(Acest articol a fost publicat pentru prima dată pe Joshua Entrop 👋și cu amabilitate a contribuit la R-bloggeri). (Puteți raporta problema legată de conținutul acestei pagini aici)
Doriți să vă distribuiți conținutul pe R-bloggeri? dați clic aici dacă aveți un blog, sau aici dacă nu aveți.
Cod R
De acum ceva timp, am simțit că am întâlnit mai des termenul M-esitmation când citesc articole despre inferența cauzală. Prin urmare, a venit timpul să învățăm puțin mai multe despre ce este M-estimation. Vara aceasta am avut norocul să susțin un atelier introductiv foarte frumos și util despre estimarea M intitulat ABC-ul estimării M susținut de Paul Zivich, Rachael Ross și Bonnie Shook-Sa. Atelierul a fost susținut ca un curs preconferință la conferința anuală SER din acest an. După cum am înțeles, aceasta nu a fost ultima dată când se va da cursul. Așa că consultați programul de anul viitor al întâlnirii SER, dacă doriți să aflați mai multe. Pot doar să recomand cu căldură acest curs. Ei au scris, de asemenea, un articol introductiv frumos despre estimarea M, care a fost publicat în Jurnalul Internațional de Epidemiologie.
Dar haideți să ne murdărim mâinile și să încercăm să ne scufundăm puțin în ceea ce este vorba despre estimarea M! În această postare pe blog vă voi vorbi despre (1) cum să utilizați estimarea M pentru estimarea unui model Poisson și (2) cum să preziceți probabilitățile de supraviețuire cu intervalele de încredere aferente. Această postare se bazează pe o postare anterioară despre utilizarea estimării cu probabilitate maximă (MLE) pentru estimarea unui model Poisson. Așadar, dacă nu ați citit încă postarea de pe blog, vă recomand să aruncați o privire asupra ei.
Înainte de a începe să aplicăm estimarea M unor date, trebuie să parcurgem o pregătire a datelor și un scurt context teoretic despre estimarea M.
Configurarea datelor
Această postare pe blog va folosi survival::lung set de date, care include informații despre 228 de pacienți diagnosticați cu cancer pulmonar avansat. Ca exemplu, vom arunca o privire asupra diferențelor de sex în supraviețuire la acest grup de pacienți. Dacă doriți să aflați mai multe despre setul de date, puteți arunca o privire la publicația originală. Setul de date original a folosit o codificare 1/2 pentru variabilele binare. Deci, să schimbăm asta la 0/1 pentru continență. Înainte de a începe, trebuie să încărcăm și toate pachetele de care vom avea nevoie pentru această sesiune.
# Prefix --------------------------------------------------------------------------
# Remove all files from ls
rm(list = ls())
# Loading packages
require(survival)
require(rootSolve)
require(dplyr)
require(tibble)
require(data.table)
# Loading dataset -----------------------------------------------------------------
#Reading the example data set lung from the survival package
lung <- as.data.frame(survival::lung)
#Recode dichotomous vairables
lung$female <- ifelse(lung$sex == 2, 1, 0)
lung$status_n <- ifelse(lung$status == 2, 1, 0)
# Define model data for futher use
model_data <- lung(, c("status_n", "time", "female", "age")) |>
rename("d" = status_n,
"t" = time,
"x1" = female,
"x2" = age)
Estimarea M a unui model Poisson obișnuit
În postarea anterioară pe blog, am adaptat un model Poisson folosind vârsta și sexul ca predictori ai supraviețuirii. Ideea acestei postări de blog este să reproducă acea analiză folosind estimarea M în loc de MLE. Înainte de a ne aprofunda în estimarea modelelor noastre, trebuie să parcurgem niște matematici pentru a putea configura ecuația noastră de estimare.
Să presupunem că avem un set de date care include unele date observate 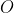 pentru
pentru ![]()
 indivizii. În general, o estimare M poate fi definită ca o estimare
indivizii. În general, o estimare M poate fi definită ca o estimare ![]()
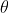 care minimizează funcția noastră de estimare
care minimizează funcția noastră de estimare ![]()
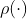 cu privire la
cu privire la ![]() :
:
![]()
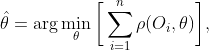
unde ![]() este o funcție a datelor observate și a unui parametru de model. Funcția de estimare este o funcție care leagă parametrul modelului nostru de datele observate. Prin urmare, trebuie mai întâi să definim un model pentru datele observate. În exemplul de față, am dori să folosim un model Poisson pentru a modela funcția de supraviețuire a indivizilor incluși în setul de date exemplu. Rețineți că putem estima și modele cu parametri multipli prin stivuirea funcțiilor lor de estimare împreună, adică trebuie să găsim un set de estimări
este o funcție a datelor observate și a unui parametru de model. Funcția de estimare este o funcție care leagă parametrul modelului nostru de datele observate. Prin urmare, trebuie mai întâi să definim un model pentru datele observate. În exemplul de față, am dori să folosim un model Poisson pentru a modela funcția de supraviețuire a indivizilor incluși în setul de date exemplu. Rețineți că putem estima și modele cu parametri multipli prin stivuirea funcțiilor lor de estimare împreună, adică trebuie să găsim un set de estimări ![]() care minimizează toate funcțiile de estimare. Cu toate acestea, nu putem doar estima parametrii aceluiași model, dar putem, de asemenea, să stivuim diferite modele împreună folosind estimarea M și să le estimăm simultan. De exemplu, dacă dorim să estimăm un model Poisson ponderat IPW, ambii trebuie să ne estimăm modelul structural și modelul de expunere pentru estimarea ponderilor.
care minimizează toate funcțiile de estimare. Cu toate acestea, nu putem doar estima parametrii aceluiași model, dar putem, de asemenea, să stivuim diferite modele împreună folosind estimarea M și să le estimăm simultan. De exemplu, dacă dorim să estimăm un model Poisson ponderat IPW, ambii trebuie să ne estimăm modelul structural și modelul de expunere pentru estimarea ponderilor.
Dar, pentru a începe, să estimăm doar un model Poisson simplu. Ca prim pas trebuie să definim funcția de log-probabilitate. Funcția de supraviețuire pentru un model Poisson comun cu o funcție de hazard constantă poate fi definită ca
![]()
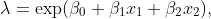
unde ![]()
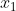 este o variabilă indicator pentru sexul pacientului (0=masculin/1=feminin) şi
este o variabilă indicator pentru sexul pacientului (0=masculin/1=feminin) şi ![]()
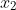 este o vârstă controversată la diagnosticarea cancerului pulmonar. Pe baza funcției de supraviețuire și a funcției de hazard, putem defini funcția de probabilitate a modelului nostru. Probabilitatea generală pentru datele de supraviețuire cenzurate corect este definită astfel:
este o vârstă controversată la diagnosticarea cancerului pulmonar. Pe baza funcției de supraviețuire și a funcției de hazard, putem defini funcția de probabilitate a modelului nostru. Probabilitatea generală pentru datele de supraviețuire cenzurate corect este definită astfel:
![]()
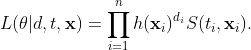
Luarea jurnalului ne oferă funcția de probabilitate a jurnalului indicată ![]()
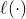 :
:
![]()

Dacă acum conectăm funcția noastră de hazard și supraviețuire la această funcție, obținem funcția de log-probabilitate pentru modelul nostru Poisson.
![]()
%20t_i%0A)
Pentru a estima modelul nostru folosind estimarea M, trebuie să obținem primele derivate parțiale ale funcției noastre de probabilitate log în ceea ce privește parametrii funcției ![]()
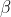 pentru că ne interesează să găsim o estimare
pentru că ne interesează să găsim o estimare ![]() care maximizează funcția noastră de estimare și maximul unei funcții poate fi găsit prin găsirea rădăcinii primei sale derivate. Folosind regula lanțului obținem următoarea formă generală a derivatei parțiale a funcției noastre de probabilitate log.
care maximizează funcția noastră de estimare și maximul unei funcții poate fi găsit prin găsirea rădăcinii primei sale derivate. Folosind regula lanțului obținem următoarea formă generală a derivatei parțiale a funcției noastre de probabilitate log.
![]()
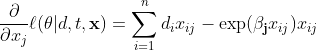
Cu toate acestea, pentru ecuația noastră de estimare, trebuie să obținem jacobianul (![]()
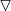 ) pentru log-probabilitatea noastră completă, adică un vector de derivate parțiale în ceea ce privește toți parametrii probabilității. O formă generală a jacobianului pentru funcția de probabilitate a unui model Poisson cu
) pentru log-probabilitatea noastră completă, adică un vector de derivate parțiale în ceea ce privește toți parametrii probabilității. O formă generală a jacobianului pentru funcția de probabilitate a unui model Poisson cu ![]()
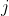 parametrii pot fi definiți ca:
parametrii pot fi definiți ca:
![]()

Acum, având toate derivatele parțiale în loc, putem defini funcția noastră de estimare, care este partea interioară a ecuației noastre de estimare, adică, ![]()
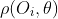 .
.
# Define estimating functions
ef1 <- (O, theta) O$d * 1 - exp(cbind(1, O$x1, O$x2) %*% theta) * O$t * 1
ef2 <- (O, theta) O$d * O$x1 - exp(cbind(1, O$x1, O$x2) %*% theta) * O$t * O$x1
ef3 <- (O, theta) O$d * O$x2 - exp(cbind(1, O$x1, O$x2) %*% theta) * O$t * O$x2
# Combine all estimating function into one function
estimating_function <- function(O, theta){
cbind(ef1(O, theta),
ef2(O, theta),
ef3(O, theta))
}
În continuare, trebuie să definim ecuația de estimare, care este o parte din funcția de estimare pentru toate observațiile ![]()
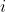 pentru un vector de parametri
pentru un vector de parametri ![]() :
:
![]()

estimating_equation <- function(par){
value = estimating_function(O = model_data,
theta = par)
colSums(value)
}
În cele din urmă, trebuie să găsim rădăcina ecuației noastre de estimare în ceea ce privește ![]() .
.
m_estimate <- rootSolve::multiroot(f = estimating_equation,
start = c(0,0,0))
data.frame(label = paste("beta", 0:2),
est = exp(m_estimate$root))
label est 1 beta 0 0.001069455 2 beta 1 0.618205147 3 beta 2 1.015741321
Obținerea intervalelor de încredere pentru estimările noastre
Iată-ne! Acum am ajustat modelul nostru de regresie Poisson folosind estimarea M. Pe baza rezultatelor, putem observa că femeile au o rată de risc de deces cu 39% mai mică în comparație cu bărbații și că rata de risc de deces crește cu 1,6% pentru fiecare creștere a vârstei de un an. Cu toate acestea, cel mai probabil am fi, de asemenea, interesați să obținem niște intervale de încredere în jurul estimărilor noastre punctuale, astfel încât să putem evalua incertitudinea estimărilor noastre. Pentru aceasta putem estima eroarea standard și intervalele de încredere ulterioare pentru estimările noastre utilizând estimatorul Sandwich Variance:
![]()
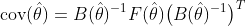
unde ![]()
 şi
şi ![]()
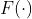 este pâinea și, respectiv, matricea de umplutură. Să începem prin a coace pâinea. Matricea pâinii poate fi estimată ca medie a derivatelor parțiale negative ale funcției noastre de estimare pentru toate observațiile:
este pâinea și, respectiv, matricea de umplutură. Să începem prin a coace pâinea. Matricea pâinii poate fi estimată ca medie a derivatelor parțiale negative ale funcției noastre de estimare pentru toate observațiile:
![]()
%20%5Cbigg%5D%0A)
Să obținem derivatele parțiale ale fiecăreia dintre cele trei funcții de estimare. Pentru aceasta, vom folosi procedura de aproximare numerică implementată în numDeriv::jocabian() funcţie.
# Sum of partial derivatives of the estimating functions 1 to 3
ef1_prime <- numDeriv::jacobian(func = ef1,
x = m_estimate$root,
O = model_data) |>
colSums()
ef2_prime <- numDeriv::jacobian(func = ef2,
x = m_estimate$root,
O = model_data) |>
colSums()
ef3_prime <- numDeriv::jacobian(func = ef3,
x = m_estimate$root,
O = model_data) |>
colSums()
Acum ne putem compune matricea de pâine pe baza derivatelor parțiale.
