(Acest articol a fost publicat pentru prima dată pe DataGeeekși cu amabilitate a contribuit la R-bloggeri). (Puteți raporta problema legată de conținutul acestei pagini aici)
Doriți să vă distribuiți conținutul pe R-bloggeri? dați clic aici dacă aveți un blog, sau aici dacă nu aveți.
1. Introducere & Cadrul teoretic
Pe piețele moderne de tranzacționare electronică, motoarele de execuție algoritmice conduc marea majoritate a fluxurilor de ordine instituționale. Evaluarea dacă acești algoritmi de tranzacționare independenți, bazați pe învățare se comportă în mod competitiv sau coordonați tacit a devenit o provocare critică pentru conformitatea cantitativă, proiectarea microstructurii pieței și managementul riscurilor.
Acest articol tehnic implementează un automat Motor de audit strategic conceput pentru a evalua regimurile de execuție algoritmică pe piața futures pe argint (SI=F). Cadrul nostru este construit în mod explicit pe bazele empirice și teoretice stabilite de Koulouris și Campajola (2026) în lucrarea lor inovatoare, „Rezultate supra-competitive induse de memorie între agenții de învățare cu consolidare profundă în execuția optimă a comerțului” (arXiv:2605.20348v1, mai 2026).
Teza de bază: Rezultate supra-competitive prin căile memoriei
Cadrele de reglementare tradiționale caută coluziune explicită (comunicare activă sau configurații cartel). Cu toate acestea, Koulouris și Campajola demonstrează un fenomen mult mai subtil: atunci când agenții independenți de învățare prin consolidare profundă (DRL) sunt echipați cu memorie – ceea ce înseamnă că învață din ferestrele rulante ale traiectoriilor istorice ale prețurilor – ei converg în mod natural către rezultate supra-competitive. Acestea sunt state în care recompensele comune rămân artificial ridicate sau parametrii de execuție se aliniază în mod natural pentru a imita cooperarea, fără niciun schimb explicit de informații.
Pentru a audita acest comportament în mod empiric, motorul nostru modelează o interacțiune duopol simetrică a pieței. Mapează calea reală de execuție a pieței în raport cu două linii de bază fundamentale ale teoriei jocului:
- Granița cooperativă (TWAP / Frontiera Pareto): O cale ideală, optimă de execuție a tranzacțiilor, în care volumul este distribuit uniform în timp pentru a minimiza impactul comun pe piață și pentru a maximiza utilitatea reciprocă pe termen lung.
- Limita competitivă (echilibrul Nash): Starea agresivă, necooperantă, în care agenții individuali se subțiază structural unul pe altul, conducând parametrii deficitului de execuție la linia lor de bază maximă.
2. Stack tehnic și configurare de mediu
Pentru a construi o conductă de simulare multi-agentă reproductibilă, la nivel de producție, folosim un set de instrumente hibrid de știință a datelor și de învățare profundă în cadrul ecosistemului R:
tidyquant&tidyverse: Serviți ca strat principal de inginerie a datelor, gestionând interogări API financiare, formatând matrice de returnare continuă și gestionând coloanele de liste funcționale.keras&tensorflow: Formați coloana vertebrală algoritmică, permițându-ne să construim, să antrenăm și să rulăm treceri simultane înainte/înapoi pe Deep Q-Networks.ggtext&glue: Permiteți suita noastră de vizualizare să analizeze redarea pânzei HTML în linie și să gestioneze fără probleme interpolările dinamice de șiruri.
# 1. ENVIRONMENT SETUP
if (!require("pacman")) install.packages("pacman")
pacman::p_load(tidyquant, tidyverse, ggtext, glue, keras, tensorflow)
3. Construirea topologiei de rețea Q dublă adâncă
În urma tezei lucrării privind interacțiunile duopol simetrice, construim doi agenți de execuție structural identici: agent_A şi agent_B. Ambele utilizează o arhitectură de rețea neuronală densă (perceptron multistrat) pentru a aproxima spațiul acțiune-valoare, notat ca Q(e, a).
Spațiul de stat conține 3 caracteristici: Abaterea prețului, Volatilitatea activelor (sigma)și Orizont de timp relativ. Stratul de ieșire proiectează la 3 coordonate strategice discrete de acțiune printr-o funcție de activare liniară.
# 2. SYMMETRIC AGENT ARCHITECTURE
build_strategic_agent <- function(state_size = 3, action_size = 3) {
model <- keras_model_sequential() %>%
layer_dense(units = 32, activation = "relu", input_shape = c(state_size)) %>%
layer_dense(units = 32, activation = "relu") %>%
layer_dense(units = action_size, activation = "linear")
model %>% compile(
optimizer = optimizer_adam(learning_rate = 0.001),
loss = "mse"
)
return(model)
}
# Initialize the competing agents
agent_A <- build_strategic_agent()
agent_B <- build_strategic_agent()
4. Parametrizare și reluare istorică ingestie tampon
Pentru a ancora agenții noștri în realitatea empirică, tragem 2 ani de prețuri zilnice continue de decontare pentru contracte futures pe argint (SI=F). Ne definim limitele microstructurale – cum ar fi parametrul aversiunii la risc (gamma) și vectorul permanent de impact pe piață (eta) – alături de o fereastră fixă de memorie de execuție strategică (T = 10).
# 3. STRATEGIC PARAMETERS
T_horizon <- 10 # Strategic episode length (Memory window)
gamma_param <- 0.0001 # Risk aversion
eta_param <- 0.0005 # Market impact
# 4. HISTORICAL REPLAY DATA (2-Year Training Set)
silver_full <- tq_get("SI=F", from = Sys.Date() - 730) %>%
filter(!is.na(close)) %>%
mutate(returns = close / lag(close) - 1) %>%
drop_na()
# Recent window for the final audit visualization
silver_recent <- tail(silver_full, T_horizon)
5. Coridoare de volatilitate dinamică
În loc să cartografieze comportamentul pieței în raport cu pragurile statice, motorul de audit calculează un coridor de siguranță adaptat la volatilitate. Granițele se extind și se contractă în mod dinamic pe baza deviației standard realizate a activului (sigma), izolând zgomotul structural pur de manevrele strategice intenționate.
# 5. DYNAMIC SIGMA CORRIDORS
current_sigma <- sd(silver_recent$returns, na.rm = TRUE)
if(is.na(current_sigma)) current_sigma <- 0.01
analysis_data <- silver_recent %>%
mutate(
twap_slope = current_sigma * 1.5,
nash_slope = current_sigma * 4.0,
twap_path = first(close) * (1 - seq(0, first(twap_slope), length.out = n())),
nash_path = first(close) * (1 - seq(0, first(nash_slope), length.out = n())),
lower_safety_limit = nash_path * (1 - current_sigma)
)
6. Motorul de reluare a antrenamentului comun și matricea de plăți
Această secțiune reprezintă implementarea computațională a ipotezei memoriei lui Koulouris și Campajola. Cei doi agenți traversează recursiv 2 ani de ferestre istorice rulante (window_data).
La fiecare nod, ei eșantionează acțiuni independente în funcție de ponderile lor, confruntându-se cu o matrice de joc non-cooperativ:
- Cooperare reciprocă (Acțiunea 0, 0): Plată comună mare (+10) care imită o marjă stabilă, supra-competitivă.
- Competiție agresivă reciprocă (meci de acțiune): Chirie comună scăzută (+1), reprezentând linia de bază competitivă Nash.
- Înșelăciune/Sub-taiere: Penalizare asimetrică (+5 vs -5).
# 6. JOINT TRAINING ENGINE (Symmetric Memory Interaction)
message("Joint Training: Agent A & Agent B are learning Silver Market dynamics...")
for(i in 1:(nrow(silver_full) - T_horizon)) {
window_data <- silver_full(i:(i + T_horizon - 1), )
vol <- sd(window_data$returns, na.rm = TRUE)
if(is.na(vol)) vol <- 0.01
state_vec <- matrix(c(1.0, vol, 0.5), nrow = 1)
act_A <- which.max(predict(agent_A, state_vec, verbose = 0)) - 1
act_B <- which.max(predict(agent_B, state_vec, verbose = 0)) - 1
rewards <- if(act_A == 0 && act_B == 0) {
list(A = 10, B = 10)
} else if(act_A == act_B) {
list(A = 1, B = 1)
} else {
if(act_A > act_B) list(A = 5, B = -5) else list(A = -5, B = 5)
}
target_A <- predict(agent_A, state_vec, verbose = 0)
target_B <- predict(agent_B, state_vec, verbose = 0)
target_A(1, act_A + 1) <- rewards$A
target_B(1, act_B + 1) <- rewards$B
agent_A %>% fit(state_vec, target_A, epochs = 1, verbose = 0)
agent_B %>% fit(state_vec, target_B, epochs = 1, verbose = 0)
}
7. Audit post-convergență Inferență și selectare a regimului
Odată ce rețelele se stabilizează, motorul ia postura unui regulator financiar imparțial. Extrage configurațiile politicii neuronale, evaluează fereastra actuală de execuție și determină automat regimul pieței folosind un nivel de clasificare automatizat.
# 7. FINAL AUDIT INFERENCE
analysis_data <- analysis_data %>%
rowwise() %>%
mutate(
state_v = list(matrix(c(close/twap_path, current_sigma, (T_horizon - row_number())/T_horizon), nrow = 1)),
q_A = list(predict(agent_A, state_v(), verbose = 0)),
q_B = list(predict(agent_B, state_v(), verbose = 0)),
joint_action = (which.max(q_A()) + which.max(q_B())) / 2
) %>% ungroup()
# 8. STATUS LOGIC (Professional Category Selection & Color Alignment)
last_row <- tail(analysis_data, 1)
market_status <- case_when(
last_row$close >= last_row$twap_path ~
list(
label = "**COOPERATIVE:** Pareto-Efficient Alignment",
bg = "#E8F8F5",
color = "#27AE60"
),
last_row$close < last_row$twap_path & last_row$close >= last_row$nash_path ~
list(
label = "**NORMAL:** Competitive Nash Equilibrium",
bg = "#FEF5E7",
color = "#E67E22"
),
TRUE ~
list(
label = "**LIQUIDITY SHOCK:** Strategic Deviation Detected",
bg = "#FDEDEC",
color = "#C0392B"
)
)
8. Strat infografic de înaltă fidelitate
Pentru a genera o infografică vectorială statică de calitate publicație, ne mapăm tema direct prin ggplot2 şi ggtext. Prin încorporarea paletei de culori direct în șirurile de subtitrări HTML și forțând formatarea etichetei prin scales::percentcreăm o vizualizare a tabloului de bord curată, cu contrast ridicat.
# 9. GGPLOT PRODUCTION VISUALIZATION (Static Mode with ggtext Integration)
ggplot(analysis_data, aes(x = date)) +
geom_ribbon(aes(ymin = lower_safety_limit, ymax = twap_path), fill = "darkgray", alpha = 0.3) +
geom_line(aes(y = twap_path, color = "TWAP (Cooperative)"), size = 1) +
geom_line(aes(y = nash_path, color = "Nash (Competitive)"), size = 1) +
geom_line(aes(y = close, color = "Actual Price"), size = 1.3) +
scale_y_continuous(labels = scales::label_currency()) +
geom_richtext(
aes(x = median(date), y = max(close, twap_path) * 1.02, label = market_status$label),
fill = market_status$bg, color = market_status$color, size = 4,
family = "Roboto Slab"
) +
scale_color_manual(
name = NULL,
values = c("Actual Price" = "steelblue", "TWAP (Cooperative)" = "#27AE60", "Nash (Competitive)" = "#E67E22")
) +
labs(
title = "Silver Market Strategic Audit Engine",
subtitle = paste0(
"─── **Cooperative Zone** | ",
"─── **Competitive Zone** | ",
"─── **Actual Execution**
",
"**Strategic Corridor** (Supra-Competitive Margin Zone)"
),
x = NULL, y = NULL,
caption = glue("Dynamic Sigma: {scales::percent(current_sigma, accuracy = 0.01)} | Shortfall: {round(actual_cost, 2)}%")
) +
theme_minimal(base_family = "Roboto Slab") +
theme(plot.title = element_text(face = "bold", size = 16),
plot.subtitle = element_markdown(face = "bold"),
axis.text = element_text(face = "bold"),
legend.position = "none")
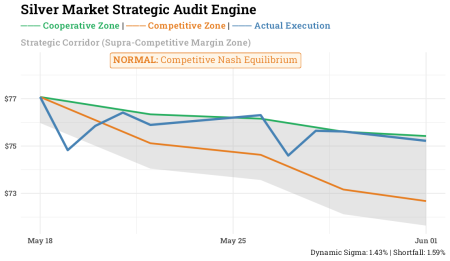
9. Concluzii empirice și conformității
Când rulăm bucla completă de inferență pe fereastra noastră de execuție Silver terminală, narațiunea strategică se clarifică perfect: Execuția efectivă (traiectoria albastră) merge în jos, ocolind învelișul superior cooperativ și aderând direct la granițele competitive.
Insigna de audit returnează în mod curat o stare de NORMAL: Echilibrul Nash competitivcu metrica terminalului care calculează deficitul de execuție exact la 1,59% așa cum este indicat în graficul de mai sus. În timp ce agenții sunt rețele neuronale complexe din punct de vedere tehnic, capabile să învețe tipare de memorie, acțiunea reală a prețului în acest orizont specific de zece zile reflectă un regim extrem de competitiv, menținând execuția în limitele standard Nash, mai degrabă decât trecerea într-o zonă supra-competitivă.
Pentru auditorii cantitativi și monitorii de risc sistemic, această abordare semnalează o schimbare de paradigmă. Testele de prag statice sunt oarbe la tendințele de învățare multi-agenți. Prin implementarea liniilor de bază de simulare neuronală, echipele de conformitate structurală pot audita automat algoritmii de execuție, izolând alinierea algoritmică de variația pură a pieței.