(Acest articol a fost publicat pentru prima dată pe r – bensstatsși cu amabilitate a contribuit la R-bloggeri). (Puteți raporta problema legată de conținutul acestei pagini aici)
Doriți să vă distribuiți conținutul pe R-bloggeri? dați clic aici dacă aveți un blog, sau aici dacă nu aveți.

Introducere
Am avut norocul să dezvolt un algoritm de detectare a comunității cu Tyler Pittman sub supravegherea dr. Wei Xu și care s-a dovedit că oferă o identificare „mai descriptivă” a comunității în anumite setări în comparație cu alți algoritmi – cum ar fi algoritmii Girvan-Newman și Louvain. . Pentru ca algoritmul să fie ușor disponibil pentru alți utilizatori, a fost creat pachetul R {ig.degree.betweenness}. Dacă doriți să aflați despre setarea pentru care a fost dezvoltat inițial algoritmul, consultați preprintul arXiv aici.
Pachetul {ig.degree.betweenness} oferă o implementare a algoritmului de detectare a comunității „Smith-Pittman” pentru utilizatorii igraph din R. Poate fi instalat direct din CRAN rulând:
install.packages("ig.degree.betweenness")
# Install the devtools package if you haven't installed it
# install.packages("devtools")
devtools::install_github("benyamindsmith/ig.degree.betweenness")
Algoritmul Smith-Pittman
Algoritmul poate fi considerat ca o extensie a algoritmului Girvan-Newman, care ia în considerare atât gradul de centralitate – adică numărul de conexiuni deținute de fiecare nod individual din rețea, cât și marginea dintre margini – adică numărul de căi cele mai scurte care trec prin fiecare. marginea individuală în rețea.
Pașii pentru algoritm sunt:
- Identificați nodul cu cel mai înalt grad de centralitate din rețea (cel mai popular nod)
- Selectați subgraful nodului cu cel mai înalt grad de centralitate. Eliminați marginea care are cea mai mare margine calculată (la nivelul întregii rețele) din subgraf.
- Recalculați gradul de centralitate pentru toate nodurile din rețea și intervalul pentru marginea rămasă din rețea.
- Repetați de la pasul 2.
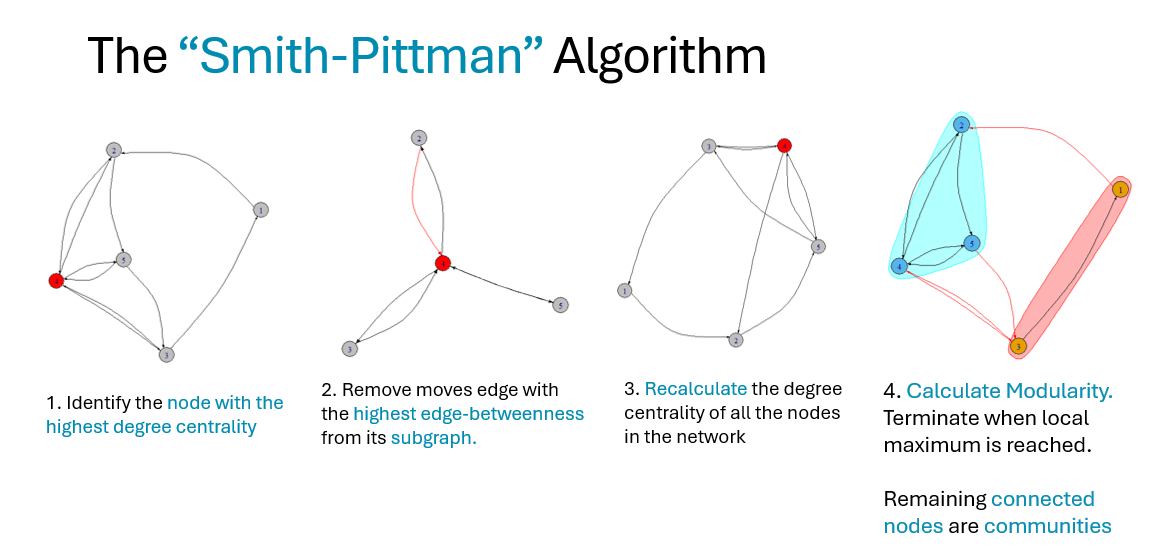
Din punct de vedere conceptual, acest algoritm (similar cu Girvan-Newman și Louvain) poate fi specificat să se termine odată ce a fost identificat un număr predeterminat de comunități (pe baza nodurilor conectate rămase). Cu toate acestea, intenția utilizării acestui algoritm este menită să fie utilizată într-un cadru nesupravegheat, de maximizare a modularității, în care gruparea nodurilor este decisă în funcție de puterea clusterelor conectate.
Aplicații ale algoritmului Smith-Pittman
Algoritmul Smith-Pittman prosperă în anumite setări în care alte metode eșuează. În special, algoritmul Smith Pittman pare să se descurce bine în identificarea comunităților de valoare descriptivă în setările în care există o „ierarhie-popularitate” puternică în ceea ce privește nodurile din rețea. Următoarele sunt două exemple în care Smith-Pittman pare să fie mai bine în ceea ce privește identificarea comunităților descriptive decât algoritmii de detectare a comunității Girvan-Newman și Louvain.
Clubul de Karate al lui Zachary
Setul de date Zachary’s Karate Club a devenit un set de date clasic folosit pentru studierea analizei rețelelor sociale și a detectării comunității. Divizarea dintre membrii din club este cunoscută și servește ca un bun punct de plecare pentru a afla despre și a aplica analiza rețelelor sociale. Datele sunt ușor disponibile prin pachetul {igraphdata}.
Rețeaua inițială poate fi reprezentată cu următorul cod R:
# Install relevant libraries for the entire analysis
library(igraph)
library(igraphdata)
library(ig.degree.betweenness)
# Setting seed for visual reproducibility
set.seed(5250)
par(mar=c(0,0,0,0)+2)
data("karate")
plot(karate, main ="Zachary's Karate Club")

În contextul detectării comunității, obiectul de interes este de a vedea dacă divizarea membrilor din club ar putea fi identificată pe baza relațiilor dintre membrii din rețea. Pentru compararea algoritmilor de detectare a comunității, se folosește următorul cod:
# Girvan-Newman communities gn_karate <- karate |> igraph::cluster_edge_betweenness() # Louvain communities louvain_karate <- karate |> igraph::cluster_louvain() # Smith-Pittman Communities sp_karate <- karate |> ig.degree.betweenness::cluster_degree_betweenness() #Plotting all 3 visuals par(mfrow= c(1,3),mar=c(0,0,0,0)+2) set.seed(5250) plot(gn_karate, karate, main = "Girvan-Newman" ) set.seed(5250) plot( louvain_karate, karate, main = "Louvain" ) set.seed(5250) plot( sp_karate, karate, main = "Smith-Pittman" )
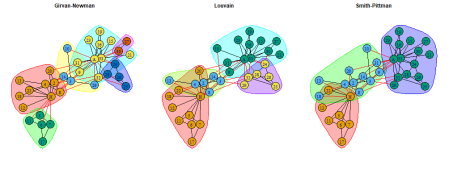
Când sunt aplicați într-un cadru nesupravegheat, algoritmii Girvan-Newman și Louvain identifică comunități de noduri care optimizează modularitatea în funcție de abordările lor. Cu toate acestea, comunitățile identificate nu par să identifice o posibilă divizare a grupului care este informativă sau interpretativă din punct de vedere contextual. Algoritmul Smith-Pittman identifică 3 comunități care pot fi înțelese ca indivizi care s-ar asocia cu John A. sau Mr. Hi și un grup incert.
Pentru a justifica în continuare rațiunea lui Smith-Pittman, rețeaua cu comunitățile identificate și nodurile redimensionate în funcție de numărul de conexiuni deținute (gradul de centralitate) poate fi vizualizată cu următorul cod:
set.seed(5250)
VS <- igraph::degree(karate)
plot(
sp_karate,
karate,
vertex.size=VS,
main = "Smith-Pittman Communities with Node Resizing"
)
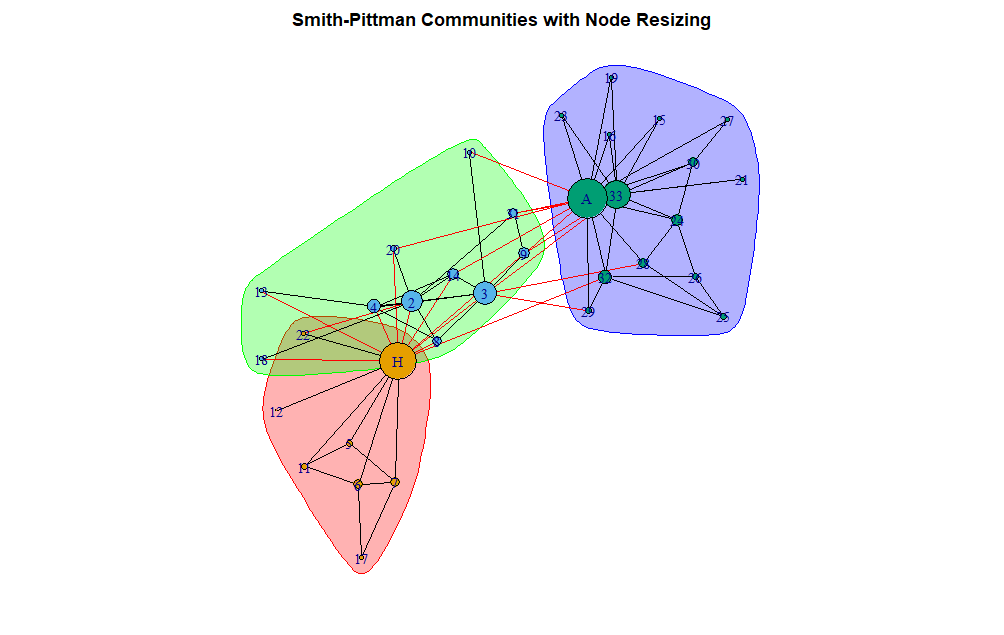
Acest vizual oferă câteva dovezi pentru rațiunea modului în care algoritmul a împărțit indivizii din club.
TidyTuesday – set de date „Monster Movies”.
Setul de date „Monster Movies”, pus la dispoziție de proiectul TidyTuesday prezintă un exemplu interesant de aplicare a SNA și a algoritmului Smith-Pitman la interacțiunea dintre genuri în filmele cu titlul „monstruți”. Pentru a reprezenta o rețea „simplificată” cu dimensiunile nodurilor corespunzătoare numărului de conexiuni, se folosește următorul cod:
# Install relevant libraries
# pkgs <- c("dplyr","tibble","tidyr","tidygraph",
# "igraph","ig.degree.betweenness")
# install.packages(pkgs)
# Load data
tuesdata <- tidytuesdayR::tt_load(2024, week = 44)
monster_movie_genres <- tuesdata$monster_movie_genres
# Prepare data for adjacency matrix
dummy_matrix <- monster_movie_genres |>
dplyr::mutate(value = 1) |>
tidyr::pivot_wider(
id_cols = tconst,
names_from = genres,
values_from = value,
values_fill = 0
) |>
dplyr::select(-tconst) |>
as.matrix.data.frame()
# Construct adjacency matrix
genre_adj_matrix <- t(dummy_matrix) %*% dummy_matrix
# Setting self loops to zero
diag(genre_adj_matrix) <- 0
# Construct the graph
movie_graph <- genre_adj_matrix |>
as.data.frame() |>
tibble::rownames_to_column() |>
tidyr::pivot_longer(cols = Comedy:War) |>
dplyr::rename(c(from = rowname, to = name)) |>
dplyr::rowwise() |>
dplyr::mutate(combo = paste0(sort(c(from, to)), collapse = ",")) |>
dplyr::arrange(combo) |>
dplyr::distinct(combo, .keep_all = TRUE) |>
dplyr::select(-combo) |>
tidyr::uncount(value) |>
tidygraph::as_tbl_graph()
# Resize nodes based on node degree
VS <- igraph::degree(movie_graph) * 0.1
ig.degree.betweenness::plot_simplified_edgeplot(
movie_graph,
vertex.size = VS,
edge.arrow.size = 0.001
)
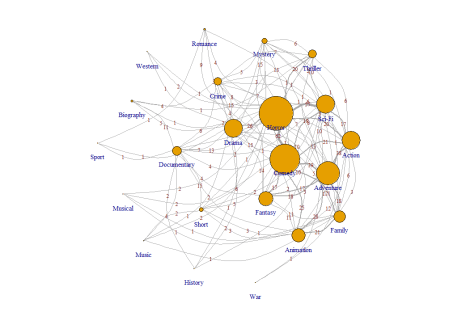
Grosimea marginilor și numerele adnotate corespund numărului de margini partajate între genurile enumerate. Pentru trasarea grupurilor de gen în rețea, așa cum sunt preformate de (a)-Girvan-Newman, (b)-Louvain și (c)-Smith-Pittman, se folosește următorul cod:
# Cluster Nodes
gn_cluster <- movie_graph |>
igraph::as.undirected() |>
igraph::cluster_edge_betweenness()
louvain_cluster <- movie_graph |>
igraph::as.undirected() |>
igraph::cluster_louvain()
sp_cluster <- movie_graph |>
igraph::as.undirected() |>
ig.degree.betweenness::cluster_degree_betweenness()
# Figure 5
par(mfrow = c(1, 3), mar = c(0, 0, 0, 0) + 1)
ig.degree.betweenness::plot_simplified_edgeplot(
movie_graph,
gn_cluster,
main = "(a)",
vertex.size = VS,
edge.arrow.size = 0.001
)
ig.degree.betweenness::plot_simplified_edgeplot(
movie_graph,
louvain_cluster,
main = "(b)",
vertex.size = VS,
edge.arrow.size = 0.001
)
ig.degree.betweenness::plot_simplified_edgeplot(
movie_graph,
sp_cluster,
main = "(c)",
vertex.size = VS,
edge.arrow.size = 0.001
)
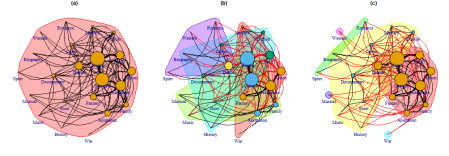
Girvan Newman nu reușește să identifice nicio comunitate din rețea (gruparea tuturor genurilor într-un singur grup nu este chiar identificarea comunității). Louvain s-ar putea să ne spună ceva în ceea ce privește puterea grupării, dar nu vorbește neapărat despre realitatea interacțiunilor genurilor de film „monstruți”. Gruparea Smith-Pittman spune cea mai bună poveste, genurile populare formând grupul de lucru principal, urmate de subgrupuri mai mici mai ambivalente și noduri aberante.
Limitări
Algoritmul Smith-Pittman se preformă cel mai bine într-un cadru în care există un număr mare de conexiuni pentru numărul de noduri din rețea și există o diversitate în gradul de centralitate între noduri. Pentru o setare comic proastă poate fi văzută dintr-o captură de ecran pe care am avut-o dintr-o conversație pe Discord:
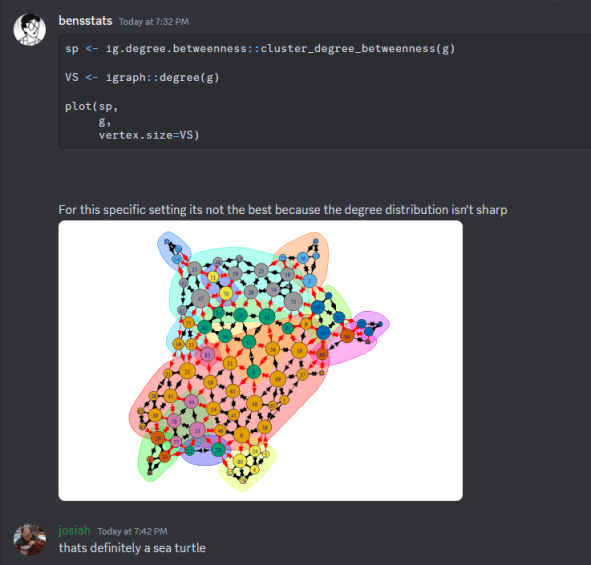
Acestea fiind spuse, nu există un model specific care să descrie exact ce este o „comunitate”. Deci, acolo unde Smith-Pittman „eșuează”, un alt algoritm de detectare a comunității ar putea fi mai justificat.
Concluzii
Le mulțumesc colaboratorilor mei pentru că au ajutat la dezvoltarea acestei metode și le mulțumesc tuturor celor care și-au făcut timp să verifice metodologia. Dacă l-ați folosit sau intenționați să îl utilizați, vă rog să-mi spuneți!
![]()

Doriți să vedeți mai mult din conținutul meu?
Asigurați-vă că vă abonați și nu pierdeți nicio actualizare!