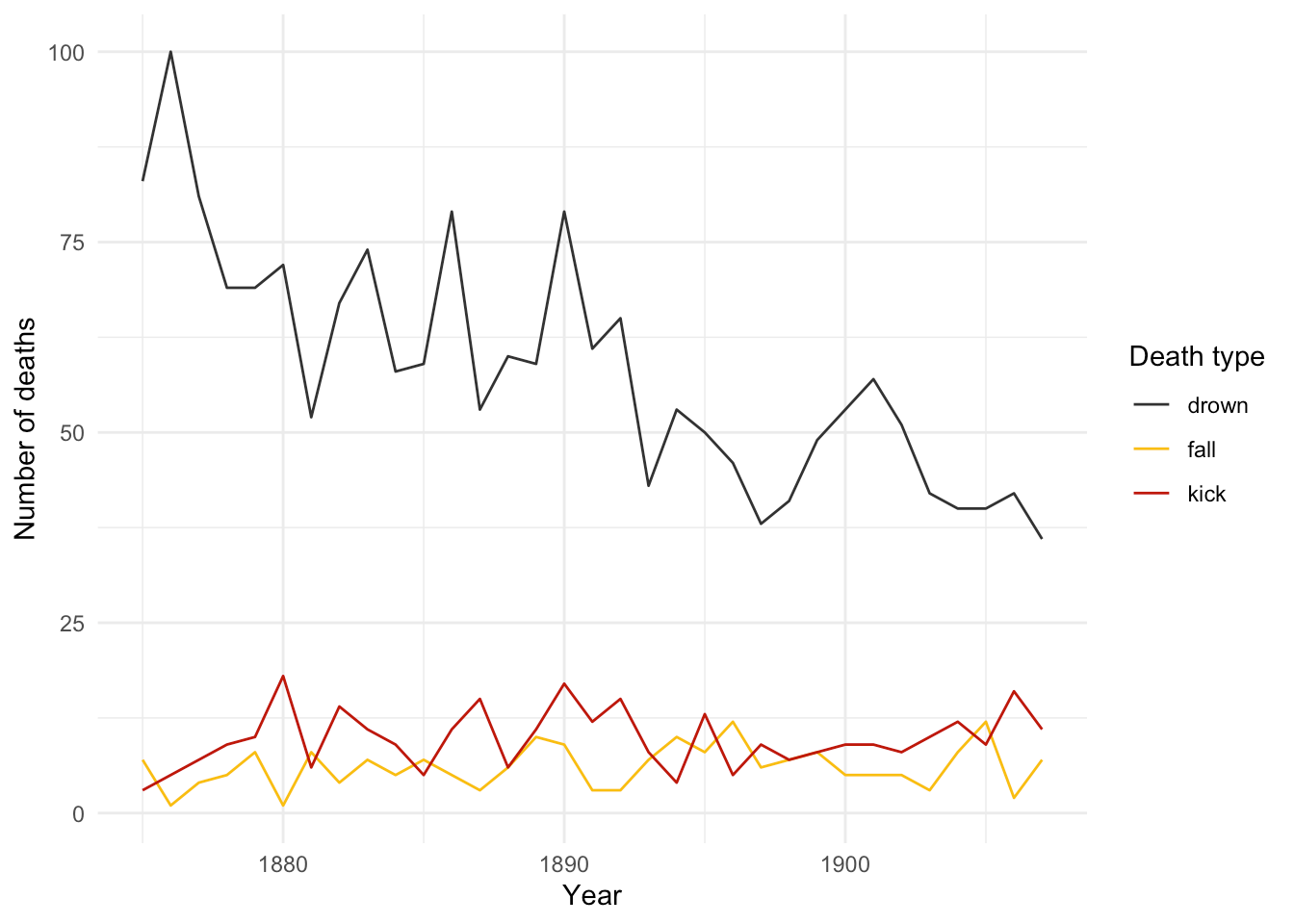
Figura 1: Moarte accidentală după tip în timp.
Rețineți că pentru fiecare tip de moarte și în fiecare an avem de fapt o distribuție pe toate regimentele, nu doar un singur număr. Am putea alege să trasăm distribuțiile ca o serie de comploturi de cutii.
ggplot(hk.tidy) + aes(x = year, y = death.count, group = year, fill = death.type) + facet_wrap(~death.type, dir = "v") + geom_boxplot(alpha = 0.5) + scale_fill_manual(values = prussian.colours, name = "Death type") + theme_minimal() + labs(x = "Year", y = "Number of deaths")
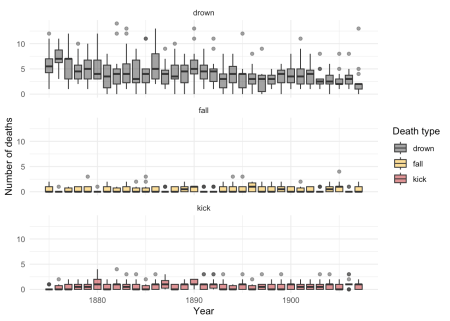
Figura 2: Distribuții de decese pentru fiecare an și tip de moarte.
Timp pentru acel model. Din moment ce nu poți fi literalmente lovit pe jumătate la moarte, cel puțin nu atât de departe Presussische Statistik era îngrijorat, toate statisticile de deces sunt număr întreg. Prin urmare, alegerea evidentă pentru distribuție este Poisson. Nu avem un motiv pentru a oferi o funcție de legătură diferită, așa că luăm doar funcția de legătură canonică pentru Poisson (jurnal).
R face acest lucru banal de făcut. glm este o funcție încorporată:
glm( formula = drown ~ year, # i.e. drownings are the response variable, year is the predictor family = poisson, data = hkdeaths )
Call: glm(formula = drown ~ year, family = poisson, data = hkdeaths) Coefficients: (Intercept) year 44.05820 -0.02256 Degrees of Freedom: 461 Total (i.e. Null); 460 Residual Null Deviance: 854.3 Residual Deviance: 766.9 AIC: 2170
Rezultatul este o interceptare (despre care nu ne pasă prea mult) și un coeficient pentru anul de -0.022, ceea ce ne spune că modelul prezice că înecările scad cu 2,2% în fiecare an.
ggplot2 face și mai ușor, permițându -ne să îmbinăm modelul de mai sus stat_smooth și rulați -l pentru fiecare tip de moarte.
ggplot(hk.year) +
aes(x = year, y = death.count, group = death.type, colour = death.type) +
geom_point() +
stat_smooth(
method = "glm",
formula = y ~ x,
method.args = list(family = poisson)
) +
scale_colour_manual(values = prussian.colours, name = "Death type") +
theme_minimal() +
labs(x = "Year", y = "Number of deaths")
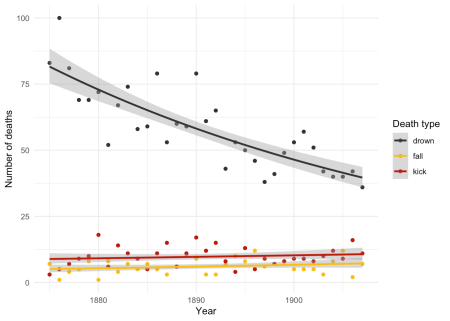
Figura 3: Moarte după tip în timp, cu GLM potrivite.
Et voila. Asta este cu adevărat tot ce a fost!