Testarea Super Learner cu TMLE a arătat câteva modele interesante 🤔 XGBoost + pădure aleatoare a atins doar ~54% acoperire, dar ajustat xgboost + GLM a ajuns la ~90%. Se pare că asocierea cursanților flexibili cu modele stabile (chiar specificate greșit) ajută? Trebuie să explorezi mai mult acest lucru cu diferite configurații 📊

Motivatii:
Am analizat anterior TMLE fără Super Learner și am observat acoperirea slabă a TMLE cu xgboost nespecificat în comparație cu o regresie logistică specificată corect. Acum, deoarece am învățat NNLS metoda implicită din spatele Super Learner, de ce să nu o testăm și să aruncăm o privire la acoperire! Să aruncăm o privire la graficul nostru anterior de acoperire.
![]()
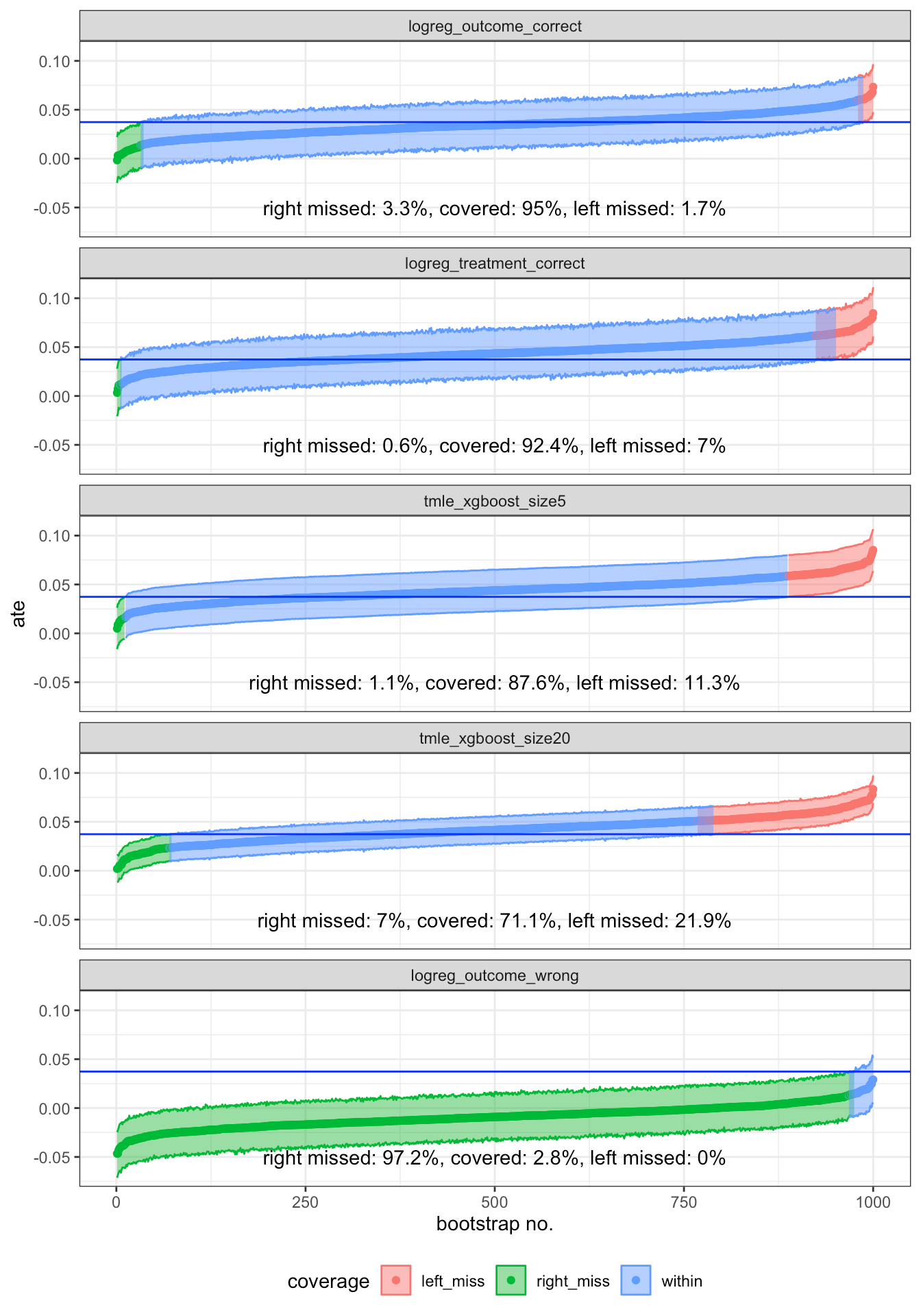
Am văzut că cu xgboost și TMLE, acoperirea noastră este de aproximativ 71,1-87,6%, iar cozile inferioare și superioare sunt asimetrice. Dacă folosim SuperLearner, putem îmbunătăți această acoperire?
