Puzzle-uri nr. 559–563

Puzzle-uri
Autor: ExcelBI
Toate fișierele (xlsx cu puzzle și R cu soluție) pentru fiecare puzzle sunt disponibile pe Github-ul meu. Bucurați-vă.
Puzzle #559

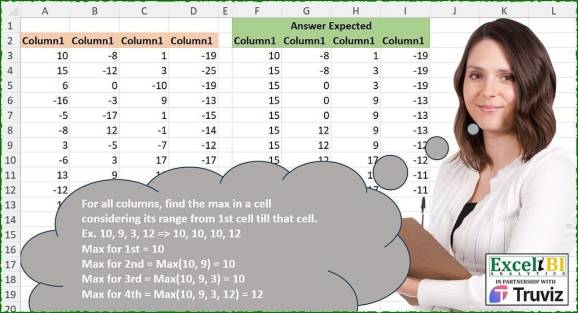
Uneori trebuie să lucrăm pe coloane. Din punct de vedere tehnic, este exact ca să lucrezi la liste și uite ce trebuie să facem cu listele astăzi. Se numește alergare maximă. De obicei avem un anumit contact cu suma sau media curentă, dar maximul rulant este puțin mai puțin popular. Nu returnează o singură cifră, ci, în mod similar, ca în cumsum, toate secvența de numere în care pentru un anumit element trebuie să agregam într-un fel toate elementele precedente (în sumă – trebuie să le însumăm, în medie – medie și în maxim alege întotdeauna max dintre toate precedente). Este destul de ușor în R, așa că verificați-l.
Se încarcă biblioteci și date
library(tidyverse) library(readxl) path = "Excel/559 Max of first N elements.xlsx" input = read_excel(path, range = "A2:D13") test = read_excel(path, range = "F2:I13")
Transformare
output = input %>% mutate(across(everything(), ~cummax(.)))
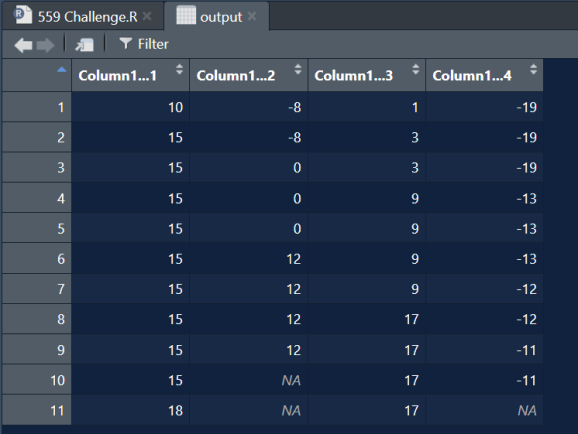
Validare
all.equal(output, test, check.attributes = FALSE) #> (1) TRUE
Puzzle #560

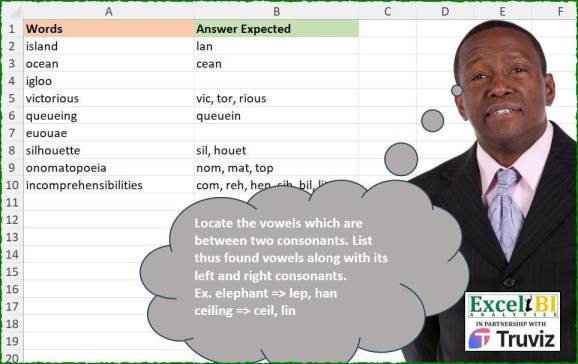
Să ne gândim la cuvinte ca la sandvișuri… astăzi trebuie să găsim toate sandvișurile pe masa noastră. Oh, nu, reveniți la Excel… nu vă gândiți la sandvișurile cu pastramă. Trebuie să găsim fiecare combinație de una sau mai multe vocale între consoane. Am găsit un obstacol în această sarcină, dar și soluția cum să extrag și acele combinații care se suprapun cu alte combinații valide precum putrefața și tor în rotor.
Se încarcă biblioteci și date
library(tidyverse) library(readxl) path = "Excel/560 Vowels between Consonants.xlsx" input = read_excel(path, range = "A1:A10") test = read_excel(path, range = "B1:B10") %>% replace_na(list(`Answer Expected` = ""))
Transformare
extract_cvc_overlap <- function(input_string) {
pattern <- "(?=((^aeiou)(aeiou)+(^aeiou)))"
str_match_all(input_string, pattern) %>%
map_chr(~ paste(.(, 2), collapse = ", ")) %>%
str_trim()
}
result = input %>%
mutate(result = map_chr(Words, extract_cvc_overlap))
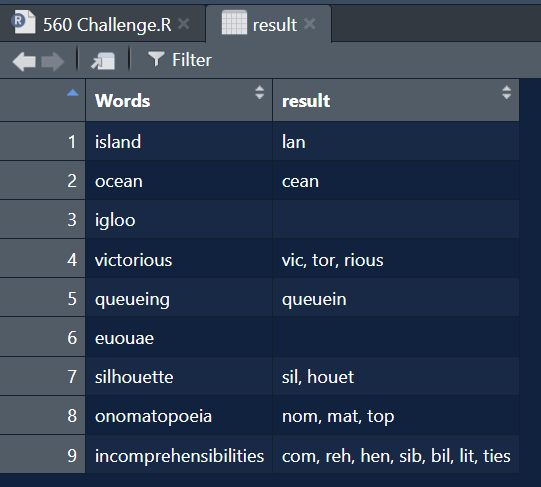
Validare
all.equal(result$result, test$`Answer Expected`, check.attributes = FALSE) #> (1) TRUE
Puzzle #561


