Cadrele de date sunt coloana vertebrală a analizei datelor în R, iar a ști cum să-și proceseze eficient rândurile este o abilitate crucială pentru orice programator R. Indiferent dacă curățați date, efectuați calcule sau transformați valori, înțelegerea tehnicilor de iterare a rândurilor vă va îmbunătăți semnificativ capacitățile de manipulare a datelor. În acest ghid cuprinzător, vom explora diferite metode de iterare pe rânduri de cadre de date, de la bucle de bază la tehnici avansate folosind pachete R moderne.
Structura de bază
Un cadru de date în R este o structură bidimensională, asemănătoare unui tabel, care organizează datele în rânduri și coloane. Gândiți-vă la ea ca la o foaie de calcul în care:
- Fiecare coloană reprezintă o variabilă
- Fiecare rând reprezintă o observație
- Diferite coloane pot conține diferite tipuri de date (numerice, caractere, factori etc.)
# Creating a simple data frame
df <- data.frame(
name = c("John", "Sarah", "Mike"),
age = c(25, 30, 35),
salary = c(50000, 60000, 75000)
)
Accesarea elementelor cadru de date
Înainte de a trece la iterație, să revizuim metodele de bază de acces la cadrele de date:
# Access by position first_row <- df(1, ) first_column <- df(, 1) # Access by name names_column <- df$name
Utilizarea For Loops
Cea mai simplă metodă este utilizarea unei bucle for:
# Basic for loop iteration
for(i in 1:nrow(df)) {
print(paste("Processing row:", i))
print(df(i, ))
}
(1) "Processing row: 1" name age salary 1 John 25 50000 (1) "Processing row: 2" name age salary 2 Sarah 30 60000 (1) "Processing row: 3" name age salary 3 Mike 35 75000
While Loops
Deși sunt mai puțin frecvente, buclele while pot fi utile pentru iterația condiționată:
# While loop example
i <- 1
while(i <= nrow(df)) {
if(df$age(i) > 30) {
print(df(i, ))
}
i <- i + 1
}
name age salary 3 Mike 35 75000
Aplicați funcțiile familiei
Familia de aplicații oferă alternative mai eficiente:
# Using apply
result <- apply(df, 1, function(row) {
# Process each row
return(sum(as.numeric(row)))
})
# Using lapply with data frame rows
result <- lapply(1:nrow(df), function(i) {
# Process each row
return(df(i, ))
})
Folosind pachetul purrr
Pachetul purrr, parte a ecosistemului tidyverse, oferă soluții elegante pentru iterare:
library(purrr)
library(dplyr)
# Using map functions
df %>%
map_df(~{
# Process each element
if(is.numeric(.)) return(. * 2)
return(.)
})
# A tibble: 3 × 3 name age salary1 John 50 100000 2 Sarah 60 120000 3 Mike 70 150000
# Row-wise operations with pmap
df %>%
pmap(function(name, age, salary) {
# Custom processing for each row
list(
full_record = paste(name, age, salary, sep=", "),
salary_adjusted = salary * (1 + age/100)
)
})
((1)) ((1))$full_record (1) "John, 25, 50000" ((1))$salary_adjusted (1) 62500 ((2)) ((2))$full_record (1) "Sarah, 30, 60000" ((2))$salary_adjusted (1) 78000 ((3)) ((3))$full_record (1) "Mike, 35, 75000" ((3))$salary_adjusted (1) 101250
Abordări Tidyverse
Programarea R modernă folosește adesea funcții ordonate pentru un cod mai curat și mai ușor de întreținut:
library(tidyverse)
# Using rowwise operations
df %>%
rowwise() %>%
mutate(
bonus = salary * (age/100), # Simple bonus calculation based on age percentage
total_comp = salary + bonus
) %>%
ungroup()
# A tibble: 3 × 5 name age salary bonus total_comp1 John 25 50000 12500 62500 2 Sarah 30 60000 18000 78000 3 Mike 35 75000 26250 101250
# Using across for multiple columns df %>% mutate(across(where(is.numeric), ~. * 1.1))
name age salary 1 John 27.5 55000 2 Sarah 33.0 66000 3 Mike 38.5 82500
Managementul memoriei