# Combine partial derivatives to bread matrix
bread <- matrix(c(-ef1_prime,
-ef2_prime,
-ef3_prime),
nrow = 3) / nrow(model_data)
Odată ce avem pâinea, putem continua cu umplutura, care este media produsului punctual al funcției noastre de estimare pentru toate observațiile:
![]()
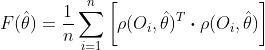
value_ef <- estimating_function(m_estimate$root,
O = model_data)
filling <- (t(value_ef) %*% value_ef) / nrow(lung)
Acum că avem pâinea și umplutura, putem obține o estimare a varianței Sandwich și, ulterior, a intervalului de încredere de tip Wald:
![]()
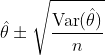
covar <- solve(bread) %*% filling %*% t(solve(bread))
se <- sqrt(diag(covar) / nrow(lung))
data.frame(label = paste("beta", 0:2),
est = exp(m_estimate$root),
lci = exp(m_estimate$root - 1.96 * se),
uci = exp(m_estimate$root + 1.96 * se))
label est lci uci 1 beta 0 0.001069455 0.0003885294 0.002943749 2 beta 1 0.618205147 0.4710643248 0.811306616 3 beta 2 1.015741321 0.9997622104 1.031975823
Obținerea intervalelor de încredere pentru funcția de supraviețuire
Cu toate acestea, destul de des, cineva nu este interesat doar de estimările în sine, ci și de transformarea acestor estimări, de exemplu, funcția de supraviețuire:
![]()
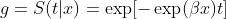
Există două moduri de a estima funcția de supraviețuire în această situație. Prima opțiune este de a folosi metoda delta pentru a obține intervale de încredere în jurul estimărilor noastre transformate, adică, probabilitatea de a supraviețui până la un anumit punct de timp. Cealaltă opțiune este estimarea cantității de dobândă în cadrul procedurii de estimare M. Putem adăuga probabilitatea de supraviețuire la diferite momente de timp la funcțiile de estimare. Cu toate acestea, de obicei aș prefera prima opțiune, deoarece îmi place să mă potrivesc mai întâi pe modelul principal și apoi, într-un al doilea pas, să obțin cantități diferite care mă interesează în funcție de model. Deci, să începem cu obținerea intervalului de încredere pentru funcția de supraviețuire folosind metoda delta.
De asemenea, putem folosi estimatorul de varianță Sandwich pentru estimarea varianței funcției de supraviețuire. Pentru aceasta avem nevoie de derivata parțială a funcției noastre de transformare ![]()
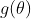 care este în cazul nostru funcția de supraviețuire, în ceea ce privește estimările noastre
care este în cazul nostru funcția de supraviețuire, în ceea ce privește estimările noastre ![]()
 . Estimatorul de varianță este apoi definit ca
. Estimatorul de varianță este apoi definit ca
![]()
%20%5Cboldsymbol%7B%5Ccdot%7D%20B(%5Ctheta)%5E%7B-1%7D%20%5Cboldsymbol%7B%5Ccdot%7D%20g'(%5Ctheta)%0A)
cu derivata funcţiei de supravieţuire fiind
![]()
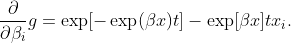
Pe baza acestor funcții, putem scrie propria noastră funcție a metodei delta mică în R.
# Create own delta method function
delta_method <- function(x, t,bread, g, gprime){
g <- do.call(g, list(x = x, t = t))
gprime <- vapply(gprime, do.call,
FUN.VALUE = double(1),
args = list(x = x, t = t))
cov <- gprime %*% solve(bread) %*% gprime
se <- sqrt(diag(cov) / nrow(lung))
data.frame(est = g,
lci = g - 1.96 * se,
uci = g + 1.96 * se)
}
Folosind această funcție generală, putem estima, de exemplu, un interval de încredere pentru probabilitatea de a supraviețui mai mult de 1 000 de zile la bărbați și cu cancer pulmonar care au trecut 60 de ani la data diagnosticării.
# Get estimates (theta hat)
est <- m_estimate$root
# Use delta method function to get the survival probability of females
females <- delta_method(
x = c(1, 1, 60),
t = 1000,
bread = bread,
g = (x, t) exp(-exp(x %*% est) * t),
gprime = list((x, t) exp(-exp(x %*% est) * t) * -exp(x %*% est) * x((1)) * t,
(x, t) exp(-exp(x %*% est) * t) * -exp(x %*% est) * x((2)) * t,
(x, t) exp(-exp(x %*% est) * t) * -exp(x %*% est) * x((3)) * t)
)
# Use delta method function to get the survival probability of males
males <- delta_method(
x = c(1, 0, 60),
t = 1000,
bread = bread,
g = (x, t) exp(-exp(x %*% est) * t),
gprime = list((x, t) exp(-exp(x %*% est) * t) * -exp(x %*% est) * x((1)) * t,
(x, t) exp(-exp(x %*% est) * t) * -exp(x %*% est) * x((2)) * t,
(x, t) exp(-exp(x %*% est) * t) * -exp(x %*% est) * x((3)) * t)
)
# Output results
rbind(cbind(sex = "Females", females),
cbind(sex = "Males" , males))
sex est lci uci 1 Females 0.18495380 0.09981281 0.2700948 2 Males 0.06522466 0.03023816 0.1002111
Cu toate acestea, cel mai probabil, nu vom fi interesați doar să obținem o singură probabilitate de supraviețuire, ci mai degrabă o funcție de supraviețuire cu intervale de încredere însoțitoare. Acest lucru se poate face cu ușurință și cu o buclă peste argumentul de timp în funcția noastră metoda delta.
# Creating the data for the plot --------------------------------------------------
# Looping over time
survival <- lapply(seq(0, 1000, length = 300), (i){
delta_method(
x = c(1, 1, 60),
t = i,
bread = bread,
g = (x, t) exp(-exp(x %*% est) * t),
gprime = list((x, t) exp(-exp(x %*% est) * t) * -exp(x %*% est) * x((1)) * t,
(x, t) exp(-exp(x %*% est) * t) * -exp(x %*% est) * x((2)) * t,
(x, t) exp(-exp(x %*% est) * t) * -exp(x %*% est) * x((3)) * t)
)
# Combining the output in a single data.frame
}) |> rbindlist()
# Adding a time variable to the data.frame
survival$t <- seq(0, 1000, length = 300)
# Plotting ------------------------------------------------------------------------
# Open new plot device
plot.new()
# Define plot windows
plot.window(xlim = c(0, 1000),
ylim = c(0, 1))
axis(1)
axis(2)
# Add CIs
polygon(c(survival$t, rev(survival$t)),
c(survival$lci, rev(survival$uci)),
border = NA,
col = "grey")
# Add point esitmates
lines(survival$t,
survival$est)
# Annotate plot
title(x = "Days After Lung Cancer Diagnosis",
y = "Survival Probability")
title(main = "Survival of Female Lungcancer Patients Aged 60 at Diagnosis",
adj = 0)
legend(0, 0.2,
legend = "95% CI",
fill = "gray")
![]()
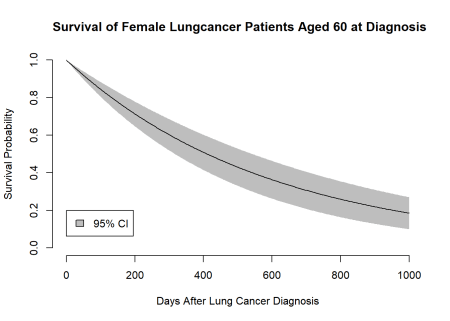
Începem! Acum am reușit să trasăm o funcție de supraviețuire împreună cu intervalele de încredere aferente utilizând estimarea M. S-ar putea să vă întrebați acum de ce am făcut toate acestea, dacă am fi putut obține același rezultat folosind standardul nostru glm() funcţie? Evident, am fi putut obține acest rezultat cu o metodă standard bazată pe probabilitate, dar cred că acesta este un bun punct de plecare pentru a explora mai profund estimarea M. Principalul avantaj al estimării M este că se generalizează frumos la stivuirea unui număr întreg de modele care depind unul de celălalt într-o ecuație de estimare. Acest lucru este util dacă, de exemplu, dorim să folosim ponderi de probabilitate inversă. Folosind M-estimation putem potrivi modelul nostru principal de interes și modelul pentru obținerea ponderilor în același timp. Prin această abordare, erorile noastre standard vor fi, de asemenea, ajustate automat pentru incertitudinea care decurge din modelul pe care îl folosim pentru estimarea ponderilor noastre. Cred că este destul de frumos! Cu toate acestea, acesta va fi subiectul unei postări ulterioare.