Obiective
Să codificăm
Vom folosi același mecanism de generare a datelor ca înainte, dar de data aceasta vom folosi Super Learner pentru a estima scorul de înclinare și regresia rezultatului. Să scriem un cod în care să putem folosi multicore și, de asemenea, un lenovo ieftin la mâna a doua cu quad-core și Ubuntu pentru a rula și a stoca rezultatele. O parte a obiectivului meu de învățare pentru 2026 este să experimentez mai mult cu calculul paralel și să văd dacă putem explora mai mult spațiul platonic matematic folosind simulare! Rămâneți la curent cu asta, urmează mai multe despre configurarea simplă a clusterului de calcul paralel!
cod
library(dplyr)
library(SuperLearner)
library(future)
library(future.apply)
# Set up parallel processing
plan(multicore, workers = 4)
set.seed(1)
n <- 10000
W1 <- rnorm(n)
W2 <- rnorm(n)
W3 <- rbinom(n, 1, 0.5)
W4 <- rnorm(n)
# TRUE propensity score model
A <- rbinom(n, 1, plogis(-0.5 + 0.8*W1 + 0.5*W2^2 + 0.3*W3 - 0.4*W1*W2 + 0.2*W4))
# TRUE outcome model
Y <- rbinom(n, 1, plogis(-1 + 0.2*A + 0.6*W1 - 0.4*W2^2 + 0.5*W3 + 0.3*W1*W3 + 0.2*W4^2))
# Calculate TRUE ATE
logit_Y1 <- -1 + 0.2 + 0.6*W1 - 0.4*W2^2 + 0.5*W3 + 0.3*W1*W3 + 0.2*W4^2
logit_Y0 <- -1 + 0 + 0.6*W1 - 0.4*W2^2 + 0.5*W3 + 0.3*W1*W3 + 0.2*W4^2
Y1_true <- plogis(logit_Y1)
Y0_true <- plogis(logit_Y0)
true_ATE <- mean(Y1_true - Y0_true)
df <- tibble(W1 = W1, W2 = W2, W3 = W3, W4 = W4, A = A, Y = Y)
tune = list(
ntrees = c(500,1000), # More trees for better performance
max_depth = c(3,5), # Deeper trees capture interactions
shrinkage = c(0.001,0.01) # Finer learning rate control
)
learners <- create.Learner("SL.xgboost", tune = tune, detailed_names = TRUE, name_prefix = "xgb")
# Super Learner library
SL_library <- list(c("SL.xgboost", "SL.ranger", "SL.glm", "SL.mean"),
c("SL.xgboost","SL.ranger"),
c("SL.xgboost","SL.glm"),
list("SL.ranger", c("SL.xgboost", "screen.glmnet")),
c(learners$names, "SL.glm"))
# sample
n_sample <- 1000
n_i <- 6000
# Function to run one TMLE iteration
run_tmle_iteration <- function(seed_val, df, n_i, SL_library) {
set.seed(seed_val)
data <- slice_sample(df, n = n_i, replace = T) |> select(Y, A, W1:W4)
# Prepare data
X_outcome <- data |> select(A, W1:W4) |> as.data.frame()
X_treatment <- data |> select(W1:W4) |> as.data.frame()
Y_vec <- data$Y
A_vec <- data$A
# Outcome model
SL_outcome <- SuperLearner(
Y = Y_vec,
X = X_outcome,
family = binomial(),
SL.library = SL_library,
cvControl = list(V = 5)
)
# Initial predictions
outcome <- predict(SL_outcome, newdata = X_outcome)$pred
# Predict under treatment A=1
X_outcome_1 <- X_outcome |> mutate(A=1)
outcome_1 <- predict(SL_outcome, newdata = X_outcome_1)$pred
# Predict under treatment A=0
X_outcome_0 <- X_outcome |> mutate(A=0)
outcome_0 <- predict(SL_outcome, newdata = X_outcome_0)$pred