# Bad practice: Growing objects in a loop
result <- vector()
for(i in 1:nrow(df)) {
result <- c(result, process_row(df(i,))) # Memory inefficient
}
# Good practice: Pre-allocate memory
result <- vector("list", nrow(df))
for(i in 1:nrow(df)) {
result((i)) <- process_row(df(i,))
}
Gestionarea erorilor
# Robust error handling
safe_process <- function(df) {
tryCatch({
for(i in 1:nrow(df)) {
result <- process_row(df(i,))
if(is.na(result)) warning(paste("NA found in row", i))
}
}, error = function(e) {
message("Error occurred: ", e$message)
return(NULL)
})
}
Exemplul 1: Iterație simplă de rând
# Create sample data
sales_data <- data.frame(
product = c("A", "B", "C", "D"),
price = c(10, 20, 15, 25),
quantity = c(100, 50, 75, 30)
)
# Calculate total revenue per product
sales_data$revenue <- apply(sales_data, 1, function(row) {
as.numeric(row("price")) * as.numeric(row("quantity"))
})
print(sales_data)
product price quantity revenue 1 A 10 100 1000 2 B 20 50 1000 3 C 15 75 1125 4 D 25 30 750
Exemplul 2: Procesare condiționată
# Process rows based on conditions
high_value_sales <- sales_data %>%
rowwise() %>%
filter(revenue > mean(sales_data$revenue)) %>%
mutate(
status = "High Value",
bonus = revenue * 0.02
)
print(high_value_sales)
# A tibble: 3 × 6 # Rowwise: product price quantity revenue status bonus1 A 10 100 1000 High Value 20 2 B 20 50 1000 High Value 20 3 C 15 75 1125 High Value 22.5
Exemplul 3: Transformarea datelor
# Complex transformation example
transformed_data <- sales_data %>%
rowwise() %>%
mutate(
revenue_category = case_when(
revenue < 1000 ~ "Low",
revenue < 2000 ~ "Medium",
TRUE ~ "High"
),
# Replace calculate_performance with actual metrics
efficiency_score = (revenue / (price * quantity)) * 100,
profit_margin = ((revenue - (price * 0.7 * quantity)) / revenue) * 100
) %>%
ungroup()
print(transformed_data)
# A tibble: 4 × 7 product price quantity revenue revenue_category efficiency_score profit_margin1 A 10 100 1000 Medium 100 30 2 B 20 50 1000 Medium 100 30 3 C 15 75 1125 Medium 100 30 4 D 25 30 750 Low 100 30
Acum este timpul să exersezi! Iată o provocare:
Provocare: creați o funcție care:
- Preia un cadru de date cu date de vânzări
- Calculează ratele lunare de creștere
- Semnalează modificări semnificative (>10%)
- Returnează un raport rezumat
Exemplu de soluție:
analyze_sales_growth <- function(sales_df) {
sales_df %>%
arrange(date) %>%
mutate(
growth_rate = (revenue - lag(revenue)) / lag(revenue) * 100,
significant_change = abs(growth_rate) > 10
)
}
# Test your solution with this data:
test_data <- data.frame(
date = seq.Date(from = as.Date("2024-01-01"),
by = "month", length.out = 12),
revenue = c(1000, 1200, 1100, 1400, 1300, 1600,
1500, 1800, 1700, 1900, 2000, 2200)
)
analyze_sales_growth(test_data)
date revenue growth_rate significant_change 1 2024-01-01 1000 NA NA 2 2024-02-01 1200 20.000000 TRUE 3 2024-03-01 1100 -8.333333 FALSE 4 2024-04-01 1400 27.272727 TRUE 5 2024-05-01 1300 -7.142857 FALSE 6 2024-06-01 1600 23.076923 TRUE 7 2024-07-01 1500 -6.250000 FALSE 8 2024-08-01 1800 20.000000 TRUE 9 2024-09-01 1700 -5.555556 FALSE 10 2024-10-01 1900 11.764706 TRUE 11 2024-11-01 2000 5.263158 FALSE 12 2024-12-01 2200 10.000000 FALSE
- Vectorizarea În primul rând: Luați în considerare întotdeauna operațiunile vectorizate înainte de a implementa bucle
- Eficiența memoriei: Pre-alocați memorie pentru operațiuni mari
- Abordări moderne: Tidyverse și purrr oferă soluții mai curate și mai ușor de întreținut
- Performanța contează: Alegeți metoda de iterație potrivită pe baza dimensiunii datelor și a complexității operațiunii
- Gestionarea erorilor: implementați o gestionare robustă a erorilor pentru codul de producție
Iată o comparație a diferitelor metode de iterație folosind un exemplu de referință:
library(microbenchmark)
# Create a large sample dataset
large_df <- data.frame(
x = rnorm(10000),
y = rnorm(10000),
z = rnorm(10000)
)
# Benchmark different methods
benchmark_test <- microbenchmark(
for_loop = {
for(i in 1:nrow(large_df)) {
sum(large_df(i, ))
}
},
apply = {
apply(large_df, 1, sum)
},
vectorized = {
rowSums(large_df)
},
times = 100
)
print(benchmark_test)
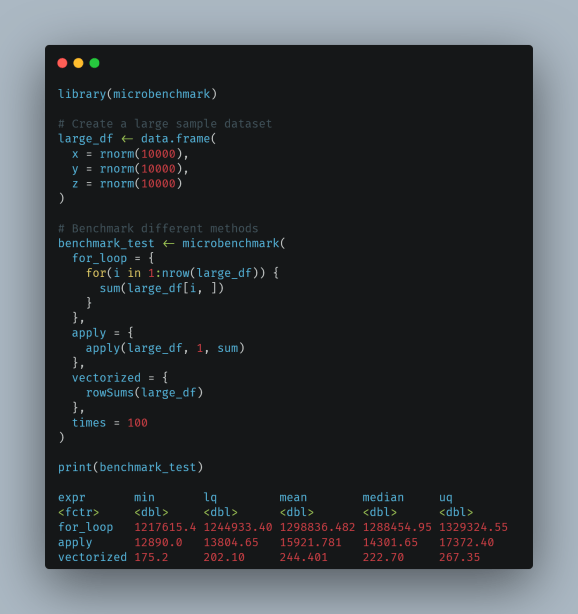
Î1: Care este cea mai rapidă metodă de a repeta peste rânduri din R?
Operațiile vectorizate (cum ar fi rowSums, colMeans) sunt de obicei cele mai rapide, urmate de funcțiile de aplicare. Buclele for tradiționale sunt de obicei cele mai lente. Cu toate acestea, cea mai bună metodă depinde de cazul dumneavoastră specific de utilizare și de structura datelor.
Î2: Pot modifica valorile cadrelor de date în timpul iterației?
Da, dar este important să folosiți metoda adecvată. Când utilizați dplyr, nu uitați să utilizați mutate() pentru modificări. Cu baza R, asigurați-vă că atribuiți corect valori înapoi cadrului de date.
Î3: Cum gestionez erorile în timpul iterației?
Utilizați tryCatch() pentru o gestionare robustă a erorilor. Iată un exemplu:
result <- tryCatch({
# Your iteration code here
}, error = function(e) {
message("Error: ", e$message)
return(NULL)
}, warning = function(w) {
message("Warning: ", w$message)
})
Î4: Există o modalitate eficientă din punct de vedere al memoriei de a repeta peste cadre mari de date?
Da, luați în considerare utilizarea data.table pentru seturi de date mari sau procesați datele în bucăți folosind funcția group_by() a dplyr. De asemenea, evitați creșterea vectorilor în interiorul buclelor.
Î5: Ar trebui să folosesc întotdeauna apply() în loc de buclele for?
Nu neapărat. În timp ce funcțiile apply() sunt adesea mai elegante, buclele for pot fi mai lizibile și mai potrivite pentru operații simple sau atunci când aveți nevoie de un control fin.
Stăpânirea iterației rândurilor în R este esențială pentru manipularea eficientă a datelor. Deși există mai multe abordări disponibile, cheia este alegerea instrumentului potrivit pentru sarcina dvs. specifică. Amintiți-vă aceste puncte cheie: * Vectorizați atunci când este posibil * Folosiți instrumente moderne precum tidyverse pentru un cod mai curat * Luați în considerare performanța pentru seturi mari de date * Implementați o gestionare adecvată a erorilor * Testați diferite abordări pentru cazul dvs. de utilizare specific
Ai găsit acest ghid util? Împărtășește-l cu colegii tăi programatori R! Aveți întrebări sau sfaturi suplimentare? Lasă un comentariu mai jos. Feedbackul dvs. ne ajută să ne îmbunătățim conținutul!
Aceasta completează ghidul nostru cuprinzător despre iterarea pe rânduri în cadrele de date R. Nu uitați să marcați această resursă pentru referințe viitoare și să exersați exemplele pentru a vă consolida abilitățile de programare R.
Codare fericită! 🚀
Vectorized Operations ████████████ Fastest
Apply Functions ████████ Fast
For Loops ████ Slower
Data Size?
├── Small (<1000 rows)
│ ├── Simple Operation → For Loop
│ └── Complex Operation → Apply Family
└── Large (>1000 rows)
├── Vectorizable → Vectorized Operations
└── Non-vectorizable → data.table/dplyr
![]()
Vă puteți conecta cu mine la oricare dintre cele de mai jos:
Canalul Telegram aici: https://t.me/steveondata