Astăzi vom juca tranzacții cu acțiuni la scară mică. Avem 9 active și prețuri de la 10 zile și tot ce trebuie să facem este să găsim cel mai profitabil scenariu când să cumpărăm și să vindem. Desigur, probabil că am face-o mai repede manual decât scrierea codului, dar suntem aici pentru a scrie cod. Și dacă este greu de rezolvat, este și mai satisfăcător. Verificați.
Se încarcă biblioteci și date
library(tidyverse) library(readxl) path = "Excel/561 Maximum Profit.xlsx" input = read_excel(path, range = "A2:J11") test = read_excel(path, range = "K2:M11") %>% mutate(across(everything(), ~if_else(.x == "NP", NA_real_, as.numeric(.x))))
Transformare
process_row <- function(...){
row <- c_across(everything())
cell_list <- map(1:length(row), ~row(.x:length(row)))
df_pairs <- map_dfr(1:length(cell_list), function(i) {
tibble(
from = rep(row(i), length(cell_list((i))) - 1),
to = cell_list((i))(-1)
)
})
df_pairs <- df_pairs %>%
mutate(diff = to - from)
max_pair <- df_pairs %>%
slice_max(diff, with_ties = FALSE)
return(list(
max_diff = max_pair$diff,
from_value = max_pair$from,
to_value = max_pair$to
))
}
result <- input %>%
rowwise() %>%
mutate(result = list(process_row(across(everything())))) %>%
mutate(
Buy = result$from_value,
Sell = result$to_value,
Profit = result$max_diff
) %>%
ungroup() %>%
select(Buy, Sell, Profit) %>%
mutate(across(everything(), ~if_else(Profit <= 0, NA_real_, .x)))
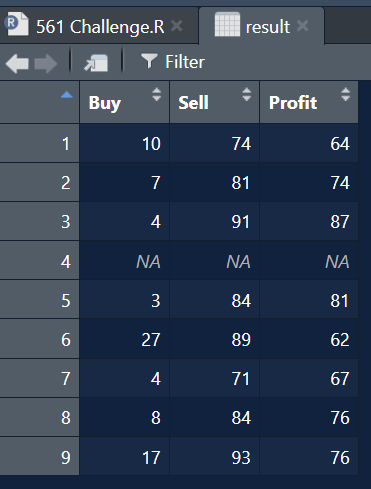
Validare
all.equal(result, test, check.attributes = FALSE) # (1) TRUE
Puzzle #562


Palindromuri, palindromuri… Cred că Vijay A. Verma nu va găsi sfârșitul tărâmului palindromurilor prea curând. Astăzi subiectul nostru este palindromul unui copil. Ce înseamnă că numărul are copil? Înseamnă că subșirul de număr este divizibil cu lungimea unui astfel de număr original. Deci, dacă vrem un număr cu un singur copil, trebuie să găsim unul care dintre toate subșirurile are doar unul care este divizibil prin lungimea numărului original. Dar trebuie să-l amestecăm și cu proprietățile palindromului și să găsim 1000 de primele numere cu toate acele proprietăți împreună.
Este o soluție destul de lentă, dar funcționează bine.
Se încarcă biblioteci și date
library(tidyverse) library(readxl) path = "Excel/562 One Child Palindromes.xlsx" test = read_excel(path, range = "A1:A1001")
Transformare
has_one_child <- function(n) {
nchar = nchar(n)
if (nchar == 1) {
return(FALSE)
}
grid_coord = expand.grid(1:nchar, 1:nchar)
substrings = apply(grid_coord, 1, function(x) {
substr(n, x(1), x(2))
}) %>%
as.numeric() %>%
.(!is.na(.) & . != 0) %>%
unique()
substrings = substrings(substrings %% nchar == 0)
return(length(substrings) == 1)
}
generate_all_palindromes <- function(num_digits) {
if (num_digits < 1) {
stop("Number of digits must be at least 1")
}
if (num_digits == 1) {
return(0:9)
}
half_digits <- ceiling(num_digits / 2)
start_num <- 10^(half_digits - 1)
end_num <- 10^half_digits - 1
palindromes <- vector("integer", length = 0)
for (i in start_num:end_num) {
num_str <- as.character(i)
rev_str <- paste0(rev(strsplit(num_str, "")((1))), collapse = "")
if (num_digits %% 2 == 0) {
palindrome_str <- paste0(num_str, rev_str)
} else {
palindrome_str <- paste0(num_str, substring(rev_str, 2))
}
palindromes <- c(palindromes, as.integer(palindrome_str))
}
return(palindromes)
}
palindrome_df <- tibble(num_digits = 1:9) %>%
mutate(palindromes = map(num_digits, generate_all_palindromes))
res = palindrome_df %>%
unnest(cols = c(palindromes)) %>%
mutate(palindromes = as.integer(palindromes),
has_one_child = map_lgl(palindromes, has_one_child))
result = res %>%
filter(has_one_child == TRUE, palindromes > 10) %>%
head(1000) %>%
select(palindromes)
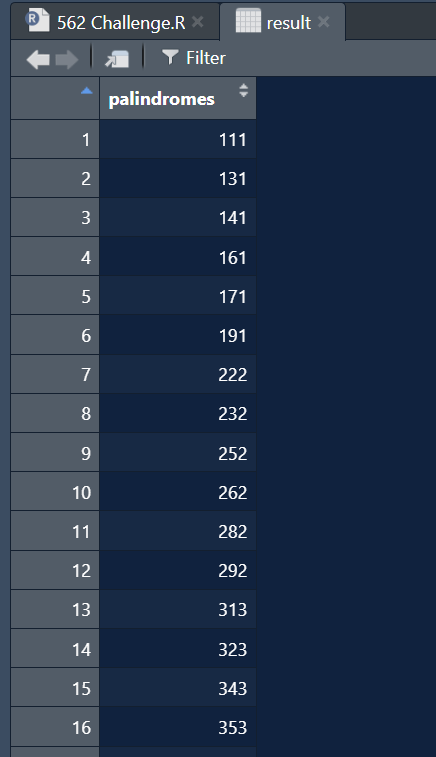
Validare
all.equal(test$`Answer Expected`, result$palindromes, check.attributes = FALSE) # (1) TRUE
Puzzle #563

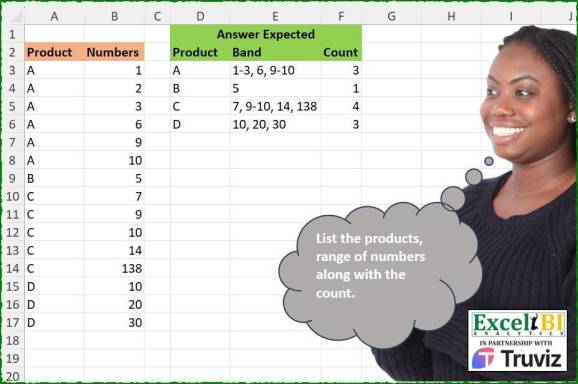
Cu ceva timp în urmă am făcut lucruri similare, dar altfel. Când avem unele notații de interval, trebuia să le împărțim în numere din interval, dar de data aceasta trebuie să facem alt mod. Dacă găsim numere consecutive în grupuri, le restrângem în interval. Află cum am făcut-o.
Se încarcă biblioteci și date
library(tidyverse) library(readxl) path = "Excel/563 Bands of Numbers.xlsx" input = read_excel(path, range = "A2:B17") test = read_excel(path, range = "D2:F6")
Transformare
result = input %>%
mutate(Group = cumsum(c(1, diff(Numbers)) != 1), .by = Product) %>%
mutate(Band = ifelse(n() == 1, paste0(Numbers), paste0(Numbers(1), "-", Numbers(n()))),
.by = c(Product, Group)) %>%
summarise(Bands = paste0(unique(Band), collapse = ", "),
Count = n_distinct(Band),
.by = Product)
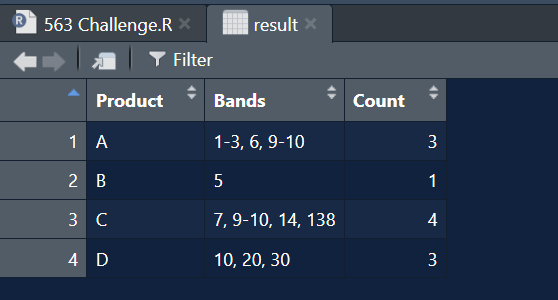
Validare
all.equal(result, test, check.attributes = FALSE) # (1) TRUE
Simțiți-vă liber să comentați, să distribuiți și să mă contactați cu sfaturi, întrebări și ideile dvs. despre cum să îmbunătățiți orice. Contactați-mă și pe Linkedin dacă doriți.
Pe depozitul meu Github există și soluții pentru aceleași puzzle-uri în Python. Verifică!
![]()
![]()
R Solution for Excel Puzzles a fost publicat inițial în Numbers around us on Medium, unde oamenii continuă conversația evidențiind și răspunzând la această poveste.