# Bound outcome predictions to avoid qlogis issues
outcome <- pmax(pmin(outcome, 0.9999), 0.0001)
outcome_1 <- pmax(pmin(outcome_1, 0.9999), 0.0001)
outcome_0 <- pmax(pmin(outcome_0, 0.9999), 0.0001)
# Treatment model
SL_treatment <- SuperLearner(
Y = A_vec,
X = X_treatment,
family = binomial(),
SL.library = SL_library,
cvControl = list(V = 5)
)
# Propensity scores
ps <- predict(SL_treatment, newdata = X_treatment)$pred
# Truncate propensity scores
ps_final <- pmax(pmin(ps, 0.95), 0.05)
# Calculate clever covariates
a_1 <- 1/ps_final
a_0 <- -1/(1 - ps_final)
clever_covariate <- ifelse(A_vec == 1, 1/ps_final, -1/(1 - ps_final))
epsilon_model <- glm(Y_vec ~ -1 + offset(qlogis(outcome)) + clever_covariate,
family = "binomial")
epsilon <- coef(epsilon_model)
updated_outcome_1 <- plogis(qlogis(outcome_1) + epsilon * a_1)
updated_outcome_0 <- plogis(qlogis(outcome_0) + epsilon * a_0)
# Calc ATE
ate <- mean(updated_outcome_1 - updated_outcome_0)
# Calc SE
updated_outcome <- ifelse(A_vec == 1, updated_outcome_1, updated_outcome_0)
se <- sqrt(var((Y_vec - updated_outcome) * clever_covariate +
updated_outcome_1 - updated_outcome_0 - ate) / n_i)
return(list(ate = ate, se = se))
}
# Run iterations in parallel
for (num in 1:length(SL_library)) {
cat("TMLE iterations in parallel with 4 workers (multicore)...n")
start_time <- Sys.time()
results_list <- future_lapply(1:n_sample, function(i) {
result <- run_tmle_iteration(i, df, n_i, SL_library((num)))
if (i %% 100 == 0) cat("Completed iteration:", i, "n")
return(result)
}, future.seed = TRUE)
end_time <- Sys.time()
run_time <- end_time - start_time
# Extract results
predicted_ate <- sapply(results_list, function(x) x$ate)
pred_se <- sapply(results_list, function(x) x$se)
# Results
results <- tibble(
iteration = 1:n_sample,
ate = predicted_ate,
se = pred_se,
ci_lower = ate - 1.96 * se,
ci_upper = ate + 1.96 * se,
covers_truth = true_ATE >= ci_lower & true_ATE <= ci_upper
)
# Summary stats
summary_stats <- tibble(
metric = c("true_ATE", "mean_estimated_ATE", "median_estimated_ATE",
"sd_estimates", "mean_SE", "coverage_probability", "bias"),
value = c(
true_ATE,
mean(predicted_ate),
median(predicted_ate),
sd(predicted_ate),
mean(pred_se),
mean(results$covers_truth),
mean(predicted_ate) - true_ATE
)
)
# Create output directory if it doesn't exist
if (!dir.exists("tmle_results")) {
dir.create("tmle_results")
}
# Save detailed results (all iterations)
write.csv(results, paste0("tmle_results/tmle_iterations",num,".csv"), row.names = FALSE)
# Save summary statistics
write.csv(summary_stats, paste0("tmle_results/tmle_summary",num,".csv"), row.names = FALSE)
# Save simulation parameters
sim_params <- tibble(
parameter = c("n_population", "n_sample_iterations", "n_bootstrap_size",
"SL_library", "n_workers", "runtime_seconds"),
value = c(n, n_sample, n_i,
paste(SL_library((num)), collapse = ", "),
