În această postare, vreau să descriu unul dintre cele mai importante aspecte ale modelării riscurilor de credit și să explic cum apare și în multe alte domenii.
Postări anterioare din această serie: paradoxuri în riscul de credit I: Simpson’s Paradox
În modelarea riscului de credit, doriți să calculați probabilitatea ca un împrumut să fie implicit. Deoarece diferite instituții financiare adună date diferite și oferă produse diferite, nu există o abordare unică pentru a face acest lucru. Prin urmare, modelele de risc de credit sunt de obicei construite folosind propriile date ale instituției. De exemplu, dacă construiesc un model de risc de credit pentru XYZ Bank, mă uit la împrumuturi pe care XYZ Bank le -a acordat anterior și încerc să estimez probabilitatea ca un împrumut viitor să fie implicit pe baza principalului, tenorului, ratingului de credit al împrumutatului și așa mai departe.
Pentru cei care nu au mai auzit de problema prin ușă înainte, acesta este un moment bun pentru a face o pauză și gândirea la ceea ce nu este în regulă. De ce acest proces conține o capcană uriașă?
Două populații diferite
Desigur, există problema derivării datelor. Datele viitoare nu vor arăta ca datele anterioare și, ca întotdeauna, modelele se vor degrada în timp. Dar există o problemă și mai proastă.
Doriți să aplicați modelul tuturor viitorilor clienți care aplicați pentru un împrumut. Dar puteți construi modelul doar pe clienții care au fost de fapt acordate un împrumut. Nu aveți informații despre dacă persoanele a căror cerere de împrumut a fost refuzată ar fi fost implicită sau nu! Cu alte cuvinte, doriți să aplicați modelul populației tuturor persoanelor care vin „prin ușa” băncii, dar aveți doar date despre persoanele care au fost considerate riscuri de credit bune. De aici și numele „prin problema ușii”.
Exemplu
Doar pentru a ilustra ce se poate întâmpla, să presupunem că vrem să construim un model de notare a creditului cu amănuntul și avem un set de date cu o caracteristică numerică x1 (care ar putea fi o versiune transformată a ceva asemănător vârstei) și o caracteristică categorică x2 (ceea ce ar putea fi ceva de genul dacă persoana s -a mai dedicat înainte). Luați în considerare două alternative, una în care avem acces la toate datele și una în care aplicăm un scor care respinge toți solicitanții x1 + x2 > 0 Și avem doar date pentru solicitanții care nu au fost respinși.
set.seed(100)
logit <- function(x) 1/(1+exp(-x))
simulate_data <- function(n){
x1 <- rnorm(n)/2 # continuous feature
x2 <- rep(c(1, 0), n)(1:n) # categorical feature
PD <- logit(-3 + x1 + x2) # true PD
y <- rbinom(1000, 1, prob=PD) # simulated defaults
data.frame(cbind(x1, x2, y))
}
# simulated data
dat <- simulate_data(1000)
Construiți două modele, unul pe un eșantion nepărtinitor și unul pe un eșantion prin ușă.
# logistic regression based on part of full data set model <- glm(y ~. , data=dat(1:250, ), family="binomial") # censored data, assuming all applications with x1 + x2 >= 0 rejected thresh <- 0 ttd <- dat(dat$x1 + dat$x2 < thresh, ) # model built on through-the-door data model_ttd <- glm(y ~. , data=ttd, family="binomial")
Este obișnuit să utilizați ASC pentru a compara modelele, deoarece este mai important să aveți un clasament de împrumuturi, mai degrabă decât o estimare directă a probabilității de neplată. Iată curbele ROC ale celor două modele.
library(ROCR)
pred_model <- prediction(pred, dat_test$y)
perf <- performance(pred_model,"tpr","fpr")
png("roc_curves_ttd.png", width=500, height=500)
plot((email protected)((1)), (email protected)((1)), "l",
xlab="fpr", ylab="tpr", las=1)
pred_model_ttd <- prediction(pred_ttd, dat_test$y)
perf_ttd <- performance(pred_model_ttd,"tpr","fpr")
lines((email protected)((1)), (email protected)((1)), col="red")
legend("topleft", lty=c(1,1), col=c("black", "red"), legend=c("full sample",
"ttd sample"))
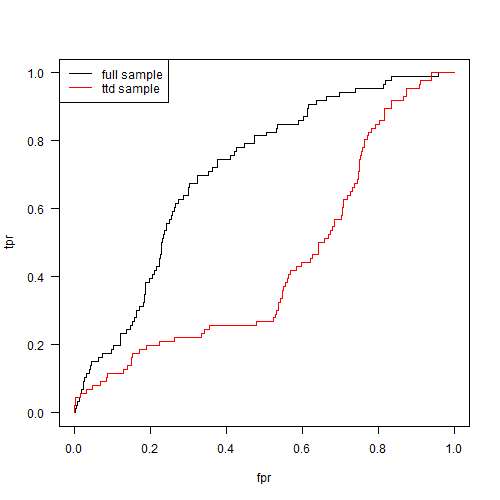
În mod clar, performanța modelului se degradează atunci când este montat la eșantionul prin ușă. Rețineți că acest lucru nu se întâmplă întotdeauna. Iată câteva curbe ROC pe care le obținem rulând întregul proces cu câteva semințe aleatorii diferite.

Modelarii de risc de credit au dezvoltat o familie de tehnici și reguli de deget numite numite respinge inferența pentru a face față acestor probleme. Mai aveți date despre solicitanții de împrumuturi respinse, deci cea mai de bază idee este să presupuneți că toți acei solicitanți au fost impliciti.
În exemplul nostru, putem arunca un eșantion de 100 de solicitanți de împrumut respins, presupunem că toate sunt implicite și le adăugăm la ttd set de date.
u <- dat(sample(which(dat$x1 + dat$x2 >= thresh), 100),) u$y <- 1 ttd2 <- rbind(ttd, u) # model with reject inference model_ttd2 <- glm(y ~. , data=ttd2, family="binomial")
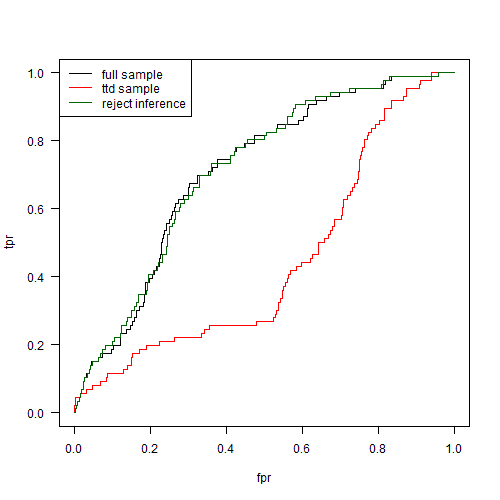
În acest exemplu simplu, acest lucru rezolvă problema. Viața reală este mai complicată, desigur, și există diverse abordări pentru a respinge inferența. Cel mai puțin rentabil este doar aprobarea automată a unora aleatoriu-Cset subset de împrumuturi pentru a obține un set de date nepărtinitor care nu suferă de probleme de respingere. Desigur, acest lucru înseamnă că ajungeți să aprobați câțiva debitori răi, care pot fi costisitoare pe termen lung.
Există și alte versiuni ale problemei prin ușă. Un exemplu amuzant sunt datele antice de risc de credit. Conform prețului timpului de către Edward Chancellor, împrumuturile babiloniene au fost înregistrate pe tablete de lut care au fost distruse atunci când împrumutul a fost rambursat complet. Prin urmare, dacă încercați să construiți un scor de credit pentru Babilonul Antic, setul dvs. de date ar consta în întregime din implicit!
Ce zici de aplicații în afara riscului de credit? Ei bine, surprinzător, acest lucru apare destul de des. O întrebare recentă privind încrucișarea se întreabă despre inspecțiile de sănătate. Un inspector de sănătate dorește să adune date despre restaurante, dar dorește să găsească restaurante care probabil că încalcă regulile de sănătate. În mod firesc, acest lucru duce la un set de date care este părtinitor față de restaurante care sunt probabil violatorilor. Aceasta este exact ca problema prin ușă, cu excepția faptului că datele de instruire pentru modelul dvs. de inspecție a sănătății vor fi părtinitoare către „rău”, mai degrabă decât „bunuri”. Puteți construi un model de învățare automată pe aceste date, dar atunci când încercați să aplicați modelul dvs. în lumea reală, s -ar putea să obțineți o surpriză urâtă!
De fapt, acest lucru se întâmplă tot timpul și este un motiv esențial pentru care multe modele predictive nu reușesc. Este întotdeauna important să înțelegem exact cum au fost colectate datele. Dacă datele de instruire și testare nu provin din aceeași populație, atunci estimările performanței modelului vor fi greșite. Și (cu excepția cazului în care sunteți pe Kaggle) datele de instruire și testare nu provin din aceeași populație. Acesta este un motiv pentru care prefer să evaluez modelele pe eșantioane în afara timpului, mai degrabă decât să mă bazez pe validare încrucișată!