(Acest articol a fost publicat pentru prima dată pe Guillaume Pressiatși cu amabilitate a contribuit la R-bloggeri). (Puteți raporta problema legată de conținutul acestei pagini aici)
Doriți să vă distribuiți conținutul pe R-bloggeri? dați clic aici dacă aveți un blog, sau aici dacă nu aveți.

Verbele dplyr sunt descriptive: să le facem mai verbose!
Încă o țeavă pentru R.
Repostează pentru o mai bună gestionare a imaginii pe bloggerii r.
![]()
Motivația
În SAS, fiecare pas DATA tipărește un jurnal:
NOTE: There were 120000 observations read from WORK.SALES.
NOTE: 7153 observations were deleted.
NOTE: The data set WORK.RESULT has 112847 observations and 11 variables.
R dplyr conductele sunt tăcute. logrittr umple acel gol cu %>=%o conductă introdusă care înregistrează numărul rândurilor, numărul coloanelor, coloanele adăugate/eliminate și sincronizarea la fiecare pas, fără mascarea funcției.
Cu ligaturi Fira Code, %>=% redă ca o singură săgeată largă similară vizual cu %>% cu o subliniere adăugată, ca un subtitlu sau, să zicem, pentru a citi între rândurile unei conducte (ce s-a întâmplat).
Contexte multiple
Lucrurile se întâmplă:
NOTE: There were 120000 observations read from WORK.SALES.
NOTE: 120000 observations were deleted.
NOTE: The data set WORK.RESULT has 0 observations and 11 variables.
„Aici am pierdut toate rândurile în execuția scriptului”.
Pro
Citirea acestui lucru mult timp după executarea unui script vă ajută să vedeți:
- ce s-a întâmplat în fiecare etapă a procesării datelor fără a fi nevoie să rulați din nou codul, de exemplu într-un mediu de producție în care datele de intrare se schimbă constant
- monitorizează procesele cheie
- Asigurați-vă că puteți explica ce sa întâmplat (un audit, de exemplu)
În contexte profesionale este adesea nevoie.
Educativ
Acest lucru va fi, de asemenea, mai clar datorită unui jurnal de consolă pentru cei cu puțină experiență cu tidyverse: oameni care fac primii pași în programare urmând un tutorial sau predându-se singuri.
Instalare
install.packages('logrittr', repos="https://guillaumepressiat.r-universe.dev")
# or from github
# devtools::install_github("GuillaumePressiat/logrittr")
Vedeți github sau r-universe.
Utilizare
library(logrittr)
library(dplyr)
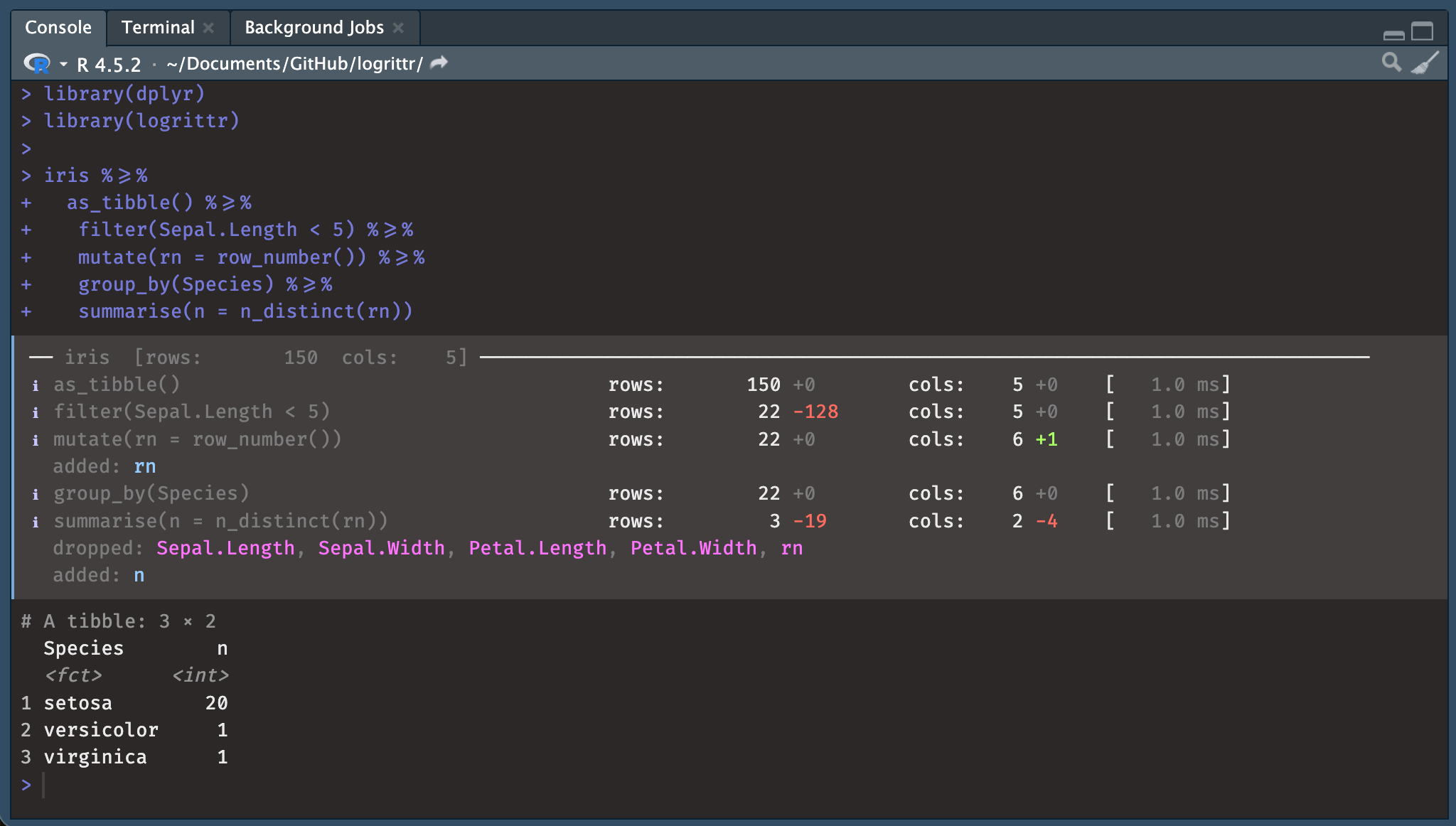
iris %>=%
as_tibble() %>=%
filter(Sepal.Length < 5) %>=%
mutate(rn = row_number()) %>=%
semi_join(
iris %>% as_tibble() %>=%
filter(Species == "setosa"),
by = "Species"
) %>=%
group_by(Species) %>=%
summarise(n = n_distinct(rn))
── iris (rows: 150 cols: 5) ─────────────────────────────────────────────────────
ℹ as_tibble() rows: 150 +0 cols: 5 +0 ( 0.0 ms)
ℹ filter(Sepal.Length < 5) rows: 22 -128 cols: 5 +0 ( 3.0 ms)
ℹ mutate(rn = row_number()) rows: 22 +0 cols: 6 +1 ( 1.0 ms)
added: rn
ℹ > filter(Species == "setosa") rows: 50 -100 cols: 5 +0 ( 1.0 ms)
ℹ semi_join(iris %>% as_tibble() %>=% rows: 20 -2 cols: 6 +0 ( 5.0 ms)
filter(Species == "setosa"), by =
"Species")
ℹ group_by(Species) rows: 20 +0 cols: 6 +0 ( 3.0 ms)
ℹ summarise(n = n_distinct(rn)) rows: 1 -19 cols: 2 -4 ( 2.0 ms)
dropped: Sepal.Length, Sepal.Width, Petal.Length, Petal.Width, rn
added: n
Captură de ecran
![]()
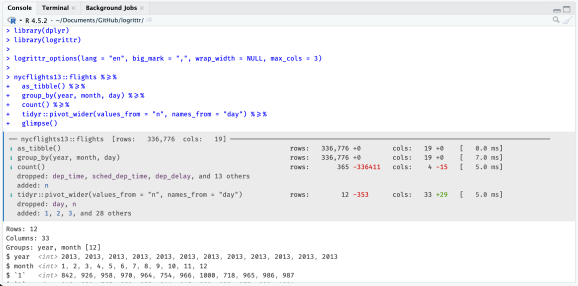
library(dplyr)
library(logrittr)
logrittr_options(lang = "en", big_mark = ",", wrap_width = NULL, max_cols = 3)
nycflights13::flights %>=%
as_tibble() %>=%
group_by(year, month, day) %>=%
count() %>=%
tidyr::pivot_wider(values_from = "n", names_from = "day") %>=%
glimpse()
tidylog este un pachet cu adevărat îngrijit care îmi dă motivație pentru acesta.
tidylog funcționează prin mascarea funcțiilor dplyr, ceea ce nu mi se pare ideal.
Oricum, acesta a fost și un moment pentru mine să testez un nou instrument de programare care este folosit foarte mult pentru programare în acest moment.
logrittr folosește un operator de conducte personalizat și nu atinge niciodată spațiul de nume dplyr. Ieșirea sa din consolă este colorată și informativă datorită pachetului cli.
Lucrul cu lumberjack
Dacă cunoașteți deja pachetul de lumberjack, compatibilitatea este disponibilă cu logrittr (timpul sunt aproximativi).
Apel logrittr_logger$new():
library(lumberjack)
library(dplyr)
l <- logrittr_logger$new(verbose = TRUE)
logfile <- tempfile(fileext=".-r.log.csv")
iris %L>%
start_log(log = l, label = "iris step") %L>%
as_tibble() %L>%
filter(Sepal.Length < 5) %L>%
mutate(rn = row_number()) %L>%
group_by(Species) %L>%
summarise(n = n_distinct(rn)) %L>%
dump_log(file=logfile, stop = FALSE)
mtcars %>%
start_log(log = l, label = "mtcars step") %L>%
count() %L>%
dump_log(file=logfile, stop = TRUE)
logdata <- read.csv(logfile)
Va scrie conținutul logrittr al mai multor pași de date în același fișier csv.
Limitări
-
Ca
tidyloglogrittr funcționează doar cu conductele dplyr pe R data.frames (în memorie) și nu poate face acest lucru cu conductele dbplyr din baze de date (tabel la distanță/lazy). -
Cardinalitățile de îmbinare bine făcute în tidylog sunt greu de obținut din conductă, deoarece îmbinarea este deja făcută, în acest moment arătăm doar evoluția N rând și N col (înainte/după).
-
Da, este o altă țeavă, nu ideală. Putem visa la o
with_logging(TRUE)context care va activa comportamentul logrittr pipe în|>sau în%>%.
Luați o altă țeavă pentru o învârtire
logrittr prioritizează experiența utilizatorului cu un afișaj structurat și colorat în consolă.
Deocamdată, acest pachet este doar o dovadă a conceptului care mi-a dat șansa de a experimenta puțin cu cli pachet și alte câteva lucruri. Dar cred că este nevoie de asta în R, într-o zonă specifică în care ieșirile SAS sunt atât de informative.