4, as.numeric(run_time, units = "secs"))
)
write.csv(sim_params, paste0("tmle_results/simulation_parameters",num,".csv"), row.names = FALSE)
# Save as RData for easy loading
save(results, summary_stats, sim_params, true_ATE, file = paste0("tmle_results/tmle_results",num,".RData"))
Ca și anterior, ne-am configurat adevărata ATE și simularea și vom eșantiona 60% din N=10000 și am rulat un bootstrap de 1000. De data aceasta, în loc de ML solo, vom folosi Super Learner să ansamblăm mai multe modele și apoi să ne estimăm ATE și dacă CI de 95% acoperă ATE adevărată. Mai jos sunt combinațiile pe care le vom investiga:
- xgboost + randomforest + glm + medie
- xgboost + randomforest
- xgboost + glm
- randomforest + (xgboost + screen.glmnet) + glm
- xgboost_tuned + glm
Care este rezultatul
![]()
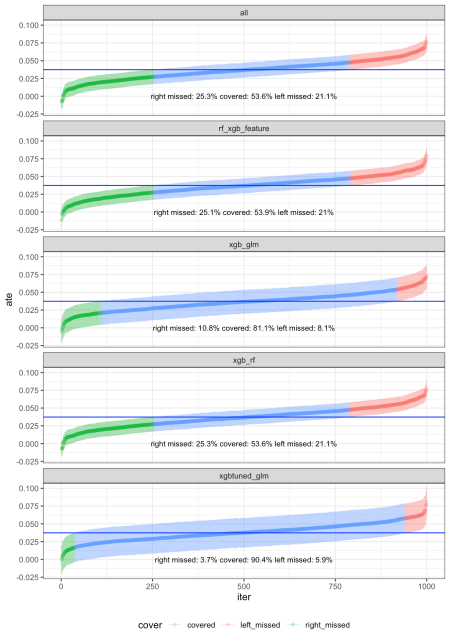
Wow, acestea sunt rezultate foarte interesante! Privind la 1) unde avem xgboost, randomforest, glm și mean, acoperirea noastră a fost destul de oribilă la ~50%. Pentru 3) cu xgboost și glm, acoperirea a crescut la ~80%, foarte similar cu xgboost-ul nostru reglat solo anterior, dar cel puțin cu neacoperire simetrică, foarte interesant. Dar când 2) am combinat atât xgboost, cât și randomforest, acoperirea a scăzut înapoi la ~50%. Același lucru s-a întâmplat când am folosit funcția de inginerie 4) glmnet înainte de xgboost, apoi cuplat cu xgboost, acoperirea a fost de numai ~50%. Dar, când 5) reglam xgboost și îl combinăm cu glm, acoperirea a crescut la ~90%! Nu mă așteptam la acest rezultat, dar este destul de uimitor! În ceea ce privește cât de mult a durat fiecare combinație pentru un procesor quadcore cu caracteristică multicore:
| metodă | time_hours |
|---|---|
| SL.xgboost, SL.ranger, SL.glm, SL.mean | 4.02 |
| SL.xgboost, SL.ranger | 4.00 |
| SL.xgboost, SL.glm | 0,47 |
| SL.ranger, SL.xgboost, screen.glmnet | 4.23 |
| reglat SL.xghboost, SL.glm | 3.29 |
Oportunități de îmbunătățire
- încercați să utilizați hiperparametri optimizați atât pentru xgboost, cât și pentru randomforest
- scrieți o funcție pentru împărțirea multicore la mai multe noduri
- încercați să utilizați NNloglik / maximize pe auc în loc de nnls, ar funcționa mai bine?
- trebuie să testăm teoria că dacă
set.seedfuncționează diferit cu multicore? Sau viitorul alege automatL'Ecuyer-CMRG Algorithm? face metoda noastră actuală deset.seed(i)numărul de iterație funcționează bine? - trebuie sa incerci
mcSuperLearnermulticore încorporat
Lecții învățate
- învăţat
future_lapply - învăţat
multicoreeste mult mai rapid!!! Deși când noifuture_lapplyfuncția pe care pare să aibă același timp camultisession - testat
Super Learnere destul de tare! Are deja opțiuni pentru calcul paralel - am aflat că amestecarea modelului flexibil precum xgboost (tuned) și logreg regularizează modelul ansamblu
Daca iti place acest articol: