Când proiectați experimente, trebuie să știți câți participanți este nevoie pentru a obține rezultate informative. Dar ce face rezultatele informative? Mai simplu spus: o estimare a efectului precis, adică o estimare care este imparțială și are un interval de încredere restrâns. Proiectarea randomizată și măsurarea atentă ar trebui să se asigure că estimarea efectului dvs. este imparțială. Dar cum poți fi încrezător că intervalul de încredere al estimării tale este destul de restrâns?
Să ne uităm la un exemplu artificial. Presupunem că proiectați un experiment care studiază dacă un anumit tratament informațional face ca oamenii să fie mai susceptibili să investească într -o anumită firmă. Măsurați această probabilitate de investiții ca preferință declarată pe o scară discretă de la 0 la 100 %. Să simulăm unele date de bază, ceea ce înseamnă datele pentru participanții care nu primesc tratamentul informațional.
library(tidyverse)
library(truncnorm)
set.seed(42)
sim_data <- function(n = 100, mean = 50, sd = 20) {
y <- rtruncnorm(n, 0, 100, mean, sd)
tibble(
y = round(y)
)
}
baseline <- sim_data()
ggplot(baseline, aes(x = y)) + geom_histogram(bins = 20) + theme_minimal()
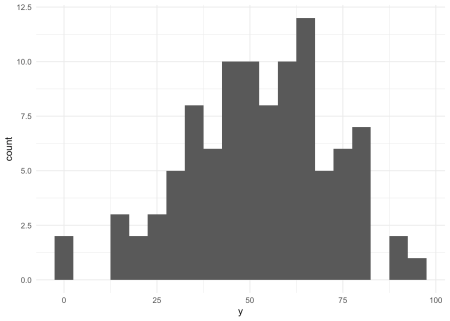
După cum puteți vedea, a trebuit să facem asumuri despre dimensiunea eșantionului (100), distribuția (normal trunchiat), media sa (50) și abaterea standard (20) pentru a simula datele. Acestea sunt presupuneri cruciale pentru tot ce urmează. Histograma rezultată arată că avem o variație destul de mare a probabilității noastre de investiții.
Pe baza distribuției noastre asumate a variabilei noastre dependente sub niciun tratament, trebuie să ne formulăm presupunerile despre o dimensiune a efectului probabil pentru tratamentul informațional. Adesea, dimensiunile efectului sunt exprimate în % abatere standard, etichetată și ca Cohen’s-D. Începem cu așteptarea că dimensiunea efectului nostru preconizat este de 10, ceea ce înseamnă o valoare Cohen’s-D de 0,5. Un astfel de efect este denumit în mod tradițional un „efect de dimensiuni medii” (mic (d = 0,2), mediu (d = 0,5) și mare (d> = 0,8)). Să simulăm eșantionul tratat și să trasăm un vizual.
treated <- sim_data(mean = 60) smp <- bind_rows( baseline %>% mutate(tment = FALSE) %>% select(tment, y), treated %>% mutate(tment = TRUE) %>% select(tment, y) ) ggplot(smp, aes(x = tment, y = y)) + geom_boxplot() + theme_minimal()
![]()
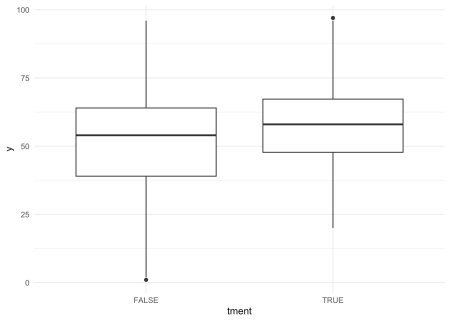
Pe baza boxplot, poate doriți să ghiciți că există un efect de tratament și exact așa a definit odată Cohen un efect „mediu”. Ar trebui să fie „vizibil pentru ochiul liber al unui observator atent”. Dar este semnificativ în ceea ce privește un test T convenial?
tt <- t.test(y ~ !tment, data = smp) print(tt) ## ## Welch Two Sample t-test ## ## data: y by !tment ## t = 1.8965, df = 195.86, p-value = 0.05936 ## alternative hypothesis: true difference in means between group FALSE and group TRUE is not equal to 0 ## 95 percent confidence interval: ## -0.1970289 10.0770289 ## sample estimates: ## mean in group FALSE mean in group TRUE ## 57.16 52.22
Doar marginal. Și acest lucru ne readuce la subiectul unor intervale de încredere restrânse și putere. Pentru testul de mai sus, intervalul de încredere variază de la -0,2 la 10.08. Presupunând că suntem interesați mai ales să învățăm dacă efectul nostru este diferit de zero la nivel convențional de 95%, atunci acest interval de încredere este doar puțin până la larg (include zero).
Dar acest lucru ar putea fi doar un ghinion care rezultă din traseul de date simulat, nu? Puterea pune conceptual întrebarea cât de probabil este că am găsi un rezultat semnificativ al testului, având în vedere proiectarea testului nostru și ipotezele despre procesul de generare a datelor, așa cum s -a prezentat mai sus. Putem obține puterea pentru experimentul nostru fictiv, rulând o simulare Monte Carlo pe setarea noastră. Nu este atât de greu de făcut:
sim_run <- function(effect_size = 0.5, cell_size = 100, mean = 50, sd = 20) {
df <- bind_rows(
sim_data(n = cell_size, mean = mean, sd = sd) %>%
mutate(tment = FALSE) %>% select(tment, y),
sim_data(n = cell_size, mean = mean + effect_size*sd, sd = sd) %>%
mutate(tment = TRUE) %>% select(tment, y)
)
tt <- t.test(y ~ !tment, data = df)
tibble(
effect_size = effect_size,
cell_size = cell_size,
mean = mean,
sd = sd,
t.stat = tt$statistic,
p.value = tt$p.value,
est = unname(tt$estimate(1) - tt$estimate(2)),
lb = unname(tt$conf.int(1)),
ub = unname(tt$conf.int(2))
)
}
sim_runs <- bind_rows(replicate(1000, sim_run(), simplify = FALSE))
Pe baza acestei simulări, acum putem complota o distribuție a estimărilor noastre de 1.000 de efect și, de asemenea, deducem cât de des este strict pozitiv intervalul lor de încredere, ceea ce înseamnă cât de des putem respinge ipoteza nulă fără efect.
ggplot(sim_runs, aes(x = est)) + geom_density() + theme_minimal()
![]()
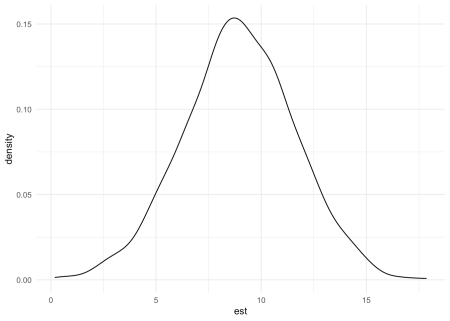
pwr <- mean(sim_runs$lb > 0) pwr ## (1) 0.915
Deci, în 91,5% din cazurile noastre simulate, estimarea efectului a fost semnificativ pozitivă la un nivel de semnificație pe două fețe de 95%. În mod convențional, experimentaliștii încearcă să obțină o putere de cel puțin 80%. Acest lucru implică faptul că, cu dimensiuni de celule de 100 de participanți, ar trebui să fim confortabil cu putere mare pentru a detecta o dimensiune a efectului mediu.
Acum: Cum s -ar schimba puterea atunci când schimbăm parametrii asumați, de exemplu celula sau dimensiunea efectului? Pentru a evalua rapid acest lucru, se poate utiliza funcții de putere ale statisticilor de testare subiacente. Aceste funcții se bazează pe presupuneri care ar putea diferi de cele pe care le -am folosit în procesul nostru de generare a datelor simulate. De exemplu, modelăm o variabilă dependentă care este discretă și bazată pe o distribuție normală trunchiată, în timp ce funcția de putere pentru testele t cu două probe presupune că datele vor fi distribuite în mod normal. Să comparăm estimarea puterii bazate pe funcții pentru dimensiunea efectului nostru cu estimarea puterii derivate din simularea noastră Monte Carlo.
library(pwr) pwr.t.test(n = 100, d = 0.5, sig.level = .05) ## ## Two-sample t test power calculation ## ## n = 100 ## d = 0.5 ## sig.level = 0.05 ## power = 0.9404272 ## alternative = two.sided ## ## NOTE: n is number in *each* group
Acest lucru este rezonabil de aproape, dar puțin mai mare decât estimarea puterii de simulare de 91,5%. O caracteristică foarte convenabilă a pwr Funcțiile din R este că vor calcula întotdeauna parametrul lipsă (puterea în cazul nostru de mai sus). De exemplu, pentru a deduce dimensiunea celulei de care aveți nevoie pentru a atinge o putere de 80%:
pwr.t.test(power = 0.8, d = 0.5, sig.level = .05) ## ## Two-sample t test power calculation ## ## n = 63.76561 ## d = 0.5 ## sig.level = 0.05 ## power = 0.8 ## alternative = two.sided ## ## NOTE: n is number in *each* group
Am avea nevoie de 64 de persoane pe celulă. Să vedem cum se schimbă estimarea puterii noastre bazate pe funcții atunci când schimbăm dimensiunea efectului.
my_power_fct <- function(effect_size = 0.5, cell_size = 100) {
rv <- pwr.t.test(n = cell_size, d = effect_size, sig.level = .05)
tibble(
effect_size = effect_size,
cell_size = cell_size,
power = rv$power
)
}
df <- bind_rows(lapply(seq(0.1, 0.8, by = 0.1), my_power_fct))
ggplot(df, aes(x = effect_size, y = power)) +
geom_hline(yintercept = 0.8, lty = 2, color = "red") +
geom_line() + geom_point() + theme_minimal()
![]()
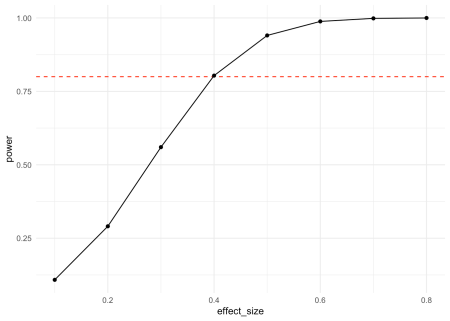
Puteți deduce din această curbă de putere a mărimii efectului, cu o dimensiune a celulelor de 100 de participanți și sub ipoteze de normalitate, unul este capabil să detecteze în mod rezonabil în mod rezonabil o dimensiune a efectului de aproximativ 0,4 abateri standard.
O altă curbă informativă de putere este cea care complotează puterea în raport cu dimensiunea celulelor.
df <- bind_rows( lapply(seq(10, 120, by = 10), function(x) my_power_fct(cell_size = x)) ) ggplot(df, aes(x = cell_size, y = power)) + geom_hline(yintercept = 0.8, lty = 2, color = "red") + geom_line() + geom_point() + theme_minimal()
![]()
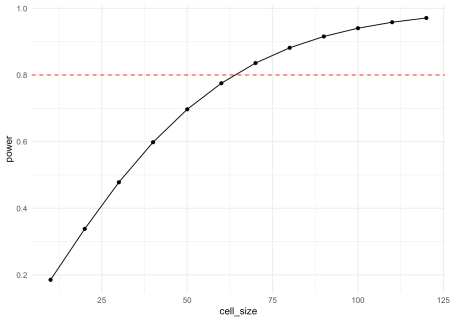
Și, dacă doriți să creșteți încărcarea cognitivă a vizualului dvs., le puteți combina pe cele două.
df <- expand_grid(
cell_size = seq(10, 120, by = 10),
effect_size = c(0.2, 0.5, 0.8)
) %>%
mutate(
power = pmap_dbl(
list(n = cell_size, d = effect_size),
function(n, d) pwr.t.test(n = n, d = d, sig.level = .05)$power
)
)
ggplot(df, aes(x = cell_size, y = power, color = factor(effect_size))) +
geom_hline(yintercept = 0.8, lty = 2, color = "red") +
geom_line() + geom_point() +
labs(color = "effect_size") +
theme_minimal()
![]()
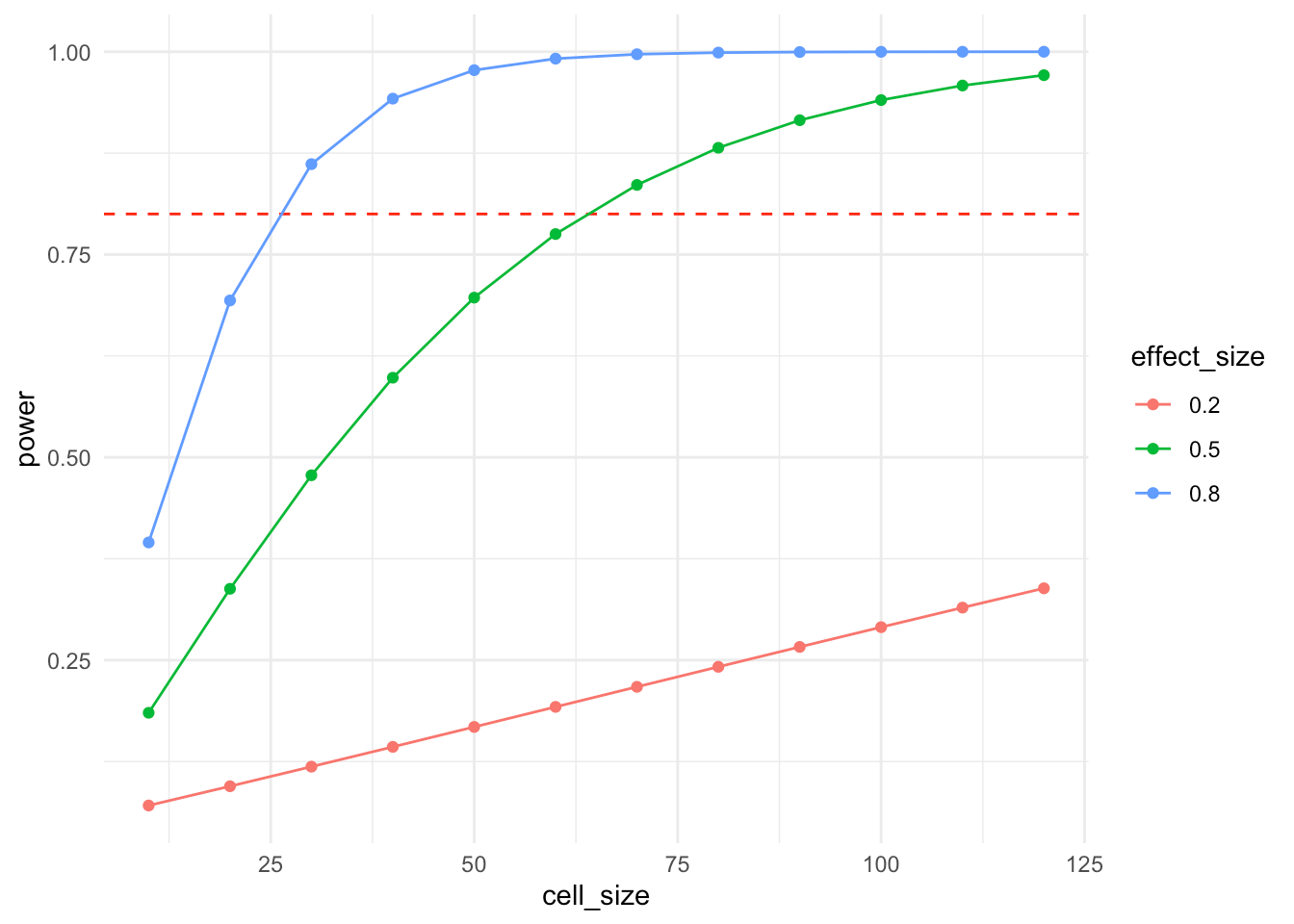
Acum, având în vedere că există funcții de putere pentru multe proiecte de teste standard, care este rostul puterii de a suferi din simulări? Răspunsul este că acestea sunt mai flexibile și ne permit să încorporăm detalii despre designul nostru experimental pe care funcțiile de putere nu sunt în măsură să le capteze. În cazul nostru de mai sus, avem o variabilă dependentă non-distribuită în mod normal. Să comparăm curba de putere bazată pe funcții cu cea derivată din simulări. Pentru a verifica dacă în principiu ambele metode dau aceeași curbă de putere, adăugăm și o altă simulare de putere care folosește o variabilă dependentă în mod normal distribuită.
function_power_est <- bind_rows(lapply(
seq(10, 120, by = 10),
function(x) my_power_fct(cell_size = x) %>%
mutate(method = "function")
))
mc_sim_power <- function(effect_size = 0.5, cell_size = 100, runs = 1000) {
bind_rows(
bind_rows(
replicate(runs, sim_run(effect_size, cell_size), simplify = F)
) %>%
group_by(effect_size, cell_size) %>%
summarise(power = mean(lb > 0), .groups = "drop")
)
}
sim_power_est_d100 <- bind_rows(lapply(
seq(10, 120, by = 10),
function(x) mc_sim_power(cell_size = x) %>%
mutate(method = "simulation_d100")
))
sim_data <- function(n = 100, mean = 50, sd = 20) {
tibble(y = rnorm(n, mean, sd))
}
sim_power_est_norm <- bind_rows(lapply(
seq(10, 120, by = 10),
function(x) mc_sim_power(cell_size = x) %>%
mutate(method = "simulation_norm")
))
df <- bind_rows(function_power_est, sim_power_est_d100, sim_power_est_norm)
ggplot(df, aes(x = cell_size, y = power, color = method)) +
geom_hline(yintercept = 0.8, lty = 2, color = "red") +
geom_line() + geom_point() +
theme_minimal() +
theme(legend.position = "bottom")
![]()
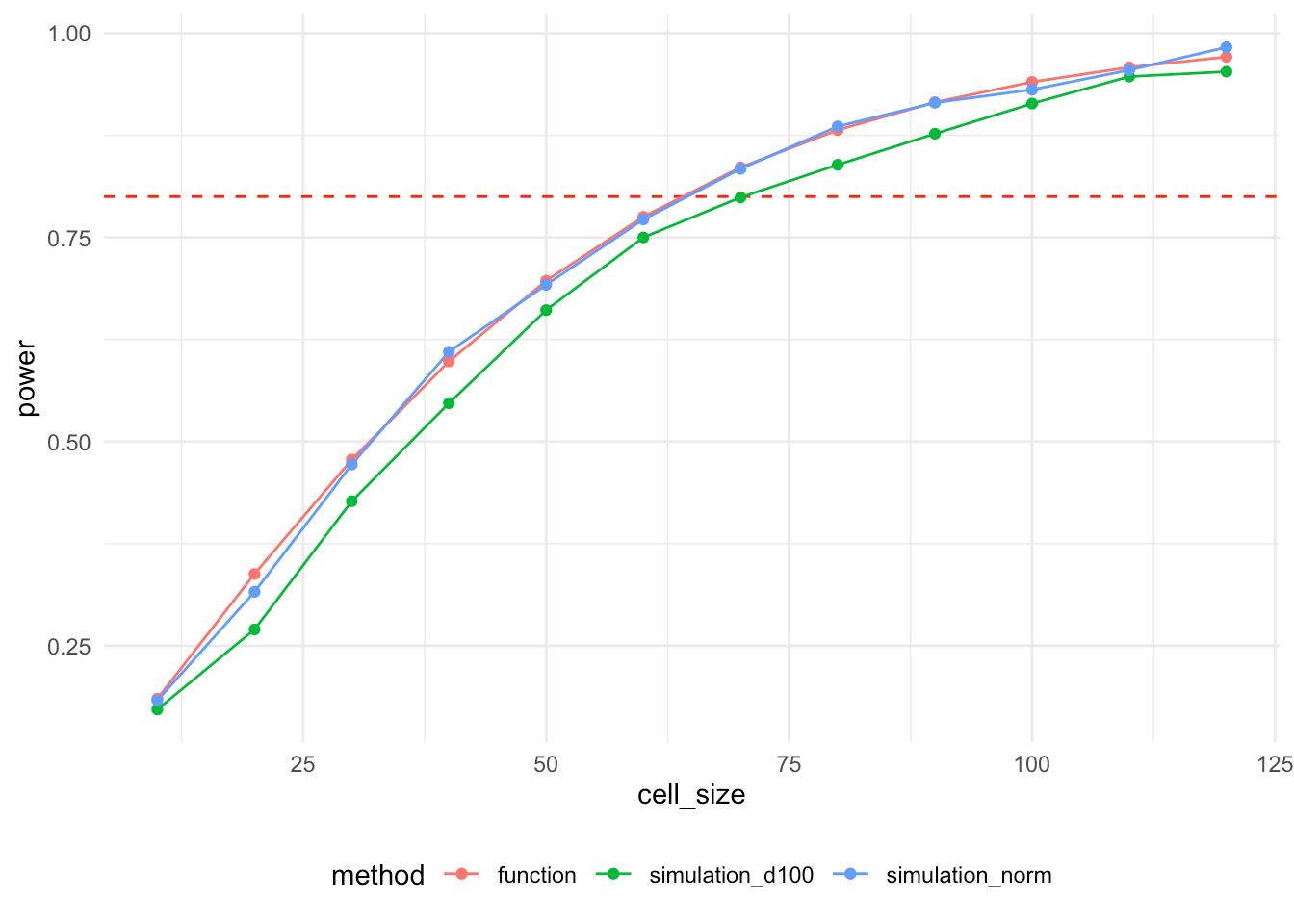
După cum vedeți, simularea folosind o variabilă dependentă în mod normal distribuită produce o curbă de putere care este practic identică cu curba de putere bazată pe funcții. Simularea inițială produce valori de putere marginal mai mici. Acest lucru este cauzat de trunchierea variabilei dependente să fie în termen de 0 și 100. După cum puteți vedea, de asemenea, din distribuția estimată de mai sus, această trunchiere afectează observațiile tratate (medie = 60) mai mult decât observațiile de control (media = 50), reducând marginal puterea și părtinirea ușoară a măsurii mărimii efectului în jos. Acesta este un bun exemplu pentru motivul pentru care simulările sunt utile în etapa de proiectare experimentală. Acestea nu numai că vă permit să estimați puterea, dar pot ajuta, de asemenea, să detectați alte probleme de proiectare pe care poate doriți să le abordați înainte de a vă desfășura designul.