Am întâlnit recent o postare a unui inginer de învățare automată care a afirmat îndrăzneț că regresia logistică este cel mai prost nume pentru un algoritm sau ceva de genul acesta.1. Mulți statisticieni de tip mai vechi de școală păreau să nu fie de acord. Acest lucru m-a determinat să mă gândesc puțin mai profund la subiect. Am scris deja mai multe postări despre terminologia proastă în statistici (vezi nivelul de încredere, linia de cea mai bună potrivire, r pătrat), așa că s-ar fi putut aștepta să fiu de acord cu vizualizarea învățării automate, dar în acest caz sunt de acord cu statisticienii și aș dori să explic de ce.
La orele de știință a datelor, studenții sunt învățați că există două tipuri de modelare predictivă. În ambele cazuri, scopul este de a prezice un răspuns $Y$ având în vedere un vector de caracteristici $X$. Dacă $Y$ este cu valoare reală (numeric în terminologia R) atunci este a regresie problemă. Dacă $Y$ este categoric, atunci este a clasificare problemă. Nu sunt sigur de unde provine această terminologie, dar cu siguranță a fost propagată pe scară largă de clasicul lui Hastie și Tibshirani. Elementele învăţării statistice.
În regresia logistică, datele dvs. constau din unele valori caracteristice $X$ și un răspuns $Y în lbrace 0, 1 rbace$. În acest caz, răspunsul este categoric, așa că cineva instruit în știința datelor ar numi într-adevăr asta o problemă de clasificare. Dar dacă te uiți mai atent la rezultatul produs de regresia logistică, valorile sale prezise sunt numere, și anume probabilitatea ca fiecare punct de date să fie în clasa etichetată $1$. Trebuie să faceți ceva cu aceste numere (de exemplu, să folosiți o limită) pentru a obține o clasă prezisă.
De exemplu, în R:
set.seed(100)
N <- 100
a <- -1
b <- 1
x <- 2 * rnorm(N)
# simulated binary data
y <- rbinom(N, 1, 1/(1 + exp(-a -b * x)))
# plot observed values in grey
plot(x, y, pch=19, xlab="x", ylab="y",
col=rgb(0, 0, 0, 0.3), las=1)
# fit logistic regression
model <- glm(y ~ x, family="binomial")
# plot predicted values in red
points(x,
predict(model, data.frame(x=x),
type="response"),
col=rgb(1, 0, 0, 0.3),
pch=19)
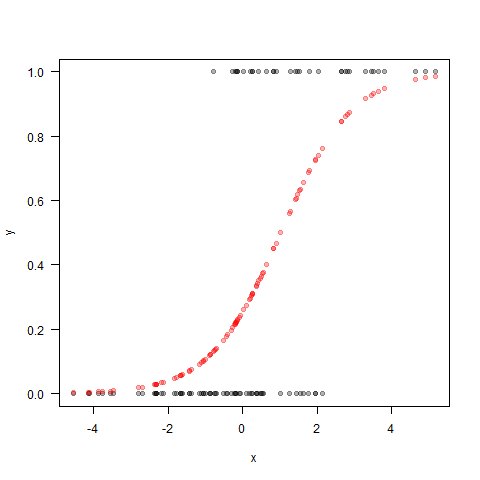
De fapt, este destul de greu să ne gândim la un algoritm de învățare automată care prezice direct apartenența la clasă, mai degrabă decât la un fel de măsură a cât de puternic este un punct de date membru al unei clase. Chiar și Naive Bayes face un fel de încercare de a prezice probabilitatea apartenenței la clasă. Cel mai simplu algoritm care prezice direct clasa în loc de probabilitatea apartenenței la clasă este algoritmul 1-cel mai apropiat vecin. (Dar dacă ai folosi un număr mai mare de vecini, să zicem 20, ai obține un fel de estimare a cât de încrezător ai fost în predicția ta.)
Termenul regresie provine din ideea lui Galton despre regresie la medie (despre care am scris aici). Inițial, aceasta a fost observația că părinții înalți tind să aibă copii mai scunzi decât ei și invers. Înălțimile copiilor par să regreseze spre media întregii populații.
Mai general, valorile răspunsului $Y$ corespunzătoare unei valori fixe a caracteristicilor $x_0$ vor urma o distribuție de probabilitate. Media acestei distribuții este $E(Y vert x_0)$. Valorile observate ale lui $Y$ se vor grupa în jurul acestei medii. Dacă desenați în mod repetat valori de $Y$, o valoare mare va tinde să fie urmată de o valoare mai mică și invers. Astfel, $E(Y vert X)$ va tinde să fie mai mic decât $Y$ dacă $Y$ este neobișnuit de mare și mai mare decât $Y$ dacă $Y$ este neobișnuit de mic2. Puteți vedea acest lucru dacă utilizați regresia liniară pentru a prezice $Y$ dat $X$, ca în exemplul următor.
set.seed(100) N <- 500 x <- rnorm(N) y <- 0.4 * x + 0.8 * rnorm(N) plot(x, y) abline(coef(lm(y~x)), col="red")
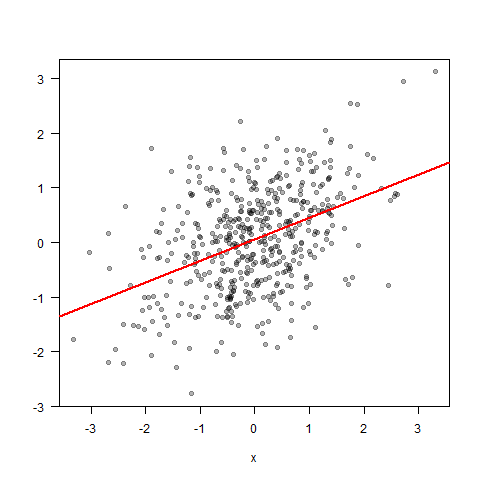
(Rețineți cum panta dreptei de regresie este mai mică decât „panta” pe care ochiul o percepe în norul de puncte de date, care este axa principală.)
Dar unii algoritmi nu vă oferă niciun efect de regresie. De exemplu, un arbore de decizie supraadaptat (aka regresor 1-NN) nu va arăta nicio regresie la medie, ca în exemplul următor. Rețineți că linia albastră nu prezice sub sau supraprevăd pentru valorile extreme ale $x$.
x <- c(1:9) y <- c(-10, seq(-1,1, length=7), 10) pred_nn <- function(xx) y(which.min(abs(xx - x))(1)) plot(x, y) abline(coef(lm(y~x)), col="red") xx <- seq(1, 9, length=1000) lines(xx, sapply(xx, pred_nn), type="s", lty=2, col="blue")
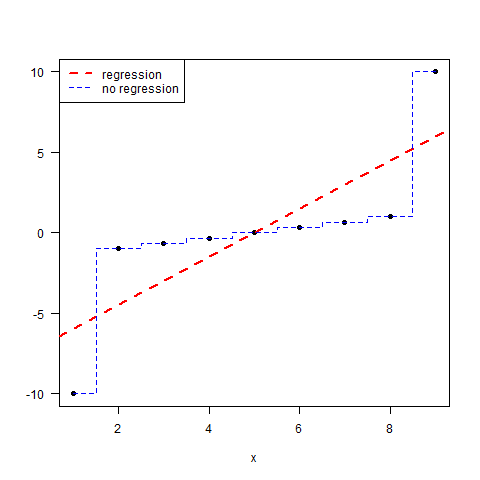
În acest caz, aveți un algoritm care prezice o valoare numerică, așa că oamenii de știință ar numi-o regresie, dar de fapt nu prezintă nicio regresie. Ce enervant!
Deși este prea târziu pentru a rescrie manualele, poate s-ar putea argumenta că regresia și clasificarea ar fi trebuit definite în felul următor. Dacă un model predictiv prezice direct un răspuns $Y$ date caracteristici $X$, atunci ar trebui să fie numit un model de clasificare (chiar dacă $Y$ este numeric, ca în exemplul anterior). Dar dacă modelul prezice $E(Y vert X)$, atunci ar trebui numit model de regresie.
Dar regresia logistică? În acest caz, modelul prezice $P(Y=1 vert X)$ care este doar $E(Y vert X)$. Deci statisticienii au avut dreptate în primul rând! Regresia logistică este un model de regresie. Acesta devine un model de clasificare doar dacă îi aplicați un al doilea model. De obicei, aceasta ia forma unui arbore de decizie care prezice $Y=1$ dacă $E(Y vert X) > p_0$ pentru o alegere de $p_0$ și $Y=0$ în caz contrar. Acest arbore de decizie este un model de clasificare. Dar regresia logistică în sine nu este.
1: Mă tem să mă numesc un data scientist în zilele noastre, parțial pentru că cred că profesia a fost devalorizată de diverse încercări de a profita de popularitatea ei (ducând la un exces de oameni cu încredere mare și experiență scăzută) și parțial pentru că cred că știința datelor devine un pic toxic, cu toate daunele din lumea reală, fiind făcute de centrele de supraveghere în masă, etc.
2: Timp de anecdote: la unul dintre vechile mele locuri de muncă a trebuit să distram un furnizor care vindea practic un flux de lucru în stil Kaggle ca produs software ca serviciu. Reprezentantul de vânzări a construit un model pe baza unora dintre datele noastre și l-a prezentat. În scrisul lor, au inclus observația că „în mod interesant, am observat că modelul tinde să subestima pentru valori mari de $x$ și să suprapredice pentru valori mici de $x$”. Ei bine, nu este foarte surprinzător pentru că asta este fiecare modelul predictiv face!