(Acest articol a fost publicat pentru prima dată pe DateAgeeekși a contribuit cu drag la R-Bloggers). (Puteți raporta problema despre conținutul de pe această pagină aici)
Doriți să vă împărtășiți conținutul pe R-Bloggers? Faceți clic aici dacă aveți un blog sau aici dacă nu.
În acest articol, am executat o integrare cu succes a unui model de prognoză Python non-standard în R în R Tidyverse/Tidymodels cadru, în primul rând folosind reticulate pachet.
1. Obiectivul (provocarea)
Scopul a fost utilizarea unui model Python puternic, personalizat (nnetsauceînvelișul MTS în jurul unui cyb$BoosterRegressor) și integrează -i rezultatele – predicții și intervale de predicție – în ecosistemul R, permițând o manipulare constantă a datelor cu dplyr și vizualizare de înaltă calitate folosind ggplot2 (și interactiv plotly)
Provocarea a fost că acest model Python personalizat nu este recunoscut în mod nativ de pachetele standard de prognoză ale R modeltime.
2. Mecanismul de integrare
Integrarea a fost obținută prin următorii pași:
reticulatePod: Am folositreticulatePachet pentru a apela perfect la modelul Python, trece datele r (tbl_train), potriviți modelul (regr$fit()) și execută prognoza (regr$predict())- Conversia datelor: Produsul de prognoză brută (predicții și intervale de încredere) de la Python a fost extrasă cu atenție și transformată într -un r standard tibble (
forecast_data_tbl) - Simularea Tidymodels (încercare inițială): Am încercat să forțăm acest tibble într -un
modeltimeStructura prin utilizarea modelelor de manechin și calibrare, care au eșuat din cauza verificărilor de validare internă rigidăplot_modeltime_forecast(). - Soluție finală Tidyverse: Am abandonat rigidul
modeltimeFuncții de vizualizare și a adoptat abordarea principală Tidyverse:- Manipularea datelor: Am folosit
dplyrşitidyr::pivot_longer()pentru a restructura datele prognozate în Format lungcare este optim pentruggplot2. - Vizualizare: Am folosit pur
ggplot2şiplotlyPentru a desena manual liniile, panglici și pentru a aplica estetica STOXX dorită, ocolind cu succes toate erorile de incompatibilitate a pachetului.
- Manipularea datelor: Am folosit
3. Constatări cheie
Procesul a evidențiat o constatare statistică critică:
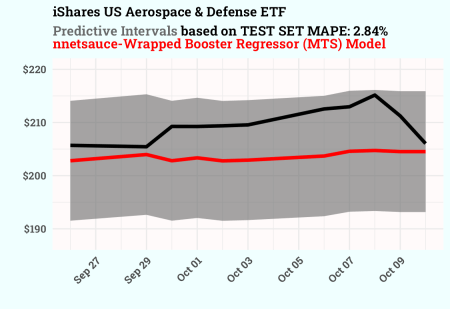
- Metric vs. discrepanță vizuală: Calitatea prognozei punctului Python Model a fost excelentă (scăzută MAPE), dar calculul său intern al intervalului de predicție (
type_pi="gaussian") a fost grav defectuos (ridicat Eroare în afara benzii) - Soluţie: Pentru a ne asigura că vizualizarea a reflectat scorul MAPE scăzut, am calculat adevăratul MAPE pe setul de testare și am generat manual un Interval de încredere realist, bazat pe MAPE Pentru a fi utilizat în complotul final.
În esență, am creat un robust Conductă centrată R. Pentru post-procesare, validare și vizualizare a prognozelor generate de un model personalizat de învățare a mașinilor Python.
library(tidyverse)
library(tidyquant)
library(reticulate)
library(tidymodels)
library(timetk)
library(modeltime)
library(plotly)
# nnetsauce_env ortamını kullanmasını söyleyin
use_python("C:/Users/selcu/AppData/Local/r-miniconda/envs/nnetsauce_env/python.exe", required = TRUE)
# Import Python packages
np <- import("numpy")
ns <- import("nnetsauce")
cyb <- import("cybooster")
sklearn <- import("sklearn")
#iShares US Aerospace & Defense ETF (ITA)
df_ita <-
tq_get("ITA") %>%
select(date, close) %>%
filter(date >= last(date) - months(36))
#Split Data
split <- time_series_split(df_ita,
assess = "15 days",
cumulative = TRUE)
tbl_train <- training(split)
tbl_test <- testing(split)
# 1. import DecisionTreeRegressor from sklearn
skl_tree <- import("sklearn.tree")
# Define the Base Estimator (The core learning component, factored for clarity)
# This uses a Decision Tree with a max depth of 3 as the weak learner for the boosting model.
base_estimator_instance <- skl_tree$DecisionTreeRegressor(max_depth = 3L)
# Define the Booster Object (The main regression engine)
# cyb$BoosterRegressor is the ensemble model that will be fitted.
booster_regressor <- cyb$BoosterRegressor(
base_estimator_instance, # The weak learner used for boosting
n_estimators = 100L # Number of boosting stages (number of trees to build)
)
# Define the MTS (Multi-variate Time Series) Model Wrapper
# ns$MTS wraps the booster model to handle time series features like lags and prediction intervals.
regr <- ns$MTS(
obj = booster_regressor, # The fitted regression model (BoosterRegressor)
# Time Series Parameters:
lags = 20L, # Number of past observations (lags) to use as predictors (X)
type_pi = "gaussian", # Method for computing Prediction Intervals (PI).
# 'gaussian' assumes errors are normally distributed.
# (NOTE: We found this to be too narrow, requiring manual adjustment with MAPE.)
# Execution Control:
show_progress = TRUE # Displays the training progress (useful for monitoring)
)
#Converting the tibble to data frame for the fitting process
df_train <-
tbl_train %>%
as.data.frame() %>%
mutate(date = as.character(date))
df <- df_train(, -1, drop = FALSE)
rownames(df) <- df_train$date
#Fit the model
regr$fit(df)
#Step 1: Extract Python Predictions and Create the Base R Data Table
# --- Define Python Function and Retrieve Predictions ---
# (Ensure this function has been run in your R session previously.)
reticulate::py_run_string("
def get_full_data_11(preds_obj):
mean_list = preds_obj(0)('close').tolist()
lower_list = preds_obj(1)('close').tolist()
upper_list = preds_obj(2)('close').tolist()
return {'mean': mean_list, 'lower': lower_list, 'upper': upper_list}
")
preds_raw <- regr$predict(h = 11L)
full_data_list <- py$get_full_data_11(preds_raw)
preds_mean_vector <- unlist(full_data_list$mean)
preds_lower_vector <- unlist(full_data_list$lower)
preds_upper_vector <- unlist(full_data_list$upper)
# Align data sets based on prediction length
vector_length <- length(preds_mean_vector)
df_test_final <- tbl_test %>% dplyr::slice(1:vector_length)
# --- Create the Base Forecast Table ---
forecast_data_tbl <- tibble(
.index = df_test_final$date,
.value = df_test_final$close,
.prediction = preds_mean_vector,
.conf_lo = preds_lower_vector, # These are the initially incorrect (too narrow) CIs
.conf_hi = preds_upper_vector, # These are the initially incorrect (too narrow) CIs
.model_desc = "nnetsauce_BoosterRegressor"
)
#Step 2: Calculate the Actual MAPE and Create Realistic Confidence Intervals
library(dplyr)
library(tibble)
library(tidyr)
# --- Step 2.1: Calculate the Actual MAPE on the Test Set ---
# Create a verification table containing error metrics
check_tbl <- forecast_data_tbl %>%
mutate(
Error = .value - .prediction,
# MAPE formula: abs(Actual - Prediction) / Actual * 100
Absolute_Percentage_Error = abs(Error) / .value * 100
)
# Actual MAPE (Calculated from the Test Set)
actual_mape_test <- mean(check_tbl$Absolute_Percentage_Error, na.rm = TRUE) / 100
# (Converting the percentage to decimal format: e.g., 2.84% -> 0.0284)
print(paste0("Calculated MAPE (decimal format): ", actual_mape_test))
# --- Step 2.2: Create New, Realistic Intervals Based on MAPE ---
Z_SCORE_95 <- 1.96 # Z-Score for 95% Confidence Interval
# Create the New Realistic Prediction Interval Table
forecast_data_tbl_realistic <- check_tbl %>%
mutate(
# Error Margin = Prediction * MAPE * Z-Score
Error_Amount = .prediction * actual_mape_test * Z_SCORE_95,
# New Confidence Intervals
.conf_lo_new = .prediction - Error_Amount,
.conf_hi_new = .prediction + Error_Amount
) %>%
# Rename/replace columns to use the new, wider intervals
mutate(
.conf_lo = .conf_lo_new,
.conf_hi = .conf_hi_new
) %>%
select(-c(Error_Amount, .conf_lo_new, .conf_hi_new, Error, Absolute_Percentage_Error))
#Visualize Confidence Intervals
# Visualization Settings
min_y <- min(forecast_data_tbl_realistic$.conf_lo) * 0.98
max_y <- max(forecast_data_tbl_realistic$.conf_hi) * 1.02
mape_value_for_title <- round(actual_mape_test * 100, 2)
COLOR_PREDICTION <- "red" # Dark Grey/Blue (Prediction)
COLOR_ACTUAL <- "black" # Red (Actual Value)
COLOR_RIBBON <- "dimgrey"
# Pivot the Base Table to Long Format (required for ggplot)
forecast_tbl_long_final <- forecast_data_tbl_realistic %>%
pivot_longer(cols = c(.value, .prediction),
names_to = ".key",
values_to = "Y_Value") %>%
mutate(
.conf_lo_plot = ifelse(.key == ".prediction", .conf_lo, NA_real_),
.conf_hi_plot = ifelse(.key == ".prediction", .conf_hi, NA_real_)
)
# Create the ggplot Object
p <- ggplot(forecast_tbl_long_final, aes(x = .index, y = Y_Value, color = .key)) +
# Draw the Confidence Interval (Ribbon)
geom_ribbon(aes(ymin = .conf_lo_plot, ymax = .conf_hi_plot),
fill = COLOR_RIBBON,
alpha = 0.6,
color = NA,
data = forecast_tbl_long_final %>% filter(.key == ".prediction")) +
# Draw the Lines
geom_line(linewidth = 2.0) +
# Y-Axis Zoom
coord_cartesian(ylim = c(min_y, max_y)) +
# Colors and Titles
labs(title = "iShares US Aerospace & Defense ETF",
subtitle = paste0("Predictive Intervals based on TEST SET MAPE: ", mape_value_for_title, "%
nnetsauce-Wrapped Booster Regressor (MTS) Model"),
x = "",
y = "",
color = "") +
scale_color_manual(values = c(".value" = COLOR_ACTUAL,
".prediction" = COLOR_PREDICTION),
labels = c(".value" = "Actual Value",
".prediction" = "Prediction")) +
scale_y_continuous(labels = scales::label_currency()) +
scale_x_date(labels = scales::label_date("%b %d"),
date_breaks = "2 days") +
theme_minimal(base_family = "Roboto Slab", base_size = 16) +
theme(plot.title = element_text(face = "bold", size = 16),
plot.subtitle = ggtext::element_markdown(face = "bold"),
plot.background = element_rect(fill = "azure", color = "azure"),
panel.background = element_rect(fill = "snow", color = "snow"),
axis.text = element_text(face = "bold"),
axis.text.x = element_text(angle = 45,
hjust = 1,
vjust = 1),
legend.position = "none")
# Interactive Output
plotly::ggplotly(p)
Notă: Acest articol a fost generat cu asistența unui model AI. Conținutul și structura finală au fost revizuite și aprobate